View source code | Read notebook in online book format
Introduction to TensorFlow, Deep Learning and Transfer Learning (work in progress)¶
- Project: Dog Vision 🐶👁 - Using computer vision to classify dog photos into different breeds.
- Goals: Learn TensorFlow, deep learning and transfer learning, beat the original research paper results (22% accuracy).
- Domain: Computer vision.
- Data: Images of dogs from Stanford Dogs Dataset (120 dog breeds, 20,000+ images).
- Problem type: Multi-class classification (120 different classes).
- Runtime: This project is designed to run end-to-end in Google Colab (for free GPU access and easy setup). If you'd like to run it locally, it will require environment setup.
- Demo: See a demo of the trained model running on Hugging Face Spaces.
Welcome, welcome!
The focus of this notebook is to give a quick overview of deep learning with TensorFlow/Keras.
How?
We're going to go through the machine learning workflow steps and build a computer vision project to classify photos of dogs into their respective dog breed (a Predictive AI task, see below for more).

What we're going to build: Dog Vision 🐶👁️, a neural network capable of identifying different dog breeds in images. All the way from dataset preparation to model building, training and evaluation.
# Quick timestamp
import datetime
print(f"Last updated: {datetime.datetime.now()}")
Last updated: 2024-04-26 01:26:48.838163
What we're going to cover¶
In this project, we're going to be introduced to the power of deep learning and more specifically, transfer learning using TensorFlow/Keras.
We'll go through each of these in the context of the 6 step machine learning framework:
- Problem defintion - Use computer vision to classify photos of dogs into different dog breeds.
- Data - 20,000+ images of dogs from 120 different dog breeds from the Stanford Dogs dataset.
- Evaluation - We'd like to beat the original paper's results (22% mean accuracy across all classes, tip: A good way to practice your skills is to find some results online and try to beat them).
- Features - Because we're using deep learning, our model will learn the features on its own.
- Modelling - We're going to use a pretrained convolutional neural network (CNN) and transfer learning.
- Experiments - We'll try different amounts of data with the same model to see the effects on our results.
Note: It's okay not to know these exact steps ahead of time. When starting a new project, it's often the case you'll figure it out as you go. These steps are only filled out because I've had practice working on several machine learning projects. You'll pick up these ideas overtime.
Table of contents¶
- Getting Setup
- Getting Data (dog images and their breeds)
- Exploring the data (exploratory data analysis)
- Creating training and test splits
- Turning our datasets into TensorFlow Dataset(s)
- Creating a neural network with TensorFlow
- Model 0 - Train a model on 10% of the training data
- Putting it all together: create, compile, fit
- Model 1 - Train a model on 100% of the training data
- Make and evaluate predictions of the best model
- Save and load the best model
- Make predictions on custom images with the best model (bringing Dog Vision 🐶👁️ to life!)
- Key takeaways
- Extensions & exercises
Where can can you get help?¶
All of the materials for this course are available on GitHub.
If you run into trouble, you can ask a question on the course GitHub Discussions page there too.
You can also:
Quick definitions¶
Let's start by breaking down some of the most important topics we're going to go through.
What is TensorFlow/Keras?¶
TensorFlow is an open source machine learning and deep learning framework originally developed by Google. Inside TensorFlow, you can also use Keras which is another very helpful machine learning framework known for its ease of use.
Why use TensorFlow?¶
TensorFlow allows you to manipulate data and write deep learning algorithms using Python code.
It also has several built-in capabilities to leverage accelerated computing hardware (e.g. GPUs, Graphics Processing Units and TPUs, Tensor Processing Units).
Many of world's largest companies power their machine learning workloads with TensorFlow.
What is deep learning?¶
Deep learning is a form of machine learning where data passes through a series of progressive layers which all contribute to learning an overall representation of that data.
Each layer performs a pre-defined operation.
The series of progressive layers combine to form what's referred to as a neural network.
For example, a photo may be turned into numbers (e.g. red, green and blue pixel values) and those numbers are then manipulated mathematically through each progressive layer to learn patterns in the photo.
The "deep" in deep learning comes from the number of layers used in the neural network.
So when someone says deep learning or (artificial neural networks), they're typically referring to same thing.
Note: Artificial intelligence (AI), machine learning (ML) and deep learning are all broad terms. You can think of AI as the overall technology, machine learning as a type of AI, and deep learning as a type of machine learning. So if someone refers to AI, you can often assume they are often talking about machine learning or deep learning.
What can deep learning be used for?¶
Deep learning is such a powerful technique that new use cases are being discovered everyday.
Most of the modern forms of artifical intelligence (AI) applications you see, are powered by deep learning.
Two of the most useful types of AI are predictive and generative.
Predictive AI learns the relationship between data and labels such as photos of dog and their breeds (supervised learning). So that when it sees a new photo of a dog, it can predict its breed based on what its learned.
Generative AI generates something new given an input such as creating new text given input text.
Some examples of Predictive AI problems include:
- Tesla's self-driving cars use deep learning use object detection models to power their computer vision systems.
- Apple's Photos app uses deep learning to recognize faces in images and create Photo Memories.
- Siri and Google Assistant use deep learning to transcribe speech and understand voice commands.
- Nutrify (an app my brother and I build) uses predictive AI to recognize food in images.
- Magika uses deep learning to classify a file into what type it is (e.g.
.jpeg,.py,.txt). - Text classification models such as DeBERTa use deep learning to classify text into different categories such as "positive" and "negative" or "spam" or "not spam".
Some examples of Generative AI problems include:
- Stable Diffusion uses generative AI to generate images given a text prompt.
- ChatGPT and other large language models (LLMs) such as Llama, Claude, Gemini and Mistral use deep learning to process text and return a response.
- GitHub Copilot uses generative AI to generate code snippets given surrounding context.
All of these AI use cases are powered by deep learning.
And more often than not, whenever you get started on a deep learning problem, you'll start with transfer learning.

Example of different every day problems where AI/machine learning gets used.
What is transfer learning?¶
Transfer learning is one of the most powerful and useful techniques in modern AI and machine learning.
It involves taking what one model (or neural network) has learned in a similar domain and applying to your own.
In our case, we're going to use transfer learning to take the patterns a neural network has learned from the 1 million+ images and over 1000 classes in ImageNet (a gold standard computer vision benchmark) and apply them to our own problem of recognizing dog breeds.
However, this concept can be applied to many different domains.
You could take a large language model (LLM) that has been pre-trained on most of the text on the internet and learned very well the patterns in naturual language and customize it for your own specific chat use-case.
The biggest benefit of transfer learning is that it often allows you to get outstanding results with less data and time.

A transfer learning workflow. Many publicly available models have been pretrained on large datasets such as ImageNet (1 million+ images). These models can then be applied to similar tasks downstream. For example, we can take a model pretrained on ImageNet and apply it to our Dog Vision 🐶👁️ problem. This same process can be repeated for many different styles of data and problem.
1. Getting setup¶
This notebook is designed to run in Google Colab, an online Jupyter Notebook that provides free access to GPUs (Graphics Processing Units, we'll hear more on these later).
For a quick rundown on how to use Google Colab, see their introductory guide (it's quite similar to a Jupyter Notebook with a few different options).
Google Colab also comes with many data science and machine learning libraries pre-installed, including TensorFlow/Keras.
Getting a GPU on Google Colab¶
Before running any code, we'll make sure our Google Colab instance is connected to a GPU.
You can do this via going to Runtime -> Change runtime type -> GPU (this may restart your existing runtime).
Why use a GPU?
Since neural networks perform a large amount of calculations behind the scenes (the main one being matrix multiplication), you need a computer chip that perform these calculations quickly, otherwise you'll be waiting all day for a model to train.
And in short, GPUs are much faster at performing matrix multiplications than CPUs.
Why this is the case is behind the scope of this project (you can search "why are GPUs faster than CPUs for machine learning?" for more).
The main thing to remember is: generally, in deep learning, GPUs = faster than CPUs.
Note: A good experiment would be to run the neural networks we're going to build later on with and without a GPU and see the difference in their training times.
Ok, enough talking, let's start by importing TensorFlow!
We'll do so using the common abbreviation tf.
import tensorflow as tf
tf.__version__
'2.15.0'
Nice!
Note: If you want to run TensorFlow locally, you can follow the TensorFlow installation guide.
Now let's check to see if TensorFlow has access to a GPU (this isn't 100% required to complete this project but will speed things up dramatically).
We can do so with the method tf.config.list_physical_devices().
# Do we have access to a GPU?
device_list = tf.config.list_physical_devices()
if "GPU" in [device.device_type for device in device_list]:
print(f"[INFO] TensorFlow has GPU available to use. Woohoo!! Computing will be sped up!")
print(f"[INFO] Accessible devices:\n{device_list}")
else:
print(f"[INFO] TensorFlow does not have GPU available to use. Models may take a while to train.")
print(f"[INFO] Accessible devices:\n{device_list}")
[INFO] TensorFlow has GPU available to use. Woohoo!! Computing will be sped up! [INFO] Accessible devices: [PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU'), PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
2. Getting Data¶
All machine learning (and deep learning) projects start with data.
If you have no data, you have no project.
If you have no project, you have no cool models to show your friends or improve your business.
Not to worry!
There are several options and locations to get data for a deep learning project.
| Resource | Description |
|---|---|
| Kaggle Datasets | A collection of datasets across a wide range of topics. |
| TensorFlow Datasets | A collection of ready-to-use machine learning datasets ready for use under the tf.data.Datasets API. You can see a list of all available datasets in the TensorFlow documentation. |
| Hugging Face Datasets | A continually growing resource of datasets broken into several different kinds of topics. |
| Google Dataset Search | A search engine by Google specifically focused on searching online datasets. |
| Original sources | Datasets which are made available by researchers or companies with the release of a product or research paper (sources for these will vary, they could be a link on a website or a link to an application form). |
| Custom datasets | These are datasets comprised of your own custom source of data. You may build these from scratch on your own or have access to them from an existing product or service. For example, your entire photos library could be your own custom dataset or your entire notes and documents folder or your company's customer order history. |
In our case, the dataset we're going to use is called the Stanford Dogs dataset (or ImageNet dogs, as the images are dogs separated from ImageNet).
Because the Stanford Dogs dataset has been around for a while (since 2011, which as of writing this in 2024 is like a lifetime in deep learning), it's available from several resources:
- The original project website via link download.
- Inside TensorFlow datasets under
stanford_dogs. - On Kaggle as a downloadable dataset.
The point here is that when you're starting out with practicing deep learning projects, there's no shortage of datasets available.
However, when you start wanting to work on your own projects or within a company environment, you'll likely start to work on custom datasets (datasets you build yourself or aren't available publicly online).
The main difference between existing datasets and custom datasets is that existing datasets often come preformatted and ready to use.
Where as custom datasets often require some preprocessing before they're ready to use within a machine learning project.
To practice formatting a dataset for a machine learning problem, we're going to download the Stanford Dogs dataset from the original website.
Before we do so, the following code is an example of how we'd get the Stanford Dogs dataset from TensorFlow Datasets.
# Download the dataset into train and test split using TensorFlow Datasets
# import tensorflow_datasets as tfds
# ds_train, ds_test = tfds.load('stanford_dogs', split=['train', 'test'])
Download data directly from Stanford Dogs website¶
Our overall project goal is to build a computer vision model which performs better than the original Stanford Dogs paper (average of 22% accuracy per class across 120 classes).
To do so, we need some data.
Let's download the original Stanford Dogs dataset from the project website.
The data comes in three main files:
- Images (757MB) -
images.tar - Annotations (21MB) -
annotation.tar - Lists with train/test splits (0.5MB) -
lists.tar
Our goal is to get a file structure like this:

Note: If you're using Google Colab for this project, remember that any data uploaded to the Google Colab session gets deleted if the session disconnects. So to save us redownloading the data every time, we're going to download it once and save it to Google Drive.
Resource: For a good guide on getting data in and out of Google Colab, see the Google Colab
io.ipynbtutorial.
To make sure we don't have to keep redownloading the data every time we leave and come back to Google Colab, we're going to:
- Download the data if it doesn't already exist on Google Drive.
- Copy it to Google Drive (because Google Colab connects nicely with Google Drive) if it isn't already there.
- If the data already exists on Google Drive (we've been through steps 1 & 2), we'll import it instead.
There are two main options to connect Google Colab instances to Google Drive:
- Click "Mount Drive" in "Files" menu on the left.
- Mount programmatically with
from google.colab import drive->drive.mount('/content/drive').
More specifically, we're going to follow the following steps:
- Mount Google Drive.
- Setup constants such as our base directory to save files to, the target files we'd like to download and target URL we'd like to download from.
- Setup our target local path to save to.
- Check if the target files all exist in Google Drive and if they do, copy them locally.
- If the target files don't exist in Google Drive, download them from the target URL with the
!wgetcommand. - Create a file on Google Drive to store the download files.
- Copy the downloaded files to Google Drive for use later if needed.
A fair few steps, but nothing we can't handle!
Plus, this is all good practice for dealing with and manipulating data, a very important skill in the machine learning engineers toolbox.
Note: The following data download section is designed to run in Google Colab. If you are running locally, feel free to modify the code to save to a local directory instead of Google Drive.
from pathlib import Path
from google.colab import drive
# 1. Mount Google Drive (this will bring up a pop-up to sign-in/authenticate)
# Note: This step is specifically for Google Colab, if you're working locally, you may need a different setup
drive.mount("/content/drive")
# 2. Setup constants
# Note: For constants like this, you'll often see them created as variables with all capitals
TARGET_DRIVE_PATH = Path("drive/MyDrive/tensorflow/dog_vision_data")
TARGET_FILES = ["images.tar", "annotation.tar", "lists.tar"]
TARGET_URL = "http://vision.stanford.edu/aditya86/ImageNetDogs"
# 3. Setup local path
local_dir = Path("dog_vision_data")
# 4. Check if the target files exist in Google Drive, if so, copy them to Google Colab
if all((TARGET_DRIVE_PATH / file).is_file() for file in TARGET_FILES):
print(f"[INFO] Copying Dog Vision files from Google Drive to local directory...")
print(f"[INFO] Source dir: {TARGET_DRIVE_PATH} -> Target dir: {local_dir}")
!cp -r {TARGET_DRIVE_PATH} .
print("[INFO] Good to go!")
else:
# 5. If the files don't exist in Google Drive, download them
print(f"[INFO] Target files not found in Google Drive.")
print(f"[INFO] Downloading the target files... this shouldn't take too long...")
for file in TARGET_FILES:
# wget is short for "world wide web get", as in "get a file from the web"
# -nc or --no-clobber = don't download files that already exist locally
# -P = save the target file to a specified prefix, in our case, local_dir
!wget -nc {TARGET_URL}/{file} -P {local_dir} # the "!" means to execute the command on the command line rather than in Python
print(f"[INFO] Saving the target files to Google Drive, so they can be loaded later...")
# 6. Ensure target directory in Google Drive exists
TARGET_DRIVE_PATH.mkdir(parents=True, exist_ok=True)
# 7. Copy downloaded files to Google Drive (so we can use them later and not have to re-download them)
!cp -r {local_dir}/* {TARGET_DRIVE_PATH}/
Mounted at /content/drive [INFO] Copying Dog Vision files from Google Drive to local directory... [INFO] Source dir: drive/MyDrive/tensorflow/dog_vision_data -> Target dir: dog_vision_data [INFO] Good to go!
Data downloaded!
Nice work! This may seem like a bit of work but it's an important step with any deep learning project. Getting data to work with.
Now if we get the contents of local_dir (dog_vision_data), what do we get?
We can first make sure it exists with Path.exists() and then we can iterate through its contents with Path.iterdir() and print out the .name attribute of each file.
if local_dir.exists():
print(str(local_dir) + "/")
for item in local_dir.iterdir():
print(" ", item.name)
dog_vision_data/ lists.tar images.tar annotation.tar
Excellent! That's exactly the format we wanted.
Now you might've noticed that each file ends in .tar.
What's this?
Searching "what is .tar?", I found:
In computing, tar is a computer software utility for collecting many files into one archive file, often referred to as a tarball, for distribution or backup purposes.
Source: Wikipedia tar page).
Exploring a bit more, I found that the .tar format is similar to .zip, however, .zip offers compression, where as .tar mostly combines many files into one.
So how do we "untar" the files in images.tar, annotation.tar and lists.tar?
We can use the !tar command (or just tar from outside of a Jupyter Cell)!
Doing this will expand all of the files within each of the .tar archives.
We'll also use a couple of flags to help us out:
- The
-xflag tellstarto extract files from an archive. - The
-fflag specifies that the following argument is the name of the archive file. - You can combine flags by putting them together
-xf.
Let's try it out!
# Untar images, notes/tags:
# -x = extract files from the zipped file
# -v = verbose
# -z = decompress files
# -f = tell tar which file to deal with
!tar -xf dog_vision_data/images.tar
!tar -xf dog_vision_data/annotation.tar
!tar -xf dog_vision_data/lists.tar
What new files did we get?
We can check in Google Colab by inspecting the "Files" tab on the left.
Or with Python by using os.listdir(".") where "." means "the current directory".
import os
os.listdir(".") # "." stands for "here" or "current directory"
['.config', 'dog_vision_data', 'file_list.mat', 'drive', 'train_list.mat', 'Images', 'Annotation', 'test_list.mat', 'sample_data']
Ooooh!
Looks like we've got some new files!
Specifically:
train_list.mat- a list of all the training set images.test_list.mat- a list of all the testing set images.Images/- a folder containing all of the images of dogs.Annotation/- a folder containing all of the annotations for each image.file_list.mat- a list of all the files (training and test list combined).
Our next step is to go through them and see what we've got.
3. Exploring the data¶
Once you've got a dataset, before building a model, it's wise to explore it for a bit to see what kind of data you're working with.
Exploring a dataset can mean many things.
But a few rules of thumb when exploring new data:
- View at least 100+ random samples for a "vibe check". For example, if you have a large dataset of images, randomly sample 10 images at a time and view them. Or if you have a large dataset of texts, what do some of them say? The same with audio. It will often be impossible to view all samples in your dataset, but you can start to get a good idea of what's inside by randomly inspecting samples.
- Visualize, viuslaize, visualize! This is the data explorer's motto. Use it often. As in, it's good to get statistics about your dataset but it's often even better to view 100s of samples with your own eyes (see the point above).
- Check the distributions and other various statistics. How many samples are there? If you're dealing with classification, how many classes and labels per class are there? Which classes don't you understand? If you don't have labels, investigate clustering methods to put similar samples close together.
As Abraham Lossfunction says...

A play on words of Abraham Lincoln's famous quote on sharpening an axe before cutting down a tree in theme of machine learning. Source: Daniel Bourke X/Twitter.
Our target data format¶
Since our goal is to build a computer vision model to classify dog breeds, we need a way to tell our model what breed of dog is in what image.
A common data format for a classification problem is to have samples stored in folders named after their class name.
For example:

In the case of dog images, we'd put all of the images labelled "chihuahua" in a folder called chihuahua/ (and so on for all the other classes and images).
We could split these folders so that training images go in train/chihuahua/ and testing images go in test/chihuahua/.
This is what we'll be working towards creating.
Note: This structure of folder format doesn't just work for only images, it can work for text, audio and other kind of classification data too.
Exploring the file lists¶
How about we check out the train_list.mat, test_list.mat and full_list.mat files?
Searching online, for "what is a .mat file?", I found that it's a MATLAB file. Before Python became the default language for machine learning and deep learning, many models and datasets were built in MATLAB.
Then I searched, "how to open a .mat file with Python?" and found an answer on Stack Overflow saying I could use the scipy library (a scientific computing library).
The good news is, Google Colab comes with scipy preinstalled.
We can use the scipy.io.loadmat() method to open a .mat file.
import scipy
# Open lists of train and test .mat
train_list = scipy.io.loadmat("train_list.mat")
test_list = scipy.io.loadmat("test_list.mat")
file_list = scipy.io.loadmat("file_list.mat")
# Let's inspect the output and type of the train_list
train_list, type(train_list)
({'__header__': b'MATLAB 5.0 MAT-file, Platform: GLNXA64, Created on: Sun Oct 9 08:36:13 2011',
'__version__': '1.0',
'__globals__': [],
'file_list': array([[array(['n02085620-Chihuahua/n02085620_5927.jpg'], dtype='<U38')],
[array(['n02085620-Chihuahua/n02085620_4441.jpg'], dtype='<U38')],
[array(['n02085620-Chihuahua/n02085620_1502.jpg'], dtype='<U38')],
...,
[array(['n02116738-African_hunting_dog/n02116738_6754.jpg'], dtype='<U48')],
[array(['n02116738-African_hunting_dog/n02116738_9333.jpg'], dtype='<U48')],
[array(['n02116738-African_hunting_dog/n02116738_2503.jpg'], dtype='<U48')]],
dtype=object),
'annotation_list': array([[array(['n02085620-Chihuahua/n02085620_5927'], dtype='<U34')],
[array(['n02085620-Chihuahua/n02085620_4441'], dtype='<U34')],
[array(['n02085620-Chihuahua/n02085620_1502'], dtype='<U34')],
...,
[array(['n02116738-African_hunting_dog/n02116738_6754'], dtype='<U44')],
[array(['n02116738-African_hunting_dog/n02116738_9333'], dtype='<U44')],
[array(['n02116738-African_hunting_dog/n02116738_2503'], dtype='<U44')]],
dtype=object),
'labels': array([[ 1],
[ 1],
[ 1],
...,
[120],
[120],
[120]], dtype=uint8)},
dict)
Okay, looks like we get a dictionary with several fields we may be interested in.
Let's check out the keys of the dictionary.
train_list.keys()
dict_keys(['__header__', '__version__', '__globals__', 'file_list', 'annotation_list', 'labels'])
My guess is that the file_list key is what we're after, as this looks like a large array of image names (the files all end in .jpg).
How about we see how many files are in each file_list key?
# Check the length of the file_list key
print(f"Number of files in training list: {len(train_list['file_list'])}")
print(f"Number of files in testing list: {len(test_list['file_list'])}")
print(f"Number of files in full list: {len(file_list['file_list'])}")
Number of files in training list: 12000 Number of files in testing list: 8580 Number of files in full list: 20580
Beautiful! Looks like these lists contain our training and test splits and the full list has a list of all the files in the dataset.
Let's inspect the train_list['file_list'] further.
train_list['file_list']
array([[array(['n02085620-Chihuahua/n02085620_5927.jpg'], dtype='<U38')],
[array(['n02085620-Chihuahua/n02085620_4441.jpg'], dtype='<U38')],
[array(['n02085620-Chihuahua/n02085620_1502.jpg'], dtype='<U38')],
...,
[array(['n02116738-African_hunting_dog/n02116738_6754.jpg'], dtype='<U48')],
[array(['n02116738-African_hunting_dog/n02116738_9333.jpg'], dtype='<U48')],
[array(['n02116738-African_hunting_dog/n02116738_2503.jpg'], dtype='<U48')]],
dtype=object)
Looks like we've got an array of arrays.
How about we turn them into a Python list for easier handling?
We can do so by extracting each individual item via indexing and list comprehension.
Let's see what it's like to get a single file name.
# Get a single filename
train_list['file_list'][0][0][0]
'n02085620-Chihuahua/n02085620_5927.jpg'
Now let's get a Python list of all the individual file names (e.g. n02097130-giant_schnauzer/n02097130_2866.jpg) so we can use them later.
# Get a Python list of all file names for each list
train_file_list = list([item[0][0] for item in train_list["file_list"]])
test_file_list = list([item[0][0] for item in test_list["file_list"]])
full_file_list = list([item[0][0] for item in file_list["file_list"]])
len(train_file_list), len(test_file_list), len(full_file_list)
(12000, 8580, 20580)
Wonderful!
How about we view a random sample of the filenames we extracted?
Note: One of my favourite things to do whilst exploring data is to continually view random samples of it. Whether it be file names or images or text snippets. Why? You can always view the first X number of samples, however, I find that continually viewing random samples of the data gives you a better of overview of the different kinds of data you're working with. It also gives you the small chance of stumbling upon a potential error.
We can view random samples of the data using Python's random.sample() method.
import random
random.sample(train_file_list, k=10)
['n02094258-Norwich_terrier/n02094258_439.jpg', 'n02113624-toy_poodle/n02113624_3624.jpg', 'n02102973-Irish_water_spaniel/n02102973_3635.jpg', 'n02102318-cocker_spaniel/n02102318_2048.jpg', 'n02098286-West_Highland_white_terrier/n02098286_1261.jpg', 'n02088238-basset/n02088238_10095.jpg', 'n02108915-French_bulldog/n02108915_9457.jpg', 'n02098286-West_Highland_white_terrier/n02098286_5979.jpg', 'n02109047-Great_Dane/n02109047_31274.jpg', 'n02095889-Sealyham_terrier/n02095889_760.jpg']
Now let's do a quick check to make sure none of the training image file names appear in the testing image file names list.
This is important because the number 1 rule in machine learning is: always keep the test set separate from the training set.
We can check that there are no overlaps by turning train_file_list into a Python set() and using the intersection() method.
# How many files in the training set intersect with the testing set?
len(set(train_file_list).intersection(test_file_list))
0
Excellent! Looks like there are no overlaps.
We could even put an assert check to raise an error if there are any overlaps (e.g. the length of the intersection is greater than 0).
assert works in the fashion: assert expression, message_if_expression_fails.
If the assert check doesn't output anything, we're good to go!
# Make an assertion statement to check there are no overlaps (try changing test_file_list to train_file_list to see how it works)
assert len(set(train_file_list).intersection(test_file_list)) == 0, "There are overlaps between the training and test set files, please check them."
Woohoo!
Looks like there's no overlaps, let's keep exploring the data.
Exploring the Annotation folder¶
How about we look at the Annotation folder next?
We can click the folder on the file explorer on the left to see what's inside.
But we can also explore the contents of the folder with Python.
Let's use os.listdir() to see what's inside.
os.listdir("Annotation")[:10]
['n02111129-Leonberg', 'n02102973-Irish_water_spaniel', 'n02110806-basenji', 'n02105251-briard', 'n02093991-Irish_terrier', 'n02099267-flat-coated_retriever', 'n02110627-affenpinscher', 'n02112137-chow', 'n02094114-Norfolk_terrier', 'n02095570-Lakeland_terrier']
Looks like there are files each with a dog breed name with several numbered files inside.
Each of the files contains a HTML version of an annotation relating to an image.
For example, Annotation/n02085620-Chihuahua/n02085620_10074:
<annotation>
<folder>02085620</folder>
<filename>n02085620_10074</filename>
<source>
<database>ImageNet database</database>
</source>
<size>
<width>333</width>
<height>500</height>
<depth>3</depth>
</size>
<segment>0</segment>
<object>
<name>Chihuahua</name>
<pose>Unspecified</pose>
<truncated>0</truncated>
<difficult>0</difficult>
<bndbox>
<xmin>25</xmin>
<ymin>10</ymin>
<xmax>276</xmax>
<ymax>498</ymax>
</bndbox>
</object>
</annotation>
The fields include the name of the image, the size of the image, the label of the object and where it is (bounding box coordinates).
If we were performing object detection (finding the location of a thing in an image), we'd pay attention to the <bndbox> coordinates.
However, since we're focused on classification, our main consideration is the mapping of image name to class name.
Since we're dealing with 120 classes of dog breed, let's write a function to check the number of subfolders in the Annotation directory (there should be 120 subfolders, one for each breed of dog).
To do so, we can use Python's pathlib.Path class, along with Path.iterdir() to loop over the contents of Annotation and Path.is_dir() to check if the target item is a directory.
from pathlib import Path
def count_subfolders(directory_path: str) -> int:
"""
Count the number of subfolders in a given directory.
Args:
directory_path (str): The path to the directory in which to count subfolders.
Returns:
int: The number of subfolders in the specified directory.
Examples:
>>> count_subfolders('/path/to/directory')
3 # if there are 3 subfolders in the specified directory
"""
return len([name for name in Path(directory_path).iterdir() if name.is_dir()])
directory_path = "Annotation"
folder_count = count_subfolders(directory_path)
print(f"Number of subfolders in {directory_path} directory: {folder_count}")
Number of subfolders in Annotation directory: 120
Perfect!
There are 120 subfolders of annotations, one for each class of dog we'd like to identify.
But on further inspection of our file lists, it looks like the class name is already in the filepath.
# View a single training file pathname
train_file_list[0]
'n02085620-Chihuahua/n02085620_5927.jpg'
With this information we know, that image n02085620_5927.jpg should contain a Chihuahua.
Let's check.
I searched "how to display an image in Google Colab" and found another answer on Stack Overflow.
Turns out you can use IPython.display.Image(), as Google Colab comes with IPython (Interactive Python) built-in.
from IPython.display import Image
Image(Path("Images", train_file_list[0]))

Woah!
We get an image of a dog!
Exploring the Images folder¶
We've explored the Annotations folder, now let's check out our Images folder.
We know that the image file names come in the format class_name/image_name, for example, n02085620-Chihuahua/n02085620_5927.jpg.
To make things a little simpler, let's create the following:
- A mapping from folder name -> class name in dictionary form, for example,
{'n02113712-miniature_poodle': 'miniature_poodle', 'n02092339-Weimaraner': 'weimaraner', 'n02093991-Irish_terrier': 'irish_terrier'...}. This will help us when visualizing our data from its original folder. - A list of all unique dog class names with simple formatting, for example,
['affenpinscher', 'afghan_hound', 'african_hunting_dog', 'airedale', 'american_staffordshire_terrier'...].
Let's start by getting a list of all the folders in the Images directory with os.listdir().
# Get a list of all image folders
image_folders = os.listdir("Images")
image_folders[:10]
['n02111129-Leonberg', 'n02102973-Irish_water_spaniel', 'n02110806-basenji', 'n02105251-briard', 'n02093991-Irish_terrier', 'n02099267-flat-coated_retriever', 'n02110627-affenpinscher', 'n02112137-chow', 'n02094114-Norfolk_terrier', 'n02095570-Lakeland_terrier']
Excellent!
Now let's make a dictionary which maps from the folder name to a simplified version of the class name, for example:
{'n02085782-Japanese_spaniel': 'japanese_spaniel',
'n02106662-German_shepherd': 'german_shepherd',
'n02093256-Staffordshire_bullterrier': 'staffordshire_bullterrier',
...}
# Create folder name -> class name dict
folder_to_class_name_dict = {}
for folder_name in image_folders:
# Turn folder name into class_name
# E.g. "n02089078-black-and-tan_coonhound" -> "black_and_tan_coonhound"
# We'll split on the first "-" and join the rest of the string with "_" and then lower it
class_name = "_".join(folder_name.split("-")[1:]).lower()
folder_to_class_name_dict[folder_name] = class_name
# Make sure there are 120 entries in the dictionary
assert len(folder_to_class_name_dict) == 120
Folder name to class name mapping created, let's view the first 10.
list(folder_to_class_name_dict.items())[:10]
[('n02111129-Leonberg', 'leonberg'),
('n02102973-Irish_water_spaniel', 'irish_water_spaniel'),
('n02110806-basenji', 'basenji'),
('n02105251-briard', 'briard'),
('n02093991-Irish_terrier', 'irish_terrier'),
('n02099267-flat-coated_retriever', 'flat_coated_retriever'),
('n02110627-affenpinscher', 'affenpinscher'),
('n02112137-chow', 'chow'),
('n02094114-Norfolk_terrier', 'norfolk_terrier'),
('n02095570-Lakeland_terrier', 'lakeland_terrier')]
And we can get a list of unique dog names by getting the values() of the folder_to_class_name_dict and turning it into a list.
dog_names = sorted(list(folder_to_class_name_dict.values()))
dog_names[:10]
['affenpinscher', 'afghan_hound', 'african_hunting_dog', 'airedale', 'american_staffordshire_terrier', 'appenzeller', 'australian_terrier', 'basenji', 'basset', 'beagle']
Perfect!
Now we've got:
folder_to_class_name_dict- a mapping from the folder name to the class name.dog_names- a list of all the unique dog breeds we're working with.
Visualize a group of random images¶
How about we follow the data explorers motto of visualize, visualize, visualize and view some random images?
To help us visualize, let's create a function that takes in a list of image paths and then randomly selects 10 of those paths to display.
The function will:
- Take in a select list of image paths.
- Create a grid of matplotlib plots (e.g. 2x5 = 10 plots to plot on).
- Randomly sample 10 image paths from the input image path list (using
random.sample()). - Iterate through the flattened axes via
axes.flatwhich is a reference to the attributenumpy.ndarray.flat. - Extract the sample path from the list of samples.
- Get the sample title from the parent folder of the path using
Path.parent.stemand then extract the formatted dog breed name by indexingfolder_to_class_name_dict. - Read the image with
plt.imread()and show it on the targetaxwithax.imshow(). - Set the title of the plot to the parent folder name with
ax.set_title()and turn the axis marks of withax.axis("off")(this makes for pretty plots). - Show the plot with
plt.show().
Woah!
A lot of steps! But nothing we can't handle, let's do it.
import random
from pathlib import Path
from typing import List
import matplotlib.pyplot as plt
# 1. Take in a select list of image paths
def plot_10_random_images_from_path_list(path_list: List[Path],
extract_title: bool=True) -> None:
# 2. Set up a grid of plots
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(20, 10))
# 3. Randomly sample 10 paths from the list
samples = random.sample(path_list, 10)
# 4. Iterate through the flattened axes and corresponding sample paths
for i, ax in enumerate(axes.flat):
# 5. Get the target sample path (e.g. "Images/n02087394-Rhodesian_ridgeback/n02087394_1161.jpg")
sample_path = samples[i]
# 6. Extract the parent directory name to use as the title (if necessary)
# (e.g. n02087394-Rhodesian_ridgeback/n02087394_1161.jpg -> n02087394-Rhodesian_ridgeback -> rhodesian_ridgeback)
if extract_title:
sample_title = folder_to_class_name_dict[sample_path.parent.stem]
else:
sample_title = sample_path.parent.stem
# 7. Read the image file and plot it on the corresponding axis
ax.imshow(plt.imread(sample_path))
# 8. Set the title of the axis and turn of the axis (for pretty plots)
ax.set_title(sample_title)
ax.axis("off")
# 9. Display the plot
plt.show()
plot_10_random_images_from_path_list(path_list=[Path("Images") / Path(file) for file in train_file_list])

Those are some nice looking dogs!
What I like to do here is rerun the random visualizations until I've seen 100+ samples so I've got an idea of the data we're working with.
Question: Here's something to think about, how would you code a system of rules to differentiate between all the different breeds of dogs? Perhaps you write an algorithm to look at the shapes or the colours? For example, if the dog had black fur, it's unlikely to be a golden retriever. You might be thinking "that would take quite a long time..." And you'd be right. Then how would we do it? With machine learning of course!
Exploring the distribution of our data¶
After visualization, another valuable way to explore the data is by checking the data distribution.
Distribution refers to the "spread" of data.
In our case, how many images of dogs do we have per breed?
A balanced distribution would mean having roughly the same number of images for each breed (e.g. 100 images per dog breed).
Note: There's a deeper level of distribution than just images per dog breed. Ideally, the images for each different breed are well distributed as well. For example, we wouldn't want to have 100 of the same image per dog breed. Not only would we like a similar number of images per breed, we'd like the images of each particular breed to be in different scenarios, different lighting, different angles. We want this because we want to our model to be able to recognize the correct dog breed no matter what angle the photo is taken from.
To figure out how many images we have per class, let's write a function count the number of images per subfolder in a given directory.
Specifically, we'll want the function to:
- Take in a target directory/folder.
- Create a list of all the subdirectories/subfolders in the target folder.
- Create an empty list,
image_class_countsto append subfolders and their counts to. - Iterate through all of the subdirectories.
- Get the class name of the target folder as the name of the folder.
- Count the number of images in the target folder using the length of the list of image paths (we can get these with
Path().rglob(*.jpg)where*.jpgmeans "all files with the extension.jpg. - Append a dictionary of
{"class_name": class_name, "image_count": image_count}to theimage_class_countslist (we create a list of dictionaries so we can turn this into a pandas DataFrame). - Return the
image_class_countslist.
# Create a dictionary of image counts
from pathlib import Path
from typing import List, Dict
# 1. Take in a target directory
def count_images_in_subdirs(target_directory: str) -> List[Dict[str, int]]:
"""
Counts the number of JPEG images in each subdirectory of the given directory.
Each subdirectory is assumed to represent a class, and the function counts
the number of '.jpg' files within each one. The result is a list of
dictionaries with the class name and corresponding image count.
Args:
target_directory (str): The path to the directory containing subdirectories.
Returns:
List[Dict[str, int]]: A list of dictionaries with 'class_name' and 'image_count' for each subdirectory.
Examples:
>>> count_images_in_subdirs('/path/to/directory')
[{'class_name': 'beagle', 'image_count': 50}, {'class_name': 'poodle', 'image_count': 60}]
"""
# 2. Create a list of all the subdirectoires in the target directory (these contain our images)
images_dir = Path(target_directory)
image_class_dirs = [directory for directory in images_dir.iterdir() if directory.is_dir()]
# 3. Create an empty list to append image counts to
image_class_counts = []
# 4. Iterate through all of the subdirectories
for image_class_dir in image_class_dirs:
# 5. Get the class name from image directory (e.g. "Images/n02116738-African_hunting_dog" -> "n02116738-African_hunting_dog")
class_name = image_class_dir.stem
# 6. Count the number of images in the target subdirectory
image_count = len(list(image_class_dir.rglob("*.jpg"))) # get length all files with .jpg file extension
# 7. Append a dictionary of class name and image count to count list
image_class_counts.append({"class_name": class_name,
"image_count": image_count})
# 8. Return the list
return image_class_counts
Ho ho, what a function!
Let's run it on our target directory Images and view the first few indexes.
image_class_counts = count_images_in_subdirs("Images")
image_class_counts[:3]
[{'class_name': 'n02111129-Leonberg', 'image_count': 210},
{'class_name': 'n02102973-Irish_water_spaniel', 'image_count': 150},
{'class_name': 'n02110806-basenji', 'image_count': 209}]
Nice!
Since our image_class_counts variable is the form of a list of dictionaries, we can turn it into a pandas DataFrame.
Let's sort the DataFrame by "image_count" so the classes with the most images appear at the top, we can do so with DataFrame.sort_values().
# Create a DataFrame
import pandas as pd
image_counts_df = pd.DataFrame(image_class_counts).sort_values(by="image_count", ascending=False)
image_counts_df.head()
| class_name | image_count | |
|---|---|---|
| 116 | n02085936-Maltese_dog | 252 |
| 53 | n02088094-Afghan_hound | 239 |
| 111 | n02092002-Scottish_deerhound | 232 |
| 103 | n02112018-Pomeranian | 219 |
| 54 | n02107683-Bernese_mountain_dog | 218 |
And let's cleanup the "class_name" column to be more readable by mapping the the values to our folder_to_class_name_dict.
# Make class name column easier to read
image_counts_df["class_name"] = image_counts_df["class_name"].map(folder_to_class_name_dict)
image_counts_df.head()
| class_name | image_count | |
|---|---|---|
| 116 | maltese_dog | 252 |
| 53 | afghan_hound | 239 |
| 111 | scottish_deerhound | 232 |
| 103 | pomeranian | 219 |
| 54 | bernese_mountain_dog | 218 |
Now we've got a DataFrame of image counts per class, we can make them more visual by turning them into a plot.
We covered plotting data directly from pandas DataFrame's in Section 3 of the Introduction to Matplotlib notebook: Plotting data directly with pandas.
To do so, we can use image_counts_df.plot(kind="bar", ...) along with some other customization.
# Turn the image counts DataFrame into a graph
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 7))
image_counts_df.plot(kind="bar",
x="class_name",
y="image_count",
legend=False,
ax=plt.gca()) # plt.gca() = "get current axis", get the plt we setup above and put the data there
# Add customization
plt.ylabel("Image Count")
plt.title("Total Image Counts by Class")
plt.xticks(rotation=90, # Rotate the x labels for better visibility
fontsize=8) # Make the font size smaller for easier reading
plt.tight_layout() # Ensure things fit nicely
plt.show()

Beautiful! It looks like our classes are quite balanced. Each breed of dog has ~150 or more images.
We can find out some other quick stats about our data with DataFrame.describe().
# Get various statistics about our data distribution
image_counts_df.describe()
| image_count | |
|---|---|
| count | 120.000000 |
| mean | 171.500000 |
| std | 23.220898 |
| min | 148.000000 |
| 25% | 152.750000 |
| 50% | 159.500000 |
| 75% | 186.250000 |
| max | 252.000000 |
And the table shows a similar story to the plot. We can see the minimum number of images per class is 148, where as the maximum number of images is 252.
If one class had 10x less images than another class, we may look into collecting more data to improve the balance.
The main takeaway(s):
- When working on a classification problem, ideally, all classes have a similar number of samples (however, in some problems this may be unattainable, such as fraud detection, where you may have 1000x more "not fraud" samples to "fraud" samples.
- If you wanted to add a new class of dog breed to the existing 120, ideally, you'd have at least ~150 images for it (though as we'll see with transfer learning, the number of required images could be less as long as they're high quality).
4. Creating training and test data split directories¶
After exploring the data, one of the next best things you can do is create experimental data splits.
This includes:
| Set Name | Description | Typical Percentage of Data |
|---|---|---|
| Training Set | A dataset for the model to learn on | 70-80% |
| Testing Set | A dataset for the model to be evaluated on | 20-30% |
| (Optional) Validation Set | A dataset to tune the model on | 50% of the test data |
| (Optional) Smaller Training Set | A smaller size dataset to run quick experiments on | 5-20% of the training set |
Our dog dataset already comes with specified training and test set splits.
So we'll stick with those.
But we'll also create a smaller training set (a random 10% of the training data) so we can stick to the machine learning engineers motto of experiment, experiment, experiment! and run quicker experiments.
Note: One of the most important things in machine learning is being able to experiment quickly. As in, try a new model, try a new set of hyperparameters or try a new training setup. When you start out, you want the time between your experiments to be as small as possible so you can quickly figure out what doesn't work so you can spend more time on and run larger experiments with what does work.
As previously discussed, we're working towards a directory structure of:
images_split/
├── train/
│ ├── class_1/
│ │ ├── train_image1.jpg
│ │ ├── train_image2.jpg
│ │ └── ...
│ ├── class_2/
│ │ ├── train_image1.jpg
│ │ ├── train_image2.jpg
│ │ └── ...
└── test/
├── class_1/
│ ├── test_image1.jpg
│ ├── test_image2.jpg
│ └── ...
├── class_2/
│ ├── test_image1.jpg
│ ├── test_image2.jpg
...
So let's write some code to create:
images/train/directory to hold all of the training images.images/test/directory to hold all of the testing images.- Make a directory inside each of
images/train/andimages/test/for each of the dog breed classes.
We can make each of the directories we need using Path.mkdir().
For the dog breed directories, we'll loop through the list of dog_names and create a folder for each inside the images/train/ and images/test/ directories.
from pathlib import Path
# Define the target directory for image splits to go
images_split_dir = Path("images_split")
# Define the training and test directories
train_dir = images_split_dir / "train"
test_dir = images_split_dir / "test"
# Using Path.mkdir with exist_ok=True ensures the directory is created only if it doesn't exist
train_dir.mkdir(parents=True, exist_ok=True)
test_dir.mkdir(parents=True, exist_ok=True)
print(f"Directory {train_dir} is exists.")
print(f"Directory {test_dir} is exists.")
# Make a folder for each dog name
for dog_name in dog_names:
# Make training dir folder
train_class_dir = train_dir / dog_name
train_class_dir.mkdir(parents=True, exist_ok=True)
# print(f"Making directory: {train_class_dir}")
# Make testing dir folder
test_class_dir = test_dir / dog_name
test_class_dir.mkdir(parents=True, exist_ok=True)
# print(f"Making directory: {test_class_dir}")
# Make sure there is 120 subfolders in each
assert count_subfolders(train_dir) == len(dog_names)
assert count_subfolders(test_dir) == len(dog_names)
Directory images_split/train is exists. Directory images_split/test is exists.
Excellent!
We can check out the data split directories/folders we created by inspecting them in the files panel in Google Colab.
Alternatively, we can check the names of each by list the subdirectories inside them.
# See the first 10 directories in the training split dir
sorted([str(dir_name) for dir_name in train_dir.iterdir() if dir_name.is_dir()])[:10]
['images_split/train/affenpinscher', 'images_split/train/afghan_hound', 'images_split/train/african_hunting_dog', 'images_split/train/airedale', 'images_split/train/american_staffordshire_terrier', 'images_split/train/appenzeller', 'images_split/train/australian_terrier', 'images_split/train/basenji', 'images_split/train/basset', 'images_split/train/beagle']
You might've noticed that all of our dog breed directories are empty.
Let's change that by getting some images in there.
To do so, we'll create a function called copy_files_to_target_dir() which will copy images from the Images directory into their respective directories inside images/train and images/test.
More specifically, it will:
- Take in a list of source files to copy (e.g.
train_file_list) and a target directory to copy files to. - Iterate through the list of sources files to copy (we'll use
tqdmwhich comes installed with Google Colab to create a progress bar of how many files have been copied). - Convert the source file path to a
Pathobject. - Split the source file path and create a
Pathobject for the destination folder (e.g. "n02112018-Pomeranian" -> "pomeranian"). - Get the target file name (e.g. "n02112018-Pomeranian/n02112018_6208.jpg" -> "n02112018_6208.jpg").
- Create a destination path for the source file to be copied to (e.g.
images_split/train/pomeranian/n02112018_6208.jpg). - Ensure the destination directory exists, similar to the step we took in the previous section (you can't copy files to a directory that doesn't exist).
- Print out the progress of copying (if necessary).
- Copy the source file to the destination using Python's
shutil.copy2(src, dst).
from pathlib import Path
from shutil import copy2
from tqdm.auto import tqdm
# 1. Take in a list of source files to copy and a target directory
def copy_files_to_target_dir(file_list: list[str],
target_dir: str,
images_dir: str = "Images",
verbose: bool = False) -> None:
"""
Copies a list of files from the images directory to a target directory.
Parameters:
file_list (list[str]): A list of file paths to copy.
target_dir (str): The destination directory path where files will be copied.
images_dir (str, optional): The directory path where the images are currently stored. Defaults to 'Images'.
verbose (bool, optional): If set to True, the function will print out the file paths as they are being copied. Defaults to False.
Returns:
None
"""
# 2. Iterate through source files
for file in tqdm(file_list):
# 3. Convert file path to a Path object
source_file_path = Path(images_dir) / Path(file)
# 4. Split the file path and create a Path object for the destination folder
# e.g. "n02112018-Pomeranian" -> "pomeranian"
file_class_name = folder_to_class_name_dict[Path(file).parts[0]]
# 5. Get the name of the target image
file_image_name = Path(file).name
# 6. Create the destination path
destination_file_path = Path(target_dir) / file_class_name / file_image_name
# 7. Ensure the destination directory exists (this is a safety check, can't copy an image to a file that doesn't exist)
destination_file_path.parent.mkdir(parents=True, exist_ok=True)
# 8. Print out copy message if necessary
if verbose:
print(f"[INFO] Copying: {source_file_path} to {destination_file_path}")
# 9. Copy the original path to the destination path
copy2(src=source_file_path, dst=destination_file_path)
Copying function created!
Let's test it out by copying the files in the train_file_list to train_dir.
# Copy training images from Images to images_split/train/...
copy_files_to_target_dir(file_list=train_file_list,
target_dir=train_dir,
verbose=False) # set this to True to get an output of the copy process
# (warning: this will output a large amount of text)
0%| | 0/12000 [00:00<?, ?it/s]
Woohoo!
Looks like our copying function copied 12000 training images in their respective directories inside images_split/train/.
How about we do the same for test_file_list and test_dir?
copy_files_to_target_dir(file_list=test_file_list,
target_dir=test_dir,
verbose=False)
0%| | 0/8580 [00:00<?, ?it/s]
Nice! 8580 testing images copied from Images to images_split/test/.
Let's write some code to check that the number of files in the train_file_list is the same as the number of images files in train_dir (and the same for the test files).
# Get list of of all .jpg paths in train and test image directories
train_image_paths = list(train_dir.rglob("*.jpg"))
test_image_paths = list(test_dir.rglob("*.jpg"))
# Make sure the number of images in the training and test directories equals the number of files in their original lists
assert len(train_image_paths) == len(train_file_list)
assert len(test_image_paths) == len(test_file_list)
print(f"Number of images in {train_dir}: {len(train_image_paths)}")
print(f"Number of images in {test_dir}: {len(test_image_paths)}")
Number of images in images_split/train: 12000 Number of images in images_split/test: 8580
And adhering to the data explorers motto of visualize, visualize, visualize!, let's plot some random images from the train_image_paths list.
# Plot 10 random images from the train_image_paths
plot_10_random_images_from_path_list(path_list=train_image_paths,
extract_title=False) # don't need to extract the title since the image directories are already named simply

Making a 10% training dataset split¶
We've already split the data into training and test sets, so why might we want to make another split?
Well, remember the machine learners motto?
Experiment, experiment, experiment!
We're going to make another training split which contains a random 10% (approximately 1,200 images, since the original training set has 12,000 images) of the data from the original training split.
Why?
Because whilst machine learning models generally perform better with more data, having more data means longer computation times.
And longer computation times means the time between our experiments gets longer.
Which is not what we want in the beginning.
In the beginning of any new machine learning project, your focus should be to reduce the amount of time between experiments as much as possible.
Why?
Because running more experiments means you can figure out what doesn't work.
And if you figure out what doesn't work, you can start working closer towards what does.
Once you find something that does work, you can start to scale up your experiments (more data, bigger models, longer training times - we'll see these later on).
To make our 10% training dataset, let's copy a random 10% of the existing training set to a new folder called images_split/train_10_percent, so we've got the layout:
images_split/
├── train/
│ ├── class_1/
│ │ ├── train_image1.jpg
│ │ ├── train_image2.jpg
│ │ └── ...
│ ├── class_2/
│ │ ├── train_image1.jpg
│ │ ├── train_image2.jpg
│ │ └── ...
├── train_10_percent/ <--- NEW!
│ ├── class_1/
│ │ ├── random_train_image42.jpg
│ │ └── ...
│ ├── class_2/
│ │ ├── random_train_image106.jpg
│ │ └── ...
└── test/
├── class_1/
│ ├── test_image1.jpg
│ ├── test_image2.jpg
│ └── ...
├── class_2/
│ ├── test_image1.jpg
│ ├── test_image2.jpg
│ └── ...
Let's start by creating that folder.
# Create train_10_percent directory
train_10_percent_dir = images_split_dir / "train_10_percent"
train_10_percent_dir.mkdir(parents=True, exist_ok=True)
Now we should have 3 split folders inside images_split.
os.listdir(images_split_dir)
['test', 'train_10_percent', 'train']
Beautiful!
Now let's create a list of random training sample filepaths using Python's random.sample(), we'll want the total length of the list to equal 10% of the original training split.
To make things reproducible, we'll use a random seed (this is not 100% necessary, it just makes it so we get the same 10% of training image paths each time).
import random
# Set a random seed
random.seed(42)
# Get a 10% sample of the training image paths
train_image_paths_random_10_percent = random.sample(population=train_image_paths,
k=int(0.1*len(train_image_paths)))
# Check how many image paths we got
print(f"Original number of training image paths: {len(train_image_paths)}")
print(f"Number of 10% training image paths: {len(train_image_paths_random_10_percent)}")
print("First 5 random 10% training image paths:")
train_image_paths_random_10_percent[:5]
Original number of training image paths: 12000 Number of 10% training image paths: 1200 First 5 random 10% training image paths:
[PosixPath('images_split/train/miniature_pinscher/n02107312_2706.jpg'),
PosixPath('images_split/train/irish_wolfhound/n02090721_272.jpg'),
PosixPath('images_split/train/greater_swiss_mountain_dog/n02107574_3274.jpg'),
PosixPath('images_split/train/italian_greyhound/n02091032_3763.jpg'),
PosixPath('images_split/train/bloodhound/n02088466_7962.jpg')]
Random 10% training image paths acquired!
Let's copy them to the images_split/train_10_percent directory using similar code to our copy_files_to_target_dir() function.
# Copy training 10% split images from images_split/train/ to images_split/train_10_percent/...
for source_file_path in tqdm(train_image_paths_random_10_percent):
# Create the destination file path
destination_file_and_image_name = Path(*source_file_path.parts[-2:]) # "images_split/train/yorkshire_terrier/n02094433_2223.jpg" -> "yorkshire_terrier/n02094433_2223.jpg"
destination_file_path = train_10_percent_dir / destination_file_and_image_name # "yorkshire_terrier/n02094433_2223.jpg" -> "images_split/train_10_percent/yorkshire_terrier/n02094433_2223.jpg"
# If the target directory doesn't exist, make it
target_class_dir = destination_file_path.parent
if not target_class_dir.is_dir():
# print(f"Making directory: {target_class_dir}")
target_class_dir.mkdir(parents=True,
exist_ok=True)
# print(f"Copying: {source_file_path} to {destination_file_path}")
copy2(src=source_file_path,
dst=destination_file_path)
0%| | 0/1200 [00:00<?, ?it/s]
1200 images copied!
Let's check our training 10% set distribution and make sure we've got some images for each class.
We can use our count_images_in_subdirs() function to count the images in each of the dog breed folders in the train_10_percent_dir.
# Count images in train_10_percent_dir
train_10_percent_image_class_counts = count_images_in_subdirs(train_10_percent_dir)
train_10_percent_image_class_counts_df = pd.DataFrame(train_10_percent_image_class_counts).sort_values("image_count", ascending=True)
train_10_percent_image_class_counts_df.head()
| class_name | image_count | |
|---|---|---|
| 33 | labrador_retriever | 3 |
| 23 | welsh_springer_spaniel | 4 |
| 61 | great_dane | 4 |
| 64 | curly_coated_retriever | 4 |
| 100 | sussex_spaniel | 5 |
Okay, looks like a few classes have only a handful of images.
Let's make sure there's 120 subfolders by checking the length of the train_10_percent_image_class_counts_df.
# How many subfolders are there?
print(len(train_10_percent_image_class_counts_df))
120
Beautiful, our train 10% dataset split has a folder for each of the dog breed classes.
Note: Ideally our random 10% training set would have the same distribution per class as the original training set, however, for this example, we've taken a global random 10% rather than a random 10% per class. This is okay for now, however for more fine-grained tasks, you may want to make sure your smaller training set is better distributed.
For one last check, let's plot the distribution of our train 10% dataset.
# Plot distribution of train 10% dataset.
plt.figure(figsize=(14, 7))
train_10_percent_image_class_counts_df.plot(kind="bar",
x="class_name",
y="image_count",
legend=False,
ax=plt.gca()) # plt.gca() = "get current axis", get the plt we setup above and put the data there
# Add customization
plt.title("Train 10 Percent Image Counts by Class")
plt.ylabel("Image Count")
plt.xticks(rotation=90, # Rotate the x labels for better visibility
fontsize=8) # Make the font size smaller for easier reading
plt.tight_layout() # Ensure things fit nicely
plt.show()

Excellent! Our train 10% dataset distribution looks similar to the original training set distribution.
However, it could be better.
If we really wanted to, we could recreate the train 10% dataset with 10% of the images from each class rather than 10% of images globally.
Extension: How would you create the
train_10_percentdata split with 10% of the images from each class? For example, each folder would have at least 10 images of a particular dog breed.
5. Turning datasets into TensorFlow Dataset(s)¶
Alright, we've spent a bunch of time getting our dog images into different folders.
But how do we get the images from different folders into a machine learning model?
Well, like the other machine learning models we've built throughout the course, we need a way to turn our images into numbers.
Specifically, we're going to turn our images into tensors.
That's where the "Tensor" comes from in "TensorFlow".
A tensor is a way to numerically represent something (where something can be almost anything you can think of, text, images, audio, rows and columns).
There are several different ways to load data into TensorFlow.
But the formula is the same across data types, have data -> use TensorFlow to turn it into tensors.
The reason why we spent time getting our data into the standard image classification format (where the class name is the folder name) is because TensorFlow includes several utility functions to load data from this directory format.
| Function | Description |
|---|---|
tf.keras.utils.image_dataset_from_directory() |
Creates a tf.data.Dataset from image files in a directory. |
tf.keras.utils.audio_dataset_from_directory() |
Creates a tf.data.Dataset from audio files in a directory. |
tf.keras.utils.text_dataset_from_directory() |
Creates a tf.data.Dataset from text files in a directory. |
tf.keras.utils.timeseries_dataset_from_array() |
Creates a dataset of sliding windows over a timeseries provided as array. |
What is a tf.data.Dataset?
It's TensorFlow's efficient way to store a potentially large set of elements.
As machine learning datasets can get quite large, you need an efficient way to store and load them.
This is what the tf.data.Dataset API provides.
And it's what we'd like to turn our dog images into.
Since we're working with images, we can do so with tf.keras.utils.image_dataset_from_directory().
We'll pass in the following parameters:
directory= the target directory we'd like to turn into atf.data.Dataset.label_mode= the kind of labels we'd like to use, in our case it's"categorical"since we're dealing with a multi-class classification problem (we would use"binary"if we were working with binary classifcation problem).batch_size= the number of images we'd like our model to see at a time (due to computation limitations, our model won't be able to look at every image at once so we split them into small batches and the model looks at each batch individually), generally 32 is a good value to start, this means our model will look at 32 images at a time (this number is flexible).image_size= the size we'd like to shape our images to before we feed them to our model (height x width).shuffle= whether we'd like our dataset to be shuffled to randomize the order.seed= if we're shuffling the order in a random fashion, do we want that to be reproducible?
Note: Values such as
batch_sizeandimage_sizeare known as hyperparameters, meaning they're values that you can decide what to set them as. As for the best value for a given hyperparameter, that depends highly on the data you're working with, problem space and compute capabilities you've got avaiable. Best to experiment!
With all this being said, let's see it in practice!
We'll make 3 tf.data.Dataset's, train_10_percent_ds, train_ds and test_ds.
import tensorflow as tf
# Create constants
IMG_SIZE = (224, 224)
BATCH_SIZE = 32
SEED = 42
# Create train 10% dataset
train_10_percent_ds = tf.keras.utils.image_dataset_from_directory(
directory=train_10_percent_dir,
label_mode="categorical", # turns labels into one-hot representations (e.g. [0, 0, 1, ..., 0, 0])
batch_size=BATCH_SIZE,
image_size=IMG_SIZE,
shuffle=True, # shuffle training datasets to prevent learning of order
seed=SEED
)
# Create full train dataset
train_ds = tf.keras.utils.image_dataset_from_directory(
directory=train_dir,
label_mode="categorical",
batch_size=BATCH_SIZE,
image_size=IMG_SIZE,
shuffle=True,
seed=SEED
)
# Create test dataset
test_ds = tf.keras.utils.image_dataset_from_directory(
directory=test_dir,
label_mode="categorical",
batch_size=BATCH_SIZE,
image_size=IMG_SIZE,
shuffle=False, # don't need to shuffle the test dataset (this makes evaluations easier)
seed=SEED
)
Found 1200 files belonging to 120 classes. Found 12000 files belonging to 120 classes. Found 8580 files belonging to 120 classes.
Note: If you're working with similar styles of data (e.g. all dog photos), it's best practice to shuffle training datasets to prevent the model from learning any order in the data, no need to shuffle testing datasets (this makes for easier evaluation).
tf.data.Datasets created!
Let's check out one of them.
train_10_percent_ds
<_PrefetchDataset element_spec=(TensorSpec(shape=(None, 224, 224, 3), dtype=tf.float32, name=None), TensorSpec(shape=(None, 120), dtype=tf.float32, name=None))>
You'll notice a few things going on here.
Essentially, we've got a collection of tuples:
- The image tensor(s) -
TensorSpec(shape=(None, 224, 224, 3), dtype=tf.float32, name=None)where(None, 224, 224, 3)is the shape of the image tensor (Noneis the batch size,(224, 224)is theIMG_SIZEwe set and3is the number of colour channels, as in, red, green, blue or RGB since our images are in colour). - The label tensor(s) -
TensorSpec(shape=(None, 120), dtype=tf.float32, name=None)whereNoneis the batch size and120is the number of labels we're using.
The batch size often appears as None since it's flexible and can change on the fly.
Each batch of images is assosciated with a batch of labels.
Instead of talking about it, let's check out what a single batch looks like.
We can do so by turning the tf.data.Dataset into an iterable with Python's built-in iter() and then getting the "next" batch with next().
# What does a single batch look like?
image_batch, label_batch = next(iter(train_ds))
image_batch.shape, label_batch.shape
(TensorShape([32, 224, 224, 3]), TensorShape([32, 120]))
Nice!
We get back a single batch of images and labels.
Looks like a single image_batch has a shape of [32, 224, 224, 3] ([batch_size, height, width, colour_channels]).
And our labels have a shape of [32, 120] ([batch_size, labels]).
These are numerical representations of our data images and labels!
Note: The shape of a tensor does not necessarily reflect the values inside a tensor. The shape only reflects the dimensionality of a tensor. For example,
[32, 224, 224, 3]is a 4-dimensional tensor. Values inside a tensor can be any number (positive, negative, 0, float, integer, etc) representing almost any kind of data.
We can further inspect our data by looking at a single sample.
# Get a single sample from a single batch
print(f"Single image tensor:\n{image_batch[0]}\n")
print(f"Single label tensor: {label_batch[0]}") # notice the 1 is the index of the target label (our labels are one-hot encoded)
print(f"Single sample class name: {dog_names[tf.argmax(label_batch[0])]}")
Single image tensor: [[[196.61607 174.61607 160.61607 ] [197.84822 175.84822 161.84822 ] [200. 178. 164. ] ... [ 60.095097 79.75804 45.769207] [ 61.83293 71.22575 63.288315] [ 77.65755 83.65755 81.65755 ]] [[196. 174. 160. ] [197.83876 175.83876 161.83876 ] [199.07945 177.07945 163.07945 ] ... [ 94.573715 110.55229 83.59694 ] [125.869865 135.26268 127.33472 ] [122.579605 128.5796 126.579605]] [[195.73691 173.73691 159.73691 ] [196.896 174.896 160.896 ] [199. 177. 163. ] ... [ 26.679413 38.759026 20.500835] [ 24.372307 31.440136 26.675896] [ 20.214453 26.214453 24.214453]] ... [[ 61.57369 70.18976 104.72547 ] [189.91965 199.61607 213.28572 ] [247.26637 255. 252.70387 ] ... [113.40158 83.40158 57.40158 ] [110.75214 78.75214 53.752136] [107.37048 75.37048 50.370483]] [[ 61.27007 69.88614 104.42185 ] [188.93079 198.62721 212.29686 ] [246.33257 255. 251.77007 ] ... [110.88623 80.88623 54.88623 ] [102.763245 70.763245 45.763245] [ 99.457634 67.457634 42.457638]] [[ 60.25893 68.875 103.41071 ] [188.58261 198.27904 211.94868 ] [245.93112 254.6097 251.36862 ] ... [105.02222 75.02222 49.022217] [109.11186 77.11186 52.111866] [106.56936 74.56936 49.56936 ]]] Single label tensor: [0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] Single sample class name: schipperke
Woah!!
We've got a numerical representation of a dog image (in the form of red, green, blue pixel values)!
This is exactly the kind of format our model will want.
Can we do the reverse?
Instead of image -> numbers, can we go from numbers -> image?
You bet.
Visualizing images from our TensorFlow Dataset¶
Let's follow the data explorer's motto once again and visualize, visualize, visualize!
How about we turn our single sample from tensor format to image format?
We can do so by passing the single sample image tensor to matplotlib's plt.imshow() (we'll also need to convert its datatype from float32 to uint8 to avoid matplotlib colour range issues).
plt.imshow(image_batch[0].numpy().astype("uint8")) # convert tensor to uint8 to avoid matplotlib colour range issues
plt.title(dog_names[tf.argmax(label_batch[0])])
plt.axis("off");

How about we plot multiple images?
We can do so by first setting up a plot with multiple subplots.
And then we can iterate through our dataset with tf.data.Dataset.take(count=1) which will "take" 1 batch of data (in our case, one batch is 32 samples) which we can then index on for each subplot.
# Create multiple subplots
fig, axes = plt.subplots(nrows=2, ncols=5, figsize=(20, 10))
# Iterate through a single batch and plot images
for images, labels in train_ds.take(count=1): # note: because our training data is shuffled, each "take" will be different
for i, ax in enumerate(axes.flat):
ax.imshow(images[i].numpy().astype("uint8"))
ax.set_title(dog_names[tf.argmax(labels[i])])
ax.axis("off")

Aren't those good looking dogs!
Getting labels from our TensorFlow Dataset¶
Since our data is now in tf.data.Dataset format, there are a couple of important attributes we can pull from it if necessary.
The first is the collection of filepaths asosciated with a tf.data.Dataset.
These are accessible by the .file_paths attribute.
Note: You can often a see a list of assosciated methods and attributes of a variable/class in Google Colab (or other IDEs) by pressing TAB afterwards (e.g type
variable_name.+ TAB).
# Get the first 5 file paths of the training dataset
train_ds.file_paths[:5]
['images_split/train/boston_bull/n02096585_1753.jpg', 'images_split/train/kerry_blue_terrier/n02093859_855.jpg', 'images_split/train/border_terrier/n02093754_2281.jpg', 'images_split/train/rottweiler/n02106550_11823.jpg', 'images_split/train/airedale/n02096051_5884.jpg']
We can also get the class names assosciated with a dataset using .class_names (TensorFlow has read these from the names of our target folders in the images_split directory).
# Get the class names TensorFlow has read from the target directory
class_names = train_ds.class_names
class_names[:5]
['affenpinscher', 'afghan_hound', 'african_hunting_dog', 'airedale', 'american_staffordshire_terrier']
And we can make sure the class names are the same across our datasets by comparing them.
assert set(train_10_percent_ds.class_names) == set(train_ds.class_names) == set(test_ds.class_names)
Configuring our datasets for performance¶
There's one last step we're going to do before we build our first TensorFlow model.
And that's configure our datasets for performance.
More specifically, we're going to focus on following the TensorFlow guide for Better performance with the tf.data API.
Why?
Because data loading is one of the biggest bottlenecks in machine learning.
Modern GPUs can perform calculations (matrix multiplications) to find patterns in data quite quickly.
However, for the GPU to perform such calculations, the data needs to be there.
Good news for us is that if we follow the TensorFlow tf.data best practices, TensorFlow will take care of all these optimizations and hardware acceleration for us.
We're going to call three methods on our dataset to optimize it for performance:
cache()- Cache the elements in the dataset in memory or a target folder (speeds up loading.shuffle()- Shuffle a set number of samples in preparation for loading (this will mean our samples and batches of samples will be shuffled), for example, settingshuffle(buffer_size=1000)will prepare and shuffle 1000 elements of data at a time.prefetch()- Prefetch the next batch of data and prepare it for computation whilst the previous one is being computed on (can scale to multiple prefetches depending on hardware availability). TensorFlow can automatically configure how many elements/batches to prefetch by settingprefetch(buffer_size=tf.data.AUTOTUNE).
Resource: For more performance tips on loading dataset in TensorFlow, see the Datasets Performance tips guide.
In our case, let's start by calling cache() on our datasets to save the loaded samples to memory.
We'll then shuffle() the training splits with buffer_size=10*BATCH_SIZE for the training 10% split and buffer_size=100*BATCH_SIZE for the full training set.
Why these numbers?
That's how many I decided to use via experimentation, feel free to figure out a different number that may work better.
Ideally if your dataset isn't too large, you would shuffle all possible samples (TensorFlow has a method of finding the number of samples in a dataset called tf.data.Dataset.cardinality()).
We won't call shuffle() on the testing dataset since it isn't required.
And we'll call prefetch(buffer_size=tf.data.AUTOTUNE) on each of our datasets to automatically load and prepare a number of data batches.
AUTOTUNE = tf.data.AUTOTUNE # let TensorFlow find the best values to use automatically
# Shuffle and optimize performance on training datasets
# Note: these methods can be chained together and will have the same effect as calling them individually
train_10_percent_ds = train_10_percent_ds.cache().shuffle(buffer_size=10*BATCH_SIZE).prefetch(buffer_size=AUTOTUNE)
train_ds = train_ds.cache().shuffle(buffer_size=100*BATCH_SIZE).prefetch(buffer_size=AUTOTUNE)
# Don't need to shuffle test datasets (for easier evaluation)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Dataset performance optimized!
We spent some extra time here because datasets are so important to machine learning and deep learning workflows, wherever you can make them faster, you should.
Time to create our first neural network with TensorFlow!
6. Creating a neural network with TensorFlow¶
We've spent lots of time preparing the data.
This is because it's often the largest part of a machine learning problem, getting your data ready for a machine learning model.
Thanks to modern frameworks like TensorFlow, when you've got your data in order, building a deep learning model to find patterns in your data can be one of the easier steps of the process.
When you hear people talk about deep learning, they're often referring to neural networks.
Neural networks are one of the most flexible machine learning models there is.
You can create a neural network to fit almost any kind of data.
The "deep" in deep learning refers to the many layers that can be contained inside a neural network.
A neural network often follows the structure of:
Input layer -> Middle layer(s) -> Output layer.

General anatomy of a neural network. Neural networks are almost infinitely customisable. The main premise is that data goes in one end, gets manipulated by many small functions in an attempt to learn patterns/weights which represent the data to produce useful outputs. Note that "patterns" is an arbitrary term, you’ll often hear "embedding", "weights", "feature representation", "representation" all referring to similar things.
Where the input layer takes in the data, the middle layer(s) perform calculations on the data and (hopefully) learn patterns (also called weights/biases) to represent the data and the output layer performs a final transformation on the learned patterns to make them usable in human applications.
What goes into the middle layer(s)?
That's an excellent question.
Because there are so many different options.
But two of the most popular modern kinds of neural network are Convolutional Neural Networks (CNNs) and Transformers (the Transformer is the "T" in GPT, Generative Pretrained Transformer).
| Architecture | Description | Example Layers | Problem Examples |
|---|---|---|---|
| Transformer) | A combination of fully connected layers as well as attention-based layers. | tf.keras.layers.Attention, tf.keras.layers.Dense |
NLP, Machine Translation, Computer Vision |
| Convolutional Neural Network | A combination of fully connected layers as well as convolutional-based layers. | tf.keras.layers.Conv2D, tf.keras.layers.Dense |
Computer Vision, Audio Processing |
Because our problem is in the computer space, we're going to use a CNN.
And instead of crafting our own CNN from scratch, we're going to take an existing CNN model and apply it to our own problem, harnessing the wonderful superpower of transfer learning.
Note: You can build and use working neural networks with TensorFlow without knowing the intricate details that's going on the behind the scenes (that's what we're focused on). For an idea of the mathematical operations that make neural networks work, I'd recommend going through 3Blue1Brown's YouTube series on Neural Networks.
The magic of transfer learning¶
Transfer learning is the process of getting an existing working model and adjusting it to your own problem.
This works particularly well for neural networks.
The main benefit of transfer learning is being able to get better results in less time with less data.
How?
An existing model may have the following features:
- Trained on lots of data (in the case of computer vision, existing models are often pretrained on ImageNet, a dataset of 1M+ images, this means they've already learned patterns across many different kinds of images).
- Crafted by expert researchers (large universities and companies such as Google and Meta often open-source their best models for others to try and use).
- Trained of lots of computing hardware (the larger the model and the larger the dataset, the more compute power you need, not everyone has access to 10s, 100s or 1000s of GPUs).
- Proven to perform well on a given task through several studies (this means it has a good chance on performing well on your task if it's similar).
You may be thinking, ok so, this all sounds incredible, where can I get pretrained models?
And the good news is, there are plenty of places to find pretrained models!
| Resource | Description |
|---|---|
tf.keras.applications |
A module built-in to TensorFlow and Keras with a series of pretrained models ready to use. |
| KerasNLP and KerasCV | Two dedicated libraries for NLP (natural language processing) and CV (computer vision) each of which includes many modality-specific APIs and is capable of running with TensorFlow, JAX or PyTorch. |
| Hugging Face Models Hub | A large collection of pretrained models on a wide range on tasks, from computer vision to natural language processing to audio processing. |
| Kaggle Models | A huge collection of different pretrained models for many different tasks. |

Different locations to find pretrained models. This list is consistantly expanding as machine learning becomes more and more open-source.
Note: For most new machine learning problems, if you're looking to get good results quickly, you should generally look for a pretrained model similar to your problem and use transfer learning to adapt it to your own domain.
Since we're focused on TensorFlow/Keras, we're going to be using a pretrained model from tf.keras.applications.
More specifically, we're going to take the tf.keras.applications.efficientnet_v2.EfficientNetV2B0() model from the 2021 machine learning paper EfficientNetV2: Smaller Models and Faster Training from Google Research and apply it to our own problem.
This model has been trained on ImageNet1k (1M+ images across 1000 different diverse classes, there is a version called ImageNet22k with 14M+ images across 22,000 categories) so it has a good baseline understanding of patterns in images across a wide domain.
We'll see if we can adjust those patterns slightly to our dog images.
Let's create an instance of it and call it base_model (I'll explain why next).
# Create the input shape to our model
INPUT_SHAPE = (*IMG_SIZE, 3)
base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(
include_top=True, # do want to include the top layer? (ImageNet has 1000 classes, so the top layer is formulated for this, we want to create our own top layer)
include_preprocessing=True, # do we want the network to preprocess our data into the right format for us? (yes)
weights="imagenet", # do we want the network to come with pretrained weights? (yes)
input_shape=INPUT_SHAPE # what is the input shape of our data we're going to pass to the network? (224, 224, 3) -> (height, width, colour_channels)
)
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/efficientnet_v2/efficientnetv2-b0.h5 29403144/29403144 [==============================] - 0s 0us/step
Base model created!
We can find out information about our base model by calling base_model.summary().
# Note: Uncomment to see full output
# base_model.summary()
Truncated output of base_model.summary():

Woah! Look at all those layers... this is what the "deep" in deep learning means! A deep number of layers.
How about we count the number of layers?
# Count the number of layers
print(f"Number of layers in base_model: {len(base_model.layers)}")
Number of layers in base_model: 273
273 layers!
Wow, there's a lot going on.
Rather than step through each layer and explain what's happening in each layer, I'll leave that for the curious mind to research on their own.
Just know that when starting out deep learning you don't need to know what's happening every layer in a model to be able to use a model.
For now, let's pay attention to a few things:
- The input layer (the first layer) input shape, this will tell us the shape of the data the model expects as input.
- The output layer (the last layer) output shape, this will tell us the shape of the data the model will output.
- The number of parameters of the model, these are "learnable" numbers (also called weights) that a model will use to derive patterns out of and represent the data. Generally, the more parameters a model has, the more learning capacity it has.
- The number of layers a model has. Generally, the more layers a model has, the more learning capacity it has (each layer will learn progressively deeper patterns from the data). However, this caps out at a certain range.
Let's step through each of these.
Model input and output shapes¶
One of the most important practical steps in using a deep learning model is input and output shapes.
Two questions to ask:
- What is the shape of my input data?
- What is the ideal shape of my output data?
We ask about shapes because in all deep learning models input and output data comes in the form of tensors.
This goes for text, audio, images and more.
The raw data gets converted to a numerical representation first before being passed to a model.
In our case, our input data has the shape of [(32, 224, 224, 3)] or [(batch_size, height, width, colour_channels)].
And our ideal output shape will be [(32, 120)] or [(batch_size, number_of_dog_classes).
Your input and output shapes will differ depending on the problem and data you're working with.
But as you get deeper into the world of machine learning (and deep learning), you'll find input and output shapes are one of the most common errors.
We can check our model's input and output shapes with the .input_shape and .output_shape attributes.
# Check the input shape of our model
base_model.input_shape
(None, 224, 224, 3)
Nice! Looks like our model's input shape is where we want it (remember None in this case is equivalent to a wild card dimension, meaning it could be any value, but we've set ours to 32).
This is because the model we chose, tf.keras.applications.efficientnet_v2.EfficientNetV2B0, has been trained on images the same size as our images.
If our model had a different input shape, we'd have to make sure we processed our images to be the same shape.
Now let's check the output shape.
# Check the model's output shape
base_model.output_shape
(None, 1000)
Hmm, is this what we're after?
Since we have 120 dog classes, we'd like an output shape of (None, 120).
Why is it by default (None, 1000)?
This is because the model has been trained already on ImageNet, a dataset of 1,000,000+ images with 1000 classes (hence the 1000 in the output shape).
How can we change this?
Let's recreate a base_model instance, except this time we'll change the classes parameter to 120.
# Create a base model with 120 output classes
base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(
include_top=True,
include_preprocessing=True,
weights="imagenet",
input_shape=INPUT_SHAPE,
classes=len(dog_names)
)
base_model.output_shape
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-62-5e9b29e6f858> in <cell line: 2>() 1 # Create a base model with 120 output classes ----> 2 base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0( 3 include_top=True, 4 include_preprocessing=True, 5 weights="imagenet", /usr/local/lib/python3.10/dist-packages/keras/src/applications/efficientnet_v2.py in EfficientNetV2B0(include_top, weights, input_tensor, input_shape, pooling, classes, classifier_activation, include_preprocessing) 1128 include_preprocessing=True, 1129 ): -> 1130 return EfficientNetV2( 1131 width_coefficient=1.0, 1132 depth_coefficient=1.0, /usr/local/lib/python3.10/dist-packages/keras/src/applications/efficientnet_v2.py in EfficientNetV2(width_coefficient, depth_coefficient, default_size, dropout_rate, drop_connect_rate, depth_divisor, min_depth, bn_momentum, activation, blocks_args, model_name, include_top, weights, input_tensor, input_shape, pooling, classes, classifier_activation, include_preprocessing) 932 933 if weights == "imagenet" and include_top and classes != 1000: --> 934 raise ValueError( 935 "If using `weights` as `'imagenet'` with `include_top`" 936 " as true, `classes` should be 1000" ValueError: If using `weights` as `'imagenet'` with `include_top` as true, `classes` should be 1000Received: classes=120
Oh dam!
We get an error:
ValueError: If using weights as 'imagenet' with include_top as true, classes should be 1000 Received: classes=120
What this is saying is that if we want to using the pretrained 'imagenet' weights (which we do to leverage the visual patterns/features a model has already learned on ImageNet, we need to change the parameters to the base_model.
What we're going to do is create our own top layers.
We can do this by setting include_top=False.
What this means is we'll use most of the model's existing layers to extract features and patterns out of our images and then customize the final few layers to our own problem.
This kind of transfer learning is often called feature extraction.
A setup where you use an existing models pretrained weights to extract features (or patterns) from your own custom data.
You can then used those extracted features and further tailor them to your own use case.
Let's create an instance of base_model without a top layer.
# Create a base model with no top
base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(
include_top=False, # don't include the top layer (we want to make our own top layer)
include_preprocessing=True,
weights="imagenet",
input_shape=INPUT_SHAPE,
)
# Check the output shape
base_model.output_shape
Downloading data from https://storage.googleapis.com/tensorflow/keras-applications/efficientnet_v2/efficientnetv2-b0_notop.h5 24274472/24274472 [==============================] - 0s 0us/step
(None, 7, 7, 1280)
Hmm, what's this output shape?
This still isn't what we want (we're after (None, 120) for our number of dog classes).
How about we check the number of layers again?
# Count the number of layers
print(f"Number of layers in base_model: {len(base_model.layers)}")
Number of layers in base_model: 270
Looks like our new base_model has less layers than our previous one.
This is because we used include_top=False.
This means we've still got 270 base layers to extract features and patterns from our images, however, it also means we get to customize the output layers to our liking.
We'll come back to this shortly.
Model parameters¶
In traditional programming, you write a list of rules for inputs to go in, get manipulated in some predefined way and then outputs come out.
However, as we've discussed, machine learning switches the order.
Inputs and ideal outputs go in (for example, dog images and their corresponding labels) and rules come out.
A model's parameters are the learned rules.
And learned is the important point.
In an ideal setup, we never tell the model what parameters to learn, it learns them itself by connecting input data to labels in supervised learning and by grouping together similar samples in unsupervised learning.
Note: Parameters are values learned by a model where as hyperpameters (e.g. batch size) are values set by a human.
Parameters also get referred to as "weights" or "patterns" or "learned features" or "learned representations".
Generally, the more parameters a model has, the more capacity it has to learn.
Each layer in a deep learning model will have a specific number of parameters (these vary depending on which layer you use).
The benefit of using a preconstructed model and transfer learning is that someone else has done the hard work in finding what combination of layers leads to a good set of parameters (a big thank you to these wonderful people).
We can count the number of parameters in a model/layer via the the .count_params() method.
# Check the number of parameters in our model
base_model.count_params()
5919312
Holy smokes!
Our model has 5,919,312 parameters!
That means each time an image goes through our model, it will be influenced in some small way by 5,919,312 numbers.
Each one of these is a potential learning opportunity (except for parameters that are non-trainable but we'll get to that soon too).
Now, you may be thinking, 5 million+ parameters sounds like a lot.
And it is.
However, many modern large scale models, such as GPT-3 (175B) and GPT-4 (200B+? the actual number of parameters was never released) deal in the billions of parameters (note: this is written in 2024, so if you're reading this in future, parameter counts may be in the trillions).
Generally, more parameters leads to better models.
However, there are always tradeoffs.
More parameters means more compute power to run the models.
In practice, if you have limited compute power (e.g. a single GPU on Google Colab), it's best to start with smaller models and gradually increase the size when necessary.
We can get the trainable and non-trainable parameters from our model with the trainable_weights and non_trainable_weights attributes (remember, parameters are also referred to as weights).
Note: Trainable weights are parameters of the model which are updated by backpropagation during training (they are changed to better match the data) where as non-trainable weights are parameters of the model which are not updated by backpropagation during training (they are fixed in place).
Let's write a function to count the trainable, non-trainable and trainable parameters of a model.
import numpy as np
def count_parameters(model, print_output=True):
"""
Counts the number of trainable, non-trainable and total parameters of a given model.
"""
trainable_parameters = np.sum([np.prod(layer.shape) for layer in model.trainable_weights])
non_trainable_parameters = np.sum([np.prod(layer.shape) for layer in model.non_trainable_weights])
total_parameters = trainable_parameters + non_trainable_parameters
if print_output:
print(f"Model {model.name} parameter counts:")
print(f"Total parameters: {total_parameters}")
print(f"Trainable parameters: {trainable_parameters}")
print(f"Non-trainable parameters: {non_trainable_parameters}")
else:
return total_parameters, trainable_parameters, non_trainable_parameters
count_parameters(model=base_model, print_output=True)
Model efficientnetv2-b0 parameter counts: Total parameters: 5919312 Trainable parameters: 5858704 Non-trainable parameters: 60608
Nice! It looks like our function worked.
Most of our model's parameters are trainable.
This means they will be tweaked as they see more images of dogs.
However, a standard practice in transfer learning is to freeze the base layers of a model and only train the custom top layers to suit your problem.

Example of how we can take a pretrained model and customize it to our own use case. This kind of transfer learning workflow is often referred to as a feature extracting workflow as the base layers are frozen (not changed during training) and only the top layers are trained. Note: In this image the EfficientNetB0 architecture is being demonstrated, however we're going to be using the EfficientNetV2B0 architecture which is slightly different. I've used the older architecture image from the research paper as a newer one wasn't available.
In other words, keep the patterns an existing model has learned on a similar problem (if they're good) to form a base representation of an input sample and then manipulate that base representation to suit our needs.
Why do this?
It's faster.
The less trainable parameters, the faster your model training will be, the faster your experiments will be.
But how will we know this works?
We're going to run experiments to test it.
Okay, so how do we freeze the parameters of our base_model?
We can set its .trainable attribute to False.
# Freeze the base model
base_model.trainable = False
base_model.trainable
False
base_model frozen!
Now let's check the number of trainable and non-trainable parameters.
count_parameters(model=base_model, print_output=True)
Model efficientnetv2-b0 parameter counts: Total parameters: 5919312.0 Trainable parameters: 0.0 Non-trainable parameters: 5919312
Beautiful!
Looks like all of the parameters in our base_model are now non-trainable (frozen).
This means they won't be updated during training.
Passing data through our model¶
We've spoken a couple of times how our base_model is a "feature extractor" or "pattern extractor".
But what does this mean?
It means that when a data sample goes through the base_model, its numbers get manipulated into a compressed set of features.
In other words, the layers of the model will each perform a calculation on the sample eventually leading to an output tensor with patterns the model has deemed most important.
This is often referred to a compressed feature space.
That's one of the central ideas of deep learning.
Take a large input (e.g. an image tensor of shape [224, 224, 3]) and compress it into a smaller output (e.g. a feature vector#Feature_vectors) of shape [1280]) that captures a useful representation of the input.
![A visual representation of feature extraction from an input image using a neural network model. The process starts with an input image of a dog with dimensions 224 by 224 pixels and 3 color channels (totaling 150,528 data points). The image is processed by the model, symbolized by a network diagram, to produce a learned feature vector or embedding. The resulting tensor is displayed with a shape of [1, 1280], containing 1280 data points, which signifies an 117x reduction in the dimensionality from the original image data.](https://github.com/mrdbourke/zero-to-mastery-ml/blob/master/images/unstructured-data-feature-vector-extraction.png?raw=true)
Example of how a model can take an input piece of data and compress its representation into a feature vector with much lower dimensionality than the original data.
Note: A feature vector is also referred to as an embedding, a compressed representation of a data sample that makes it useful. The concept of embeddings is not limited to images either, the concept of embeddings stretches across all data types (text, images, video, audio + more).
We can see this in action by passing a single image through our base_model.
# Extract features from a single image using our base model
feature_extraction = base_model(image_batch[0])
feature_extraction
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-69-957d897dc1dc> in <cell line: 2>() 1 # Extract features from a single image using our base model ----> 2 feature_extraction = base_model(image_batch[0]) 3 feature_extraction /usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs) 68 # To get the full stack trace, call: 69 # `tf.debugging.disable_traceback_filtering()` ---> 70 raise e.with_traceback(filtered_tb) from None 71 finally: 72 del filtered_tb /usr/local/lib/python3.10/dist-packages/keras/src/engine/input_spec.py in assert_input_compatibility(input_spec, inputs, layer_name) 296 if spec_dim is not None and dim is not None: 297 if spec_dim != dim: --> 298 raise ValueError( 299 f'Input {input_index} of layer "{layer_name}" is ' 300 "incompatible with the layer: " ValueError: Input 0 of layer "efficientnetv2-b0" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(224, 224, 3)
Oh no!
Another error...
ValueError: Input 0 of layer "efficientnetv2-b0" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(224, 224, 3)
We've stumbled upon one of the most common errors in machine learning, shape errors.
In our case, the shape of the data we're trying to put into the model doesn't match the input shape the model is expecting.
Our input data shape is (224, 224, 3) ((height, width, colour_channels)), however, our model is expecting (None, 224, 224, 3) ((batch_size, height, width, colour_channels)).
We can fix this error by adding a singluar batch_size dimension to our input and thus make it (1, 224, 224, 3) (a batch_size of 1 for a single sample).
To do so, we can use the tf.expand_dims(input=target_sample, axis=0) where target_sample is our input tensor and axis=0 means we want to expand the first dimension.
# Current image shape
shape_of_image_without_batch = image_batch[0].shape
# Add a batch dimension to our single image
shape_of_image_with_batch = tf.expand_dims(input=image_batch[0], axis=0).shape
print(f"Shape of image without batch: {shape_of_image_without_batch}")
print(f"Shape of image with batch: {shape_of_image_with_batch}")
Shape of image without batch: (224, 224, 3) Shape of image with batch: (1, 224, 224, 3)
Perfect!
Now let's pass this image with a batch dimension to our base_model.
# Extract features from a single image using our base model
feature_extraction = base_model(tf.expand_dims(image_batch[0], axis=0))
feature_extraction
<tf.Tensor: shape=(1, 7, 7, 1280), dtype=float32, numpy=
array([[[[-2.19177201e-01, -3.44185606e-02, -1.40321642e-01, ...,
-1.44454449e-01, -2.73809850e-01, -7.41252452e-02],
[-8.69670734e-02, -6.48750067e-02, -2.14546964e-01, ...,
-4.57209721e-02, -2.77900100e-01, -8.20885971e-02],
[-2.76872963e-01, -8.26781020e-02, -3.85153107e-02, ...,
-2.72128999e-01, -2.52802134e-01, -2.28105962e-01],
...,
[-1.01604000e-01, -3.55145968e-02, -2.23027021e-01, ...,
-2.26227805e-01, -8.61771777e-02, -1.60450727e-01],
[-5.87608740e-02, -4.65543661e-03, -1.06193267e-01, ...,
-2.87548676e-02, -9.06914026e-02, -1.82624385e-01],
[-6.27618432e-02, -1.38620799e-03, 1.52704502e-02, ...,
-7.85450079e-03, -1.84584558e-01, -2.62404829e-01]],
[[-2.17334151e-01, -1.10280879e-01, -2.74605274e-01, ...,
-2.22405165e-01, -2.74738282e-01, -1.01998925e-01],
[-1.40700653e-01, -1.66820198e-01, -2.77449101e-01, ...,
2.40375683e-01, -2.77627349e-01, -9.07808691e-02],
[-2.40916476e-01, -2.00582087e-01, -2.38370374e-01, ...,
-8.27576742e-02, -2.78428614e-01, -1.23056054e-01],
...,
[-2.67296195e-01, -5.43131726e-03, -6.44061863e-02, ...,
-3.34720500e-02, -1.55141622e-01, -3.23073938e-02],
[-2.66513556e-01, -2.09966358e-02, -1.50375053e-01, ...,
-6.29274473e-02, -2.69798309e-01, -2.74081439e-01],
[-8.39830115e-02, -1.58605091e-02, -2.78447241e-01, ...,
-1.43555822e-02, -2.77474761e-01, 1.37483165e-01]],
[[-2.15840712e-01, 4.50323820e-01, -7.51058161e-02, ...,
-2.43637279e-01, -2.75048614e-01, -6.00421876e-02],
[-2.39066556e-01, -2.25066260e-01, -4.89832312e-02, ...,
-2.77957618e-01, -1.14677951e-01, -2.69968715e-02],
[-1.60943881e-01, -2.12972730e-01, -1.08622171e-01, ...,
-2.78464079e-01, -1.95970193e-01, -2.92074662e-02],
...,
[-2.67642140e-01, -7.13412274e-10, -2.47387841e-01, ...,
-1.27752789e-03, 1.69062471e+00, -1.07747754e-02],
[-2.69456387e-01, -3.02123808e-05, -2.19904676e-01, ...,
-1.19841937e-02, 6.54936790e-01, 4.92877871e-01],
[-1.83339473e-02, -9.84105989e-02, -2.77752399e-01, ...,
-9.53171253e-02, -2.76987553e-01, -1.81873620e-01]],
...,
[[-6.59235120e-02, -1.64803467e-03, -1.58951283e-01, ...,
-1.34164095e-01, -6.30896613e-02, -7.77927637e-02],
[-1.83377475e-01, -4.98497509e-04, -1.57654762e-01, ...,
-4.48885784e-02, -1.06884383e-01, -2.78372377e-01],
[-2.45749369e-01, -9.95399058e-03, -1.79216102e-01, ...,
-1.02837617e-02, -1.84168354e-01, -1.70697242e-01],
...,
[ 2.22050592e-01, -2.04384560e-04, -1.46467671e-01, ...,
-2.65387502e-02, -1.85434178e-01, -9.71652716e-02],
[ 1.52228832e+00, -3.39617883e-03, -3.22414264e-02, ...,
-1.19287046e-02, -1.46435276e-01, -8.73169452e-02],
[-1.89164400e-01, -5.49114570e-02, -2.05218419e-01, ...,
-1.32163316e-01, -1.48950770e-01, -1.18042991e-01]],
[[-2.16520607e-01, -7.84920622e-03, -1.43650264e-01, ...,
-1.73660204e-01, -4.83706780e-02, -3.76228467e-02],
[-2.78293848e-01, -6.24539470e-03, -2.28590608e-01, ...,
-2.06465453e-01, -1.93291768e-01, -9.23046917e-02],
[-2.40500003e-01, -2.73558766e-01, -1.58736348e-01, ...,
-4.13209312e-02, -2.64240265e-01, -3.26484852e-02],
...,
[-2.31358394e-01, -2.72292078e-01, -6.80670887e-02, ...,
-2.16453914e-02, -2.71368980e-01, -3.88960652e-02],
[-2.45319903e-01, -2.78179497e-01, -6.18890636e-02, ...,
-1.86282583e-02, -2.23804727e-01, -2.72233319e-02],
[-2.31111392e-01, -2.37449735e-01, -5.13911694e-02, ...,
-4.55225781e-02, -2.74753064e-01, -3.51530202e-02]],
[[-3.96142267e-02, -1.39998682e-02, -9.56050456e-02, ...,
-2.33392462e-01, -1.83407709e-01, -4.99856956e-02],
[-2.60713607e-01, -3.96164991e-02, -1.29626304e-01, ...,
-2.78417081e-01, -2.78285533e-01, -7.70441368e-02],
[-8.02241415e-02, -2.30456606e-01, -1.13508031e-01, ...,
-5.45607917e-02, -2.71063268e-01, -2.75666509e-02],
...,
[-9.41052362e-02, -2.42691532e-01, -5.48249595e-02, ...,
-2.13044193e-02, -2.63691694e-01, -9.28506851e-02],
[-9.08804908e-02, -2.40457997e-01, -7.88932368e-02, ...,
-3.80579121e-02, -2.71065891e-01, -4.05692160e-02],
[-1.26358300e-01, -2.17053503e-01, -7.44825602e-02, ...,
-5.66985942e-02, -2.75216103e-01, -6.91162944e-02]]]],
dtype=float32)>
Woah! Look at all those numbers!
After passing through ~270 layers, this is the numerical representation our model has created of our input image.
You might be thinking, okay, there's a lot here, how can I possibly understand all of them?
Well, with enough effort, you might.
However, these numbers are more for a model/computer to understand than for a human to understand.
Let's not stop there, let's check the shape of our feature_extraction.
# Check shape of feature extraction
feature_extraction.shape
TensorShape([1, 7, 7, 1280])
Ok, looks like our model has compressed our input image into a lower dimensional feature space.
Note: Feature space (or latent space or embedding space) is a numerical region where pieces of data are represented by tensors of various dimensions. Feature space is hard for humans to imagine because it could be 1000s of dimensions (humans are only good at imagining 3-4 dimensions at max). But you can think of feature space as an area where numerical representations of similar items will be close to together. If feature space was a grocery store, one breed of dogs may be in one aisle (similar numbers) where as another breed of dogs may be in the next aisle. You can see an example of a large embedding space representation of 8M Stack Overflow questions on Nomic Atlas.
Let's compare the new shape to the input shape.
num_input_features = 224*224*3
feature_extraction_features = 1*7*7*1280
# Calculate the compression ratio
num_input_features / feature_extraction_features
2.4
Looks like our model has compressed the numerical representation of our input image by 2.4x so far.
But you might've noticed our feature_extraction is still a tensor.
How about we take it further and turn it into a vector and compress the representation even further?
We can do so by taking our feature_extraction tensor and pooling together the inner dimensions.
By pooling, I mean taking the average or the maximum values.
Why?
Because a neural network often outputs a large amount of learned feature values but many of them can be insignificant compared to others.
So taking the average or the max across them helps us compress the representation further while stil preserving the most important features.
This process is often referred to as:
- Average pooling - Take the average across given dimensions of a tensor, can perform with
tf.keras.layers.GlobalAveragePooling2D(). - Max pooling - Take the maximum value across given dimensions of a tensor, can perform with
tf.keras.layers.MaxPooling2D().
Let's try apply average pooling to our feature extraction and see what happens.
# Turn feature extraction into a feature vector
feature_vector = tf.keras.layers.GlobalAveragePooling2D()(feature_extraction) # pass feature_extraction to the pooling layer
feature_vector
<tf.Tensor: shape=(1, 1280), dtype=float32, numpy=
array([[-0.11521906, -0.04476562, -0.12476546, ..., -0.09118073,
-0.08420841, -0.07769417]], dtype=float32)>
Ho, ho!
Looks like we've compressed our feature_extraction tensor into a feature vector (notice the new shape of (1, 1280)).
Now if you're not sure what all these numbers mean, that's okay. I don't either.
A feature vector (also called an embedding) is supposed to be a numerical representation that's meaningful to computers.
We'll perform a few more transforms on it before it's recognizable to us.
Let's check out its shape.
# Check out the feature vector shape
feature_vector.shape
TensorShape([1, 1280])
We've reduced the shape of feature_extraction from (1, 7, 7, 1280) to (1, 1280) (we've gone from a tensor with multiple dimensions to a vector with one dimension of size 1280).
Our neural network has performed calculations on our image and it is now represented by 1280 numbers.
This is one of the main goals of deep learning, to reduce higher dimensional information into a lower dimensional but still representative space.
Let's calculate how much we've reduced the dimensionality of our single input image.
# Compare the reduction
num_input_features = 224*224*3
feature_extraction_features = 1*7*7*1280
feature_vector_features = 1*1280
print(f"Input -> feature extraction reduction factor: {num_input_features / feature_extraction_features}")
print(f"Feature extraction -> feature vector reduction factor: {feature_extraction_features / feature_vector_features}")
print(f"Input -> feature extraction -> feature vector reduction factor: {num_input_features / feature_vector_features}")
Input -> feature extraction reduction factor: 2.4 Feature extraction -> feature vector reduction factor: 49.0 Input -> feature extraction -> feature vector reduction factor: 117.6
A 117.6x reduction from our original image to its feature vector representation!
Why compress the representation like this?
Because representing our data in a compressed format but still with meaningful numbers (to a computer) means that less computation is required to reuse the patterns.
For example, imagine you have to relearn how to spell words every time you use them.
Would this be efficient?
Not at all.
Instead, you take a while to learn them at the start and then continually reuse this knowledge over time.
This is the same with a deep learning model.
It learns representative patterns in data, figures out the ideal connections between inputs and outputs and then reuses them over time in the form of numerical weights.
Going from image to feature vector (practice)¶
We've covered a fair bit in the past few sections.
So let's practice.
The important takeaway is that one of the main goals of deep learning is to create a model that is able to take some kind of high dimensional data (e.g. an image tensor, a text tensor, an audio tensor) and extract meaningful patterns in it whilst compressing it to a lower dimensional form (e.g. a feature vector or embedding).
We can then use this lower dimensional form for our specific use cases.
And one of the most powerful ways to do this is with transfer learning.
Taking an existing model from a similar domain to yours and applying it to your own problem.
To practice turning a data sample into a feature vector, let's start by recreating a base_model instance.
This time, we can add in a pooling layer automatically using pooling="avg" or pooling="max".
Note: I demonstrated the use of the
tf.keras.layers.GlobalAveragePooling2D()layer because not all pretrained models have the functionality of a pooling layer being built-in.
# Create a base model with no top and a pooling layer built-in
base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(
include_top=False,
weights="imagenet",
input_shape=INPUT_SHAPE,
pooling="avg", # can also use "max"
include_preprocessing=True,
)
# Check the summary (optional)
# base_model.summary()
# Check the output shape
base_model.output_shape
(None, 1280)
Boom!
We get the same output shape from the base_model as we did when using it with a pooling layer thanks to using pooling="avg".
Let's now freeze these base weights, so they're not trainable.
# Freeze the base weights
base_model.trainable = False
# Count the parameters
count_parameters(model=base_model, print_output=True)
Model efficientnetv2-b0 parameter counts: Total parameters: 5919312.0 Trainable parameters: 0.0 Non-trainable parameters: 5919312
And now we can pass an image through our base model and get a feature vector from it.
# Get a feature vector of a single image (don't forget to add a batch dimension)
feature_vector_2 = base_model(tf.expand_dims(image_batch[0], axis=0))
feature_vector_2
<tf.Tensor: shape=(1, 1280), dtype=float32, numpy=
array([[-0.11521906, -0.04476562, -0.12476546, ..., -0.09118073,
-0.08420841, -0.07769417]], dtype=float32)>
Wonderful!
Now is this the same as our original feature_vector?
We can find out by comparing feature_vector and feature_vector_2 and seeing if all of the values are the same with np.all().
# Compare the two feature vectors
np.all(feature_vector == feature_vector_2)
True
Perfect!
Let's put it all together and create a full model for our dog vision problem.
Creating a custom model for our dog vision problem¶
The main steps when creating any kind of deep learning model from scratch are:
- Define the input layer(s).
- Define the middle layer(s).
- Define the output layer(s).
These sound broad because they are. Deep learning models are almost infinitely customizable.
Good news is, thanks to transfer learning, all of our middle layers are defined by base_model (you could argue the input layer is created too).
So now it's up to us to define our input and output layers.
TensorFlow/Keras have two main ways of connecting layers to form a model.
- The Sequential model (
tf.keras.Sequential) - Useful for making simple models with one tensor in and one tensor out, not suited for complex models. - The Functional API - Useful for making more complex and multi-step models but can also be used for simple models.
Let's start with the Sequential model.
It takes a list of layers and will pass data through them sequentially.
Our base_model will be the input and middle layers and we'll use a tf.keras.layers.Dense() layer as the output (we'll discuss this shortly).
Creating a model with the Sequential API¶
The Sequential API is the most straightforward way to create a model.
Your model comes in the form of a list of layers from input to middle layers to output.
Each layer is executed sequentially.
# Create a sequential model
tf.random.set_seed(42)
sequential_model = tf.keras.Sequential([base_model, # input and middle layers
tf.keras.layers.Dense(units=len(dog_names), # output layer
activation="softmax")])
sequential_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
efficientnetv2-b0 (Functio (None, 1280) 5919312
nal)
dense (Dense) (None, 120) 153720
=================================================================
Total params: 6073032 (23.17 MB)
Trainable params: 153720 (600.47 KB)
Non-trainable params: 5919312 (22.58 MB)
_________________________________________________________________
Wonderful!
We've now got a model with 6,073,032 parameters, however, only 153,720 of them (the ones in the dense layer) are trainable.
Our dense layer (also called a fully-connected layer or feed-forward layer) takes the outputs of the base_model and performs further calulations on them to map them to our required number of classes (120 for the number of dog breeds).
We use activation="softmax" (the Softmax function) to get prediction probablities, values between 0 and 1 which represent how much our model "thinks" a specific image relates to a certain class.
There's another common activation function called Sigmoid. If we only had two classes, for example, "dog" or "cat", we'd lean towards using this function.
Confusing, yes, but you'll get used to different functions with practice.
The following table summarizes a few use cases.
| Activation Function | Use Cases | Code |
|---|---|---|
| Sigmoid | - When you have two choices (like yes or no, true or false). - In binary classification, where you're deciding between one thing or another (like if an email is spam or not spam). - When you want the output to be a probability between 0 and 1. |
tf.keras.activations.sigmoid or activation="sigmoid" |
| Softmax | - When you have more than two choices. - In multi-class classification, like if you're trying to decide if a picture is of a dog, a cat, a horse, or a bird. - When you want to compare the probabilities across different options and pick the most likely one. |
tf.keras.activations.softmax or activation="softmax" |
Now our model is built, let's check our input and output shapes.
# Check the input shape
sequential_model.input_shape
(None, 224, 224, 3)
# Check the output shape
sequential_model.output_shape
(None, 120)
Beautiful!
Our sequential model takes in an image tensor of size [None, 224, 224, 3] and outputs a vector of shape [None, 120] where None is the batch size we specify.
Let's try our sequential model out with a single image input.
# Get a single image with a batch size of 1
single_image_input = tf.expand_dims(image_batch[0], axis=0)
# Pass the image through our model
single_image_output_sequential = sequential_model(single_image_input)
# Check the output
single_image_output_sequential
<tf.Tensor: shape=(1, 120), dtype=float32, numpy=
array([[0.00783153, 0.01119391, 0.00476165, 0.0072348 , 0.00766934,
0.00753752, 0.00522398, 0.02337082, 0.00579716, 0.00539333,
0.00549823, 0.01011768, 0.00610076, 0.0109506 , 0.00540159,
0.0079683 , 0.01227358, 0.01056393, 0.00507148, 0.00996652,
0.00604106, 0.00729022, 0.0155036 , 0.00745004, 0.00628229,
0.00796217, 0.00905823, 0.00712278, 0.01243507, 0.006427 ,
0.00602891, 0.01276839, 0.00652441, 0.00842482, 0.01247454,
0.00749902, 0.01086363, 0.007803 , 0.0058652 , 0.00474356,
0.00902809, 0.00715358, 0.00981051, 0.00444271, 0.01031628,
0.00691859, 0.00699083, 0.0065892 , 0.00966169, 0.01177148,
0.00908043, 0.00729699, 0.00496712, 0.00509035, 0.00584058,
0.01068885, 0.00817651, 0.00602052, 0.00901201, 0.01008151,
0.00495409, 0.01285929, 0.00480146, 0.0108622 , 0.01421483,
0.00814719, 0.00910061, 0.00798947, 0.00789293, 0.00636969,
0.00656019, 0.01309155, 0.00754355, 0.00702062, 0.00485884,
0.00958675, 0.01086809, 0.00682202, 0.00923016, 0.00856321,
0.00482627, 0.01234931, 0.01140433, 0.00771413, 0.01140642,
0.00382939, 0.00891482, 0.00409833, 0.00771865, 0.00652135,
0.00668143, 0.00935989, 0.00784146, 0.00751913, 0.00785116,
0.00794632, 0.0079146 , 0.00798953, 0.01011222, 0.01318719,
0.00721227, 0.00736159, 0.01369175, 0.01087009, 0.00510072,
0.00843218, 0.00451756, 0.00966478, 0.01013771, 0.00715721,
0.00367131, 0.00825834, 0.00832634, 0.01225684, 0.00724481,
0.00670675, 0.00536995, 0.01070637, 0.00937007, 0.00998812]],
dtype=float32)>
Nice!
Our model has output a tensor of prediction probabilities in shape [1, 120], one value for each our dog classes.
Thanks to the softmax function, all of these values are between 0 and 1 and they should all add up to 1 (or close to it).
# Sum the output
np.sum(single_image_output_sequential)
1.0
Beautiful!
Now how do we figure out which of the values our model thinks is most likely?
We take the index of the highest value!
We can find the index of the highest value using tf.argmax() or np.argmax().
We'll get the highest value (not the index) alongside it.
Let's try.
# Find the index with the highest value
highest_value_index_sequential_model_output = np.argmax(single_image_output_sequential)
highest_value_sequential_model_output = np.max(single_image_output_sequential)
print(f"Highest value index: {highest_value_index_sequential_model_output} ({dog_names[highest_value_index_sequential_model_output]})")
print(f"Prediction probability: {highest_value_sequential_model_output}")
Highest value index: 7 (basenji) Prediction probability: 0.023370817303657532
Note: these values may change every time due to the model/data being randomly initalized, don't worry too much about them being different, in machine learning randomness is a good thing.
This prediction probability value is quite low.
With the highest potential value being 1.0, it means the model isn't very confident on its prediction.
Let's check the original label value of our single image.
# Check the original label value
print(f"Predicted value: {highest_value_index_sequential_model_output}")
print(f"Actual value: {tf.argmax(label_batch[0]).numpy()}")
Predicted value: 7 Actual value: 95
Oh no! Looks like our model predicted the wrong label (or if it got it right, it was by pure chance).
This is to be expected.
As although our model comes with pretrained parameters from ImageNet, the dense layer we added on the end is initialized with random parameters.
So in essence, our model is randomly guessing what the label should be.
How do we fix this?
We can train the model to adjust its trainable parameters to better suit the data we're working with.
For completeness let's check out the text-based label our model predicted versus the original label.
# Index on class_names with our model's highest prediction probability
sequential_model_predicted_label = class_names[tf.argmax(sequential_model(tf.expand_dims(image_batch[0], axis=0)), axis=1).numpy()[0]]
# Get the truth label
single_image_ground_truth_label = class_names[tf.argmax(label_batch[0])]
# Print predicted and ground truth labels
print(f"Sequential model predicted label: {sequential_model_predicted_label}")
print(f"Ground truth label: {single_image_ground_truth_label}")
Sequential model predicted label: basenji Ground truth label: schipperke
Creating a model with the Functional API¶
As mentioned before, the Keras Functional API is a way/design pattern for creating more complex models.
It can include multiple different modelling steps.
But it can also be used for simple models.
And it's the way we'll construct our Dog Vision models going forward.
Let's recreate our sequential_model using the Functional API.
We'll follow the same process as mentioned before:
- Define the input layer(s).
- Define the middle/hidden layer(s).
- Define the output layer(s).
- Bonus: Connect the inputs and outputs within an instance of
tf.keras.Model().
# 1. Create input layer
inputs = tf.keras.Input(shape=INPUT_SHAPE)
# 2. Create hidden layer
x = base_model(inputs, training=False)
# 3. Create the output layer
outputs = tf.keras.layers.Dense(units=len(class_names), # one output per class
activation="softmax",
name="output_layer")(x)
# 4. Connect the inputs and outputs together
functional_model = tf.keras.Model(inputs=inputs,
outputs=outputs,
name="functional_model")
# Get a model summary
functional_model.summary()
Model: "functional_model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_4 (InputLayer) [(None, 224, 224, 3)] 0
efficientnetv2-b0 (Functio (None, 1280) 5919312
nal)
output_layer (Dense) (None, 120) 153720
=================================================================
Total params: 6073032 (23.17 MB)
Trainable params: 153720 (600.47 KB)
Non-trainable params: 5919312 (22.58 MB)
_________________________________________________________________
Functional model created!
Let's try it out.
It works in the same fashion as our sequential_model.
# Pass a single image through our functional_model
single_image_output_functional = functional_model(single_image_input)
# Find the index with the highest value
highest_value_index_functional_model_output = np.argmax(single_image_output_functional)
highest_value_functional_model_output = np.max(single_image_output_functional)
highest_value_index_functional_model_output, highest_value_functional_model_output
(69, 0.017855722)
Nice!
Looks like we got a slightly different value to our sequential_model (or they may be the same if randomness wasn't so random).
Why is this?
Because our functional_model was initialized with a random tf.keras.layers.Dense layer as well.
So the outputs of our functional_model are essentially random as well (neural networks start with random numbers and adjust them to better represent patterns in data).
Not to fear, we'll fix this soon when we train our model.
Right now we've created our model with a few scattered lines of code.
How about we functionize the model creation so we can repeat it later on?
Functionizing model creation¶
We've created two different kinds of models so far.
Each of which use the same layers.
Except one was with the Keras Sequential API and the other was with the Keras Functional API.
However, it would be quite tedious to rewrite that modelling code every time we wanted to create a new model.
So let's create a function called create_model() to replicate the model creation step with the Functional API.
Note: We're focused on the Functional API since it takes a bit more practice than the Sequential API.
def create_model(include_top: bool = False,
num_classes: int = 1000,
input_shape: tuple[int, int, int] = (224, 224, 3),
include_preprocessing: bool = True,
trainable: bool = False,
dropout: float = 0.2,
model_name: str = "model") -> tf.keras.Model:
"""
Create an EfficientNetV2 B0 feature extractor model with a custom classifier layer.
Args:
include_top (bool, optional): Whether to include the top (classifier) layers of the model.
num_classes (int, optional): Number of output classes for the classifier layer.
input_shape (tuple[int, int, int], optional): Input shape for the model's images (height, width, channels).
include_preprocessing (bool, optional): Whether to include preprocessing layers for image normalization.
trainable (bool, optional): Whether to make the base model trainable.
dropout (float, optional): Dropout rate for the global average pooling layer.
model_name (str, optional): Name for the created model.
Returns:
tf.keras.Model: A TensorFlow Keras model with the specified configuration.
"""
# Create base model
base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(
include_top=include_top,
weights="imagenet",
input_shape=input_shape,
include_preprocessing=include_preprocessing,
pooling="avg" # Can use this instead of adding tf.keras.layers.GlobalPooling2D() to the model
# pooling="max" # Can use this instead of adding tf.keras.layers.MaxPooling2D() to the model
)
# Freeze the base model (if necessary)
base_model.trainable = trainable
# Create input layer
inputs = tf.keras.Input(shape=input_shape, name="input_layer")
# Create model backbone (middle/hidden layers)
x = base_model(inputs, training=trainable)
# x = tf.keras.layers.GlobalAveragePooling2D()(x) # note: you should include pooling here if not using `pooling="avg"`
# x = tf.keras.layers.Dropout(0.2)(x) # optional regularization layer (search "dropout" for more)
# Create output layer (also known as "classifier" layer)
outputs = tf.keras.layers.Dense(units=num_classes,
activation="softmax",
name="output_layer")(x)
# Connect input and output layer
model = tf.keras.Model(inputs=inputs,
outputs=outputs,
name=model_name)
return model
What a beautiful function!
Let's try it out.
# Create a model
model_0 = create_model(num_classes=len(class_names))
model_0.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_layer (InputLayer) [(None, 224, 224, 3)] 0
efficientnetv2-b0 (Functio (None, 1280) 5919312
nal)
output_layer (Dense) (None, 120) 153720
=================================================================
Total params: 6073032 (23.17 MB)
Trainable params: 153720 (600.47 KB)
Non-trainable params: 5919312 (22.58 MB)
_________________________________________________________________
Woohoo! Looks like it worked!
Now how about we inspect each of the layers and whether they're trainable?
for layer in model_0.layers:
print(layer.name, layer.trainable)
input_layer True efficientnetv2-b0 False output_layer True
Nice, looks like our base_model (efficientnetv2-b0) is frozen (it's not trainable).
And our output_layer is trainable.
This means we'll be reusing the patterns learned in the base_model to feed into our output_layer and then customizing those parameters to suit our own problem.
7. Model 0 - Train a model on 10% of the training data¶
We've seen our model make a couple of predictions on our data.
And so far it hasn't done so well.
This is expected though.
Our model is essentially predicting random class values given an image.
Let's change that.
How?
By training the final layer on our model to be customized to recognizing images of dogs.
We can do so via five steps:
- Creating the model - We've done this ✅.
- Compiling the model - Here's where we'll tell the model how to improve itself and how to measure its performance.
- Fitting the model - Here's where we'll show the model examples of what we'd like it to learn (e.g. batches of samples containing pairs of dog images and their breed).
- Evaluating the model - Once our model is trained on the training data, we can evaluate it on the testing data (data the model has never seen).
- Making a custom prediction - Finally, the best way to test a machine learning model is by seeing how it goes on custom data. This is where we'll try to make a prediction on our own custom images of dogs.
We'll work through each of these over the next few sections.
To begin, let's create a model.
To do so, we can use our create_model() function that we made earlier.
# 1. Create model
model_0 = create_model(num_classes=len(class_names),
model_name="model_0")
model_0.summary()
Model: "model_0"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_layer (InputLayer) [(None, 224, 224, 3)] 0
efficientnetv2-b0 (Functio (None, 1280) 5919312
nal)
output_layer (Dense) (None, 120) 153720
=================================================================
Total params: 6073032 (23.17 MB)
Trainable params: 153720 (600.47 KB)
Non-trainable params: 5919312 (22.58 MB)
_________________________________________________________________
Model created!
How about we compile it?
Compiling a model¶
After we've created a model, the next step is to compile it.
If creating a model is putting together learning blocks, compiling a model is to getting those learning blocks ready to learn.
We can compile our model_0 using the tf.keras.Model.compile() method.
There are many options we can pass to the compile() method, however, the main ones we'll be focused on are:
- The optimizer - this tells the model how to improve based on the loss value.
- The loss function - this measures how wrong the model is (e.g. how far off are its predictions from the truth, an ideal loss value is 0, meaning the model is perfectly predicting the data).
- The metric(s) - this is a human-readable value that shows how your model is performing, for example, accuracy is often used as an evaluation metric.
These three settings work together to help improve a model.
Which optimizer should I use?¶
An optimizer tells a model how to improve its internal parameters (weights) to hopefully improve a loss value.
In most cases, improving the loss means to minimize it (a loss value is a measure of how wrong your model's predictions are, a perfect model will have a loss value of 0).
It does this through a process called gradient descent.
The gradients needed for gradient descent are calculated through backpropagation, a method that computes the gradient of the loss function with respect to each weight in the model.
Once the gradients have been calculated, the optimizer then tries to update the model weights so that they move in the opposite direction of the gradient (if you go down the gradient of a function, you reduce its value).
If you've never heard of the above processes, that's okay.
TensorFlow implements many of them behind the scenes.
For now, the main takeaway is that neural networks learn in the following fashion:
Start with random patterns/weights -> Look at data (forward pass) -> Try to predict data (with current weights) -> Measure performance of predictions (loss function, backpropagation calculates gradients of loss with respect to weights) -> Update patterns/weights (optimizer, gradient descent adjusts weights in the opposite direction of the gradients to minimize loss) -> Look at data (forward pass) -> Try to predict data (with updated weights) -> Measure performance (loss function) -> Update patterns/weights (optimizer) -> Repeat all of the above X times.

Example of how a neural network learns (in brief). Note the cyclical nature of the learning. You can think of it as a big game of guess and check, where the guess (hopefully) get better over time.
I'll leave the intricacies of gradient descent and backpropagation to your own extra-curricula research.
We're going to focus on using the tools TensorFlow has to offer to implement this process.
As for optimizer functions, there are two main options to get started:
| Optimizer | Code |
|---|---|
| Stochastic Gradient Descent (SGD) | tf.keras.optimizers.SGD() or "sgd" for short. |
| Adam | tf.keras.optimizers.Adam() or "adam" for short. |
Why these two?
Because they're the most often used in practice (you can see this via the number of machine learning papers referencing each one on paperswithcode.com).
There are many more optimizers available in the tf.keras.optimizers module too.
The good thing about using a premade optimizer from tf.keras.optimizers is that they usually come with good starting settings.
One the main ones being the learning_rate value.
The learning_rate is one of the most important hyperparameters to set in a neural network training setup.
It determines how much of a step change the optimizer will adjust your models weights every iteration.
Too low and the model won't learn.
Too high and the model will try to take too big of steps.
By default, TensorFlow sets the learning rate of the Adam optimizer to 0.001 (tf.keras.optimizers.Adam(learning_rate=0.001)) which is a good setting for many problems to get started with.
We can also set this default with the shortcut optimizer="adam".
For more on finding the optimal learning rate, try searching for "finding the optimal learning rate for neural networks".
# Create optimizer (short version)
optimizer = "adam"
# The above line is the same as below
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
optimizer
<keras.src.optimizers.adam.Adam at 0x7f3bb4107040>
Which loss function should I use?¶
A loss function measures how wrong your model's predictions are.
A model with poor predictions in comparison to the truth data will have a high loss value.
Where as a model with perfect predictions (e.g. it gets every prediction correct) will have a loss value of 0.
Different problems have different loss functions.
Some of the most common ones include:
| Loss Function | Problem Type | Code |
|---|---|---|
| Mean Absolute Error (MAE) | Regression (predicting a number) | tf.keras.losses.MeanAbsoluteError or "mae" for short |
| Mean Squared Error (MSE) | Regression (predicting a number) | tf.keras.losses.MeanSquaredError |
| Binary Cross Entropy (BCE) | Binary classification | tf.keras.losses.BinaryCrossentropy |
| Categorical Cross Entropy | Multi-class classification | tf.keras.losses.CategoricalCrossentropy if your labels are one-hot encoded (e.g. [0, 0, 0, 0, 1, 0...]) ortf.keras.losses.SparseCategoricalCrossentropy if your labels are integers (e.g. [[1], [23], [43], [16]...]) |
In our case, since we're working with multi-class classification (multiple different dog breeds) and our labels are one-hot encoded, we'll be using tf.keras.losses.CategoricalCrossentropy.
We can leave all of the default parameters as they are as well.
However, if we didn't have activation="softmax" in the final layer of our model, we'd have to change from_logits=False to from_logits=True as the softmax activation function does this conversion for us.
There are more loss functions than the ones we've discussed and you can see many of them on paperswithcode.com.
TensorFlow also has many more loss function implementations available in tf.keras.losses.
Let's check out a single sample of our labels to make sure they're one-hot encoded.
# Check that our labels are one-hot encoded
label_batch[0]
<tf.Tensor: shape=(120,), dtype=float32, numpy=
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0.], dtype=float32)>
Excellent! Looks like our labels are indeed one-hot encoded.
Now let's create our loss function as tf.keras.losses.CategoricalCrossentropy(from_logits=False) or "categorical_crossentropy" for short.
We set from_logits=False (this is the default) because our model uses activation="softmax" in the final layer so it's outputing prediction probabilities rather than logits (without activation="softmax" the outputs of our model would be referred to as logits, I'll leave this for extra-curricula investigation).
# Create our loss function
loss = tf.keras.losses.CategoricalCrossentropy(from_logits=False) # use from_logits=False if using an activation function in final layer of model (default)
loss
<keras.src.losses.CategoricalCrossentropy at 0x7f3bb4107430>
Which mertics should I use?¶
The evaluation metric is a human-readable value which is used to see how well your model is performing.
A slightly confusing concept is that the evaluation metric and loss function can be the same equation.
However, the main difference between a loss function and an evaluation metric is that the loss function will typically be differentiable (there are some exceptions to the rule but in most cases, the loss function will be differentiable).
Whereas, the evaluation metric does not have to be differtiable.
In the case of regression (predicting a number), your loss function and evaluation metric could be mean squared error (MSE).
Whereas in the case of classification, your loss function will generally be binary crossentropy (for two classes) or categorical crossentropy (for multiple classes) and your evalaution metric(s) could be accuracy, F1-score, precision and/or recall.
TensorFlow provides many pre-built metrics in the tf.keras.metrics module.
| Evaluation Metric | Problem Type | Code |
|---|---|---|
| Accuracy | Classification | tf.keras.metrics.Accuracy or "accuracy" for short |
| Precision | Classification | tf.keras.metrics.Precision |
| Recall | Classification | tf.keras.metrics.Recall |
| F1 Score | Classification | tf.keras.metrics.F1Score |
| Mean Squared Error (MSE) | Regression | tf.keras.metrics.MeanSquaredError or "mse" for short |
| Mean Absolute Error (MAE) | Regression | tf.keras.metrics.MeanAbsoluteError or "mae" |
| Area Under the ROC Curve (AUC-ROC) | Binary Classification | tf.keras.metrics.AUC with curve='ROC' |
The tf.keras.Model.compile() method expects the metrics parameter input as a list.
Since we're working with a classification problem, let's setup our evaluation metric as accuracy.
# Create list of evaluation metrics
metrics = ["accuracy"]
Learn more on how a model learns¶
We've breifly touched on optimizers, loss functions, gradient descent and backpropagation, the backbone of neural network learning, however, for a more in-depth look at each of these, I'd check out the following:
- 3Blue1Brown's series on Neural Networks - a fantastic 4 part video series on how neural networks are built to how they learn through gradient descent and backpropagation.
- The Little Book of Deep Learning by François Fleuret - a free ~150 page booklet on the ins and outs of deep learning. The notation may be intimidating at first but with practice you will begin to understand it.
Putting it all together and compiling our model¶
Phew!
We've now been through all the main steps in compiling a model:
- Creating the optimizer.
- Creating the loss function.
- Creating the evaluation metrics.
Now let's put everything we've done together and compile our model_0.
First we'll do it with shortcuts (e.g. "accuracy") then we'll do it with specific classes.
# Compile model with shortcuts (faster to write code but less customizable)
model_0.compile(optimizer="adam",
loss="categorical_crossentropy",
metrics=["accuracy"])
# Compile model with classes (will do the same as above)
model_0.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss=tf.keras.losses.CategoricalCrossentropy(from_logits=False),
metrics=["accuracy"])
Fitting a model on the data¶
Model created and compiled!
Time to fit it to the data.
This means we're going to pass all of the data we have (dog images and their assigned labels) through our model and ask it to try and learn the relationship between the images and the labels.
Fitting the model is step 3 in our list:
- Creating the model - We've done this ✅.
- Compiling the model - We've done this ✅.
- Fitting the model - Here's where we'll show the model examples of what we'd like it to learn (e.g. the relationship between an image of a dog and its breed).
- Evaluating the model - Once our model is trained on the training data, we can evaluate it on the testing data (data the model has never seen).
- Making a custom prediction - Finally, the best way to test a machine learning model is by seeing how it goes on custom data. This is where we'll try to make a prediction on our own custom images of dogs.
We can fit our model_0 instance with the tf.keras.Model.fit() method.
The main parameters of the fit() method we'll be paying attention to are:
x= What data do you want the model to train on?y= What labels do you want your model to learn the patterns from your data to?batch_size= The number of samples your model will look at per gradient update (e.g. 32 samples at a time before updating its internal patterns).epochs= How many times do you want the model to go through all samples (e.g.epochs=5means looking at all of the data 5 times)?validation_data= What data do you want to evaluate your model's learning on?
There are plenty more options in the TensorFlow/Keras documentation for the fit() method.
However, these options will be more than enough for us.
In our case, let's keep our experiments quick and set the following:
x=train_10_percent_ds- Since we've crafted atf.data.Dataset, ourxandyvalues are combined into one. We'll also start by training on 10% of the data for quicker experimentation (if things work on a smaller subset of the data, we can always increase it).epochs=5- The more epochs you do, the more opportunities your model has to learn patterns, however, it also prolongs training.validation_data=test_ds- We'll evaluate the model's learning on the test dataset (samples its never seen before).
Let's do it!
Time to train our first neural network and bring Dog Vision 🐶👁️ to life!
Note: If you don't have a GPU here, training will likely take a considerably long time. You can activate a GPU in Google Colab by going to Runtime -> Change runtime type -> Hardware accelerator -> GPU. Note that changing a runtime type will mean you will have to restart your runtime and rerun all of the cells above.
# Fit model_0 for 5 epochs
epochs = 5
history_0 = model_0.fit(x=train_10_percent_ds,
epochs=epochs,
validation_data=test_ds)
Epoch 1/5 38/38 [==============================] - 27s 482ms/step - loss: 3.9758 - accuracy: 0.3000 - val_loss: 3.0500 - val_accuracy: 0.5415 Epoch 2/5 38/38 [==============================] - 14s 379ms/step - loss: 2.0531 - accuracy: 0.8008 - val_loss: 1.8650 - val_accuracy: 0.7041 Epoch 3/5 38/38 [==============================] - 14s 375ms/step - loss: 1.0491 - accuracy: 0.9025 - val_loss: 1.3060 - val_accuracy: 0.7548 Epoch 4/5 38/38 [==============================] - 14s 373ms/step - loss: 0.6138 - accuracy: 0.9483 - val_loss: 1.0317 - val_accuracy: 0.7910 Epoch 5/5 38/38 [==============================] - 14s 373ms/step - loss: 0.4157 - accuracy: 0.9683 - val_loss: 0.8927 - val_accuracy: 0.8044
Woah!!!
Looks like our model performed outstandingly well!
Achieving a validation accuracy of ~80% after just 5 epochs of training.
That's far better than the original Stanford Dogs paper results of 22% accuracy.
How?
That's the power of transfer learning (and a series of modern updates to neural network architectures, hardware and training regimes)!
But these are just numbers on a page.
We'll get more in-depth on evaluations shortly.
For now, let's do a recap on the 3 steps we've practiced: create, compile, fit.
8. Putting it all together: create, compile, fit¶
Let's practice what we've done so far to train our first neural network.
Specifically, we're going to:
- Create a model (using our
create_model()) function. - Compile our model (selecting our optimizer, loss function and evaluation metric).
- Fit our model (get it to figure out the patterns bettwen images and labels).
And later on, we'll get to the other steps of evaluation and making custom predictions.
# 1. Create a model
model_0 = create_model(num_classes=len(dog_names))
# 2. Compile the model
model_0.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss="categorical_crossentropy",
metrics=["accuracy"])
# 3. Fit the model
epochs = 5
history_0 = model_0.fit(x=train_10_percent_ds,
epochs=epochs,
validation_data=test_ds)
Epoch 1/5 38/38 [==============================] - 22s 418ms/step - loss: 3.9263 - accuracy: 0.3225 - val_loss: 2.9969 - val_accuracy: 0.5549 Epoch 2/5 38/38 [==============================] - 14s 379ms/step - loss: 1.9899 - accuracy: 0.7900 - val_loss: 1.8436 - val_accuracy: 0.7063 Epoch 3/5 38/38 [==============================] - 14s 380ms/step - loss: 1.0152 - accuracy: 0.9058 - val_loss: 1.2817 - val_accuracy: 0.7702 Epoch 4/5 38/38 [==============================] - 14s 376ms/step - loss: 0.5997 - accuracy: 0.9483 - val_loss: 1.0173 - val_accuracy: 0.7945 Epoch 5/5 38/38 [==============================] - 14s 374ms/step - loss: 0.4040 - accuracy: 0.9708 - val_loss: 0.8792 - val_accuracy: 0.8107
Nice! We just trained our second neural network!
We practice these steps because they will be part of many of your future machine learning workflows.
As an extension, you could create a function called create_and_compile() which does the first two steps in one hit.
Now we've got a trained model, let's get to evaluating it.
Evaluate Model 0 on the test data¶
Alright, the next step in our journey is to evaluate our trained model.
In fact, evaluating a model is just as important as training a model.
There are several ways to evaluate a model:
- Look at the metrics (such as accuracy).
- Plot the loss curves.
- Make predictions on the test set and compare them to the truth labels.
- Make predictions on custom samples (not contained in the training or test sets).
We've done the first one, as these metrics were the outputs of our model training.
Now we're going to focus on the next two.
Plotting loss curves and making predictions on the test set.
We'll get to custom images later on.
So what are loss curves?
Loss curves are a visualization of how your model's loss value performs overtime.
We say loss "curves" because you can have a loss curve for each dataset, training, validation and test.
An ideal loss curve will start high and move towards zero (a perfect model will have a loss value of zero).
How do we get a loss curve?
We could manually plot the loss values output from our model training.
Or we could programmatically get the values thanks to the History object.
This object is returned by the fit method of tf.keras.Model instances.
And we've already got one!
It's saved to history_0 (the model history for model_0).
The History.history attribute contains a record of the training loss values and evaluation metrics for each epoch.
Let's check it out.
# Inspect History.history attribute for model_0
history_0.history
{'loss': [3.926330089569092,
1.9898805618286133,
1.0152279138565063,
0.599678099155426,
0.4040333032608032],
'accuracy': [0.32249999046325684,
0.7900000214576721,
0.9058333039283752,
0.9483333230018616,
0.9708333611488342],
'val_loss': [2.996889591217041,
1.8436286449432373,
1.2817054986953735,
1.0173338651657104,
0.8792150616645813],
'val_accuracy': [0.5548951029777527,
0.7062937021255493,
0.7701631784439087,
0.7945221662521362,
0.8107225894927979]}
Wonderful!
We've got a history of our model training over time.
It looks like everything is moving in the right direction.
Loss is going down whilst accuracy is going up.
How about we adhere to the data explorer's motto and write a function to visualize, visualize, visualize!
We'll call the function plot_model_loss_curves() and it'll take a History.history object as input and then plot loss and accuracy curves using matplotlib.
def plot_model_loss_curves(history: tf.keras.callbacks.History) -> None:
"""Takes a History object and plots loss and accuracy curves."""
# Get the accuracy values
acc = history.history["accuracy"]
val_acc = history.history["val_accuracy"]
# Get the loss values
loss = history.history["loss"]
val_loss = history.history["val_loss"]
# Get the number of epochs
epochs_range = range(len(acc))
# Create accuracy curves plot
plt.figure(figsize=(14, 7))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label="Training Accuracy")
plt.plot(epochs_range, val_acc, label="Validation Accuracy")
plt.legend(loc="lower right")
plt.title("Training and Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
# Create loss curves plot
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label="Training Loss")
plt.plot(epochs_range, val_loss, label="Validation Loss")
plt.legend(loc="upper right")
plt.title("Training and Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.show()
plot_model_loss_curves(history=history_0)

Woohoo! Now those are some nice looking curves.
Our model is doing exactly what we'd like it to do.
The accuracy is moving up while the loss is going down.
Overfitting and underfitting (when your model doesn't perform how you'd like)¶
You may be wondering why there's a gap between the training and validation loss curves.
Ideally, the two lines would closely follow each other.
In our case, the validation loss doesn't decrease as low as the training loss.
This is known as overfitting, a common problem in machine learning where a model learns the training data very well but doesn't generalize to other unseen data.
You can think of this as a university student memorizing the course materials but failing to apply that knowledge to problems that aren't in the course materials (real-world problems).
The reverse of overfitting is underfitting, which is when a model fails to learn anything useful. For example, it never manages to increase accuracy or decrease loss.
Good news is, our model isn't underfitting (it's performing at ~80% accuracy on unseen data).
I'll leave "ways to fix overfitting" as an extension.
But one of the best ways is to use more data.
And guess what?
We've got plenty more!
Reminder, these results were achieved using only 10% of the training data.
Before we train a model with more data, there's another way to quickly evaluate our model on a given dataset.
And that's using the tf.keras.Model.evaluate() method.
How about we try it on our model_0?
We'll save the outputs to a model_0_results variable so we can use them later.
# Evaluate model_0, see: https://www.tensorflow.org/api_docs/python/tf/keras/Model#evaluate
model_0_results = model_0.evaluate(x=test_ds)
model_0_results
269/269 [==============================] - 13s 47ms/step - loss: 0.8792 - accuracy: 0.8107
[0.8792150616645813, 0.8107225894927979]
Beautiful!
Evaluating our model on the test data shows it's performing at ~80% accuracy despite only seeing 10% of the training data.
We can also get the metrics used by our model with the metrics_names attribute.
# Get our model's metrics names
model_0.metrics_names
['loss', 'accuracy']
9. Model 1 - Train a model on 100% of the training data¶
Time to step it up a notch!
We've trained a model on 10% of the training data (to see if it works and it did!), now let's train a model on 100% of the training data and see what happens.
But before we do...
What do you think will happen?
If our model was able to perform well on only 10% of the data, how do you think it will go on 100% of the data?
These types of questions are good to think about in the world of machine learning.
After all, that's why the machine learner's motto is experiment, experiment, experiment!
Let's follow our three steps from before:
- Create a model (using our
create_model()) function. - Compile our model (selecting our optimizer, loss function and evaluation metric).
- Fit our model (this time on 100% of the data for 5 epochs).
Note: Fitting our model on such a large amount of data will take a long time without a GPU. If you're using Google Colab, you can access a GPU via Runtime -> Change runtime type -> Hardware accelerator -> GPU.
# 1. Create model_1 (the next iteration of model_0)
model_1 = create_model(num_classes=len(class_names),
model_name="model_1")
# 2. Compile model
model_1.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001),
loss="categorical_crossentropy",
metrics=["accuracy"])
# 3. Fit model
epochs=5
history_1 = model_1.fit(x=train_ds,
epochs=epochs,
validation_data=test_ds)
Epoch 1/5 375/375 [==============================] - 43s 84ms/step - loss: 1.2725 - accuracy: 0.7607 - val_loss: 0.4849 - val_accuracy: 0.8756 Epoch 2/5 375/375 [==============================] - 30s 80ms/step - loss: 0.3667 - accuracy: 0.9013 - val_loss: 0.4041 - val_accuracy: 0.8770 Epoch 3/5 375/375 [==============================] - 30s 79ms/step - loss: 0.2641 - accuracy: 0.9287 - val_loss: 0.3731 - val_accuracy: 0.8832 Epoch 4/5 375/375 [==============================] - 30s 80ms/step - loss: 0.2043 - accuracy: 0.9483 - val_loss: 0.3708 - val_accuracy: 0.8819 Epoch 5/5 375/375 [==============================] - 30s 80ms/step - loss: 0.1606 - accuracy: 0.9633 - val_loss: 0.3753 - val_accuracy: 0.8767
Woah!
Was your intuition correct?
Did what you thought would happen actually happen?
It looks like all that extra data helped our model quite a bit, it's now performing at close to ~90% accuracy on the test set!
Question: How many epochs should I fit for?
Generally with transfer learning you can get pretty good results quite quickly, however, you may want to look into training for longer (more epochs) as an experiment to see whether your model improves or not. What we've performed is a transfer learning technique called feature extraction, however, you may want to look further into fine-tuning (training the whole model to your own dataset) whole model and using callbacks (functions that take place during model training) such as Early Stopping to prevent the model from training so long its performance begins to degrade.
Evaluate Model 1 on the test data¶
How about we evaluate our model_1?
Let's first by plotting loss curves with the data contained within history_1.
# Plot model_1 loss curves
plot_model_loss_curves(history=history_1)

Hmm, looks like our model performed well, however the validation accuracy and loss seemed to flatten out.
Whereas, the training accuracy and loss seemed to keep improving.
This is a sign of overfitting (model performing much better on the training set than the validation/test set).
However, since our model looks to be performing quite well I'll leave this overfitting problem as a research project for extra-curriculum.
For now, let's evaluate our model on the test dataset using the evaluate() method.
# Evaluate model_1
model_1_results = model_1.evaluate(test_ds)
269/269 [==============================] - 12s 46ms/step - loss: 0.3753 - accuracy: 0.8767
Nice!
Looks like that extra data boosted our models performance from ~80% on the test set to ~90% on test set (note: exact numbers here may vary due to the inherit randomness in machine learning models).
Extension: Putting it all together
As a potential extension, you may want to try practicing putting all of the steps we've been through so far together. As in, loading the data, creating the model, compiling the model, fitting the model and evaluating the model. That's what I've found is one of the best ways to learn ML problems, replicating a system end to end.
10. Make and evaluate predictions of the best model¶
Now we've trained a model, it's time to make predictions with it!
That's the whole goal of machine learning.
Train a model on existing data, to make predictions on new data.
Our test data is supposed to simulate new data, data our model has never seen before.
We can make predictions with the tf.keras.Model.predict() method, passing it our test_ds (short for test dataset) variable.
# This will output logits (as long as softmax activation isn't in the model)
test_preds = model_1.predict(test_ds)
# Note: If not using activation="softmax" in last layer of model, may need to turn them into prediction probabilities (easier to understand)
# test_preds = tf.keras.activations.softmax(tf.constant(test_preds), axis=-1)
269/269 [==============================] - 13s 44ms/step
Let's inspect our test_preds by first checking its shape.
test_preds.shape
(8580, 120)
Okay, looks like our test_pred variable contains 8580 values (one for each test sample) with 120 elements (one value for each dog class).
Let's inspect a single test prediction and see what it looks like.
# Get a "random" variable between all of the test samples
random.seed(42)
random_test_index = random.randint(0, test_preds.shape[0] - 1)
print(f"[INFO] Random test index: {random_test_index}")
# Inspect a single test prediction sample
random_test_pred_sample = test_preds[random_test_index]
print(f"[INFO] Random test pred sample shape: {random_test_pred_sample.shape}")
print(f"[INFO] Random test pred sample argmax: {tf.argmax(random_test_pred_sample)}")
print(f"[INFO] Random test pred sample label: {dog_names[tf.argmax(random_test_pred_sample)]}")
print(f"[INFO] Random test pred sample max prediction probability: {tf.reduce_max(random_test_pred_sample)}")
print(f"[INFO] Random test pred sample prediction probability values:\n{random_test_pred_sample}")
[INFO] Random test index: 1824 [INFO] Random test pred sample shape: (120,) [INFO] Random test pred sample argmax: 24 [INFO] Random test pred sample label: brittany_spaniel [INFO] Random test pred sample max prediction probability: 0.9248308539390564 [INFO] Random test pred sample prediction probability values: [3.0155065e-06 4.2946940e-05 3.2878995e-06 3.1306336e-05 1.7298260e-06 1.3368123e-05 2.8498230e-06 6.8758955e-06 2.6828552e-06 4.6089318e-04 9.8374185e-06 1.9263330e-06 7.6487186e-07 6.1217276e-04 1.2198443e-06 5.9309714e-06 2.4797799e-05 2.5847612e-06 4.9912862e-05 3.1809162e-07 1.0326848e-06 2.7293386e-06 2.1035332e-06 5.2793930e-06 9.2483085e-01 2.6070888e-06 1.6410323e-06 1.4008251e-06 2.0515323e-05 2.1309786e-05 1.4602327e-06 3.8456672e-04 7.4974610e-05 4.4831428e-05 5.5091264e-06 2.1345174e-07 2.9732748e-06 5.5520386e-06 8.7954652e-07 1.6277906e-03 5.3978354e-02 9.6090174e-05 9.6672220e-06 4.4037843e-06 2.5557700e-05 6.3994042e-07 1.6738920e-06 4.6715216e-04 4.1448075e-06 6.4118845e-05 2.0398900e-06 3.6135450e-06 4.4963690e-05 2.8406910e-05 3.4689847e-07 6.2964758e-04 9.1336078e-05 5.2363583e-05 1.2731762e-06 2.4212743e-06 1.5872080e-06 6.3476455e-06 6.2880179e-07 6.6757898e-06 1.6635622e-06 4.3550008e-07 2.3698403e-05 1.4149221e-05 3.8156581e-05 1.0464001e-05 5.0107906e-06 1.7395665e-06 2.8848885e-07 4.2622072e-05 3.2712339e-07 1.8591476e-07 2.2874669e-05 7.9814470e-07 2.3121322e-05 1.6275973e-06 4.6186727e-07 7.6188849e-07 3.2468931e-06 3.1449999e-05 2.9600946e-05 3.8992380e-06 2.8564186e-06 4.1459539e-06 6.0877244e-07 2.5443229e-05 5.4467969e-06 5.4184858e-07 2.8361776e-04 9.0548929e-05 8.8840829e-07 9.1714105e-07 1.9990568e-07 1.7958368e-05 7.7042150e-06 2.4126435e-05 1.9759838e-05 8.2941342e-06 2.5857928e-05 6.1904398e-06 1.4601937e-06 1.5800337e-05 6.0928446e-06 5.0209674e-05 1.4067524e-05 2.3544631e-05 1.4134421e-06 9.8844721e-05 9.1535941e-05 2.4448002e-03 5.8540131e-06 1.2547853e-02 1.3779800e-05 8.0164841e-07 2.5093528e-05 3.7180773e-05]
Okay looks like each individual sample of our test predictions is a tensor of prediction probabilities.
In essence, each element is a probability between 0 and 1 as to how confident our model is whether the prediction is correct or not.
A prediction probability of 1 means the model is 100% confident the given sample belongs to that class.
A prediction probability of 0 means the model isn't assigning any value value to that class at all.
And then all the other values fill in between.
Note: Just because a model's prediction probability for a particular sample is closer to 1 on a certain class (e.g. 0.9999) doesn't mean it is correct. A prediction can have a high probability but still be incorrect. We'll see this later on in the "most wrong" section.
The maximum value of our prediction probabilities tensor is what the model considers is the most likely prediction given the specific sample.
We take the index of the maximum value (using tf.argmax) and index on the list of dog names to get the predicted class name.
Note:
tf.argmaxor "argmax" for short gets the index of where the maximum value occurs in a tensor along a specified dimension. We can usetf.reduce_maxto get the maximum value itself.
To make our predictions easier to compare to the test dataset, let's unbundle our test_ds object into two separate arrays called test_ds_images and test_ds_labels.
We can do this by looping through the samples in our test_ds object and appending each to a list (we'll do this with a list comprehension).
Then we can join those lists together into an array with np.concatenate.
import numpy as np
# Extract test images and labels from test_ds
test_ds_images = np.concatenate([images for images, labels in test_ds], axis=0)
test_ds_labels = np.concatenate([labels for images, labels in test_ds], axis=0)
# How many images and labels do we have?
len(test_ds_images), len(test_ds_labels)
(8580, 8580)
Perfect!
Now we've got a way to compare our predictions on a given image (in test_ds_images) to its appropriate label in test_ds_labels.
This is one of the main reasons we didn't shuffle the test dataset.
Because now our predictions tensor has the same indexes as our test_ds_images and test_ds_labels arrays.
Meaning if we chose to compare sample number 42, everything would line up.
In fact, let's try just that.
# Set target index
target_index = 42 # try changing this to another value and seeing how the model performs on other samples
# Get test image
test_image = test_ds_images[target_index]
# Get truth label (index of max in test label)
test_image_truth_label = class_names[tf.argmax(test_ds_labels[target_index])]
# Get prediction probabilities
test_image_pred_probs = test_preds[target_index]
# Get index of class with highest prediction probability
test_image_pred_class = class_names[tf.argmax(test_image_pred_probs)]
# Plot the image
plt.figure(figsize=(5, 4))
plt.imshow(test_image.astype("uint8"))
# Create sample title with prediction probability value
title = f"""True: {test_image_truth_label}
Pred: {test_image_pred_class}
Prob: {np.max(test_image_pred_probs):.2f}"""
# Colour the title based on correctness of pred
plt.title(title,
color="green" if test_image_truth_label == test_image_pred_class else "red")
plt.axis("off");

Woohoo!!! Look at that!
Looks like our model got the prediction right, according to the test data, sample number 42 is in fact an Affenpinscher.
Doing a quick search on Google for Affenpinscher seems to return similar looking dogs too.
Our model is working!
For sample 42 at least...
As an exercise you could try to change the target index above, perhaps to your favourite number and see how the model goes.
But we could also write some code to test a number of different samples at a time.
Visualizing predictions from our best trained model¶
We could sit there looking at single image predictions of dogs all day.
Or we could write code to look at multiple at a time...
Let's do the latter!
# Choose a random 10 indexes from the test data and compare the values
import random
random.seed(42) # try changing the random seed or commenting it out for different values
random_indexes = random.sample(range(len(test_ds_images)), 10)
# Create a plot with multiple subplots
fig, axes = plt.subplots(2, 5, figsize=(15, 7))
# Loop through the axes of the plot
for i, ax in enumerate(axes.flatten()):
target_index = random_indexes[i] # get a random index (this is another reason we didn't shuffle the test set)
# Get relevant target image, label, prediction and prediction probabilities
test_image = test_ds_images[target_index]
test_image_truth_label = class_names[tf.argmax(test_ds_labels[target_index])]
test_image_pred_probs = test_preds[target_index]
test_image_pred_class = class_names[tf.argmax(test_image_pred_probs)]
# Plot the image
ax.imshow(test_image.astype("uint8"))
# Create sample title
title = f"""True: {test_image_truth_label}
Pred: {test_image_pred_class}
Prob: {np.max(test_image_pred_probs):.2f}"""
# Colour the title based on correctness of pred
ax.set_title(title,
color="green" if test_image_truth_label == test_image_pred_class else "red")
ax.axis("off")

Woah, looks like our model does quite well!
Try commenting out the random.seed() line and inspecting a few more dog photos, you might notice that model doesn't get too many wrong!
Finding the accruacy per class¶
Our model's overall accuracy is ~90%.
This is an outstanding result.
But what about the accuracy per class?
As in, how did the boxer class perform?
Or the australian_terrier?
You'll see on the original Stanford Dogs Dataset website that the authors reported the accuracy per class of each of the dog breeds. Their best performing class, african_hunting_dog achieved close to 60% accuracy (about ~58% if I'm reading the graph correctly).

Results from the original Stanford Dogs Dataset paper (2011). Let's see if the model we trained performs better than it.
How about we try and replicate the same plot with our own results?
First, let's create a DataFrame with information about our test predictions and test samples.
We'll start by getting the argmax of the test predictions as well as the test labels.
Then we'll get the maximum prediction probabilities for each sample.
And then we'll put it all into a DataFrame!
# Get argmax labels of test predictions and test ground truth
test_preds_labels = test_preds.argmax(axis=-1)
test_ds_labels_argmax = test_ds_labels.argmax(axis=-1)
# Get highest prediction probability of test predictions
test_pred_probs_max = tf.reduce_max(test_preds, axis=-1).numpy() # extract NumPy since pandas doesn't handle TensorFlow Tensors
# Create DataFram of test results
test_results_df = pd.DataFrame({"test_pred_label": test_preds_labels,
"test_pred_prob": test_pred_probs_max,
"test_pred_class_name": [class_names[test_pred_label] for test_pred_label in test_preds_labels],
"test_truth_label": test_ds_labels_argmax,
"test_truth_class_name": [class_names[test_truth_label] for test_truth_label in test_ds_labels_argmax]})
# Create a column whether or not the prediction matches the label
test_results_df["correct"] = test_results_df["test_pred_class_name"] == test_results_df["test_truth_class_name"]
test_results_df.head()
| test_pred_label | test_pred_prob | test_pred_class_name | test_truth_label | test_truth_class_name | correct | |
|---|---|---|---|---|---|---|
| 0 | 0 | 0.974350 | affenpinscher | 0 | affenpinscher | True |
| 1 | 0 | 0.694450 | affenpinscher | 0 | affenpinscher | True |
| 2 | 0 | 0.993829 | affenpinscher | 0 | affenpinscher | True |
| 3 | 44 | 0.691742 | flat_coated_retriever | 0 | affenpinscher | False |
| 4 | 0 | 0.989754 | affenpinscher | 0 | affenpinscher | True |
What a cool looking DataFrame!
Now we can perform some further analysis.
Such as getting the accuracy per class.
We can do so by grouping the test_results_df via the "test_truth_class_name" column and then taking the mean of the "correct" column.
We can then create a new DataFrame based on this view and sort the values by correctness (e.g. the classes with the highest performance should be up the top).
# Calculate accuracy per class
accuracy_per_class = test_results_df.groupby("test_truth_class_name")["correct"].mean()
# Create new DataFrame to sort classes by accuracy
accuracy_per_class_df = pd.DataFrame(accuracy_per_class).reset_index().sort_values("correct", ascending=False)
accuracy_per_class_df.head()
| test_truth_class_name | correct | |
|---|---|---|
| 10 | bedlington_terrier | 1.000000 |
| 62 | keeshond | 1.000000 |
| 30 | chow | 0.989583 |
| 92 | saint_bernard | 0.985714 |
| 2 | african_hunting_dog | 0.985507 |
Woah! Looks like we've got a fair few dog classes with close to (or exactly) 100% accuracy!
That's outstanding!
Now let's recreate the horizontal bar plot used on the original Stanford Dogs research paper page.
# Let's create a horizontal bar chart to replicate a similar plot to the original Stanford Dogs page
plt.figure(figsize=(10, 17))
plt.barh(y=accuracy_per_class_df["test_truth_class_name"],
width=accuracy_per_class_df["correct"])
plt.xlabel("Accuracy")
plt.ylabel("Class Name")
plt.title("Dog Vision Accuracy per Class")
plt.ylim(-0.5, len(accuracy_per_class_df["test_truth_class_name"]) - 0.5) # Adjust y-axis limits to reduce white space
plt.gca().invert_yaxis() # This will display the first class at the top
plt.tight_layout()
plt.show()

Goodness me!
Looks like our model performs incredibly well across all the vast majority of classes.
Comparing it to the original Stanford Dogs horizontal bar graph we can see that their best performing class got close to 60% accuracy.
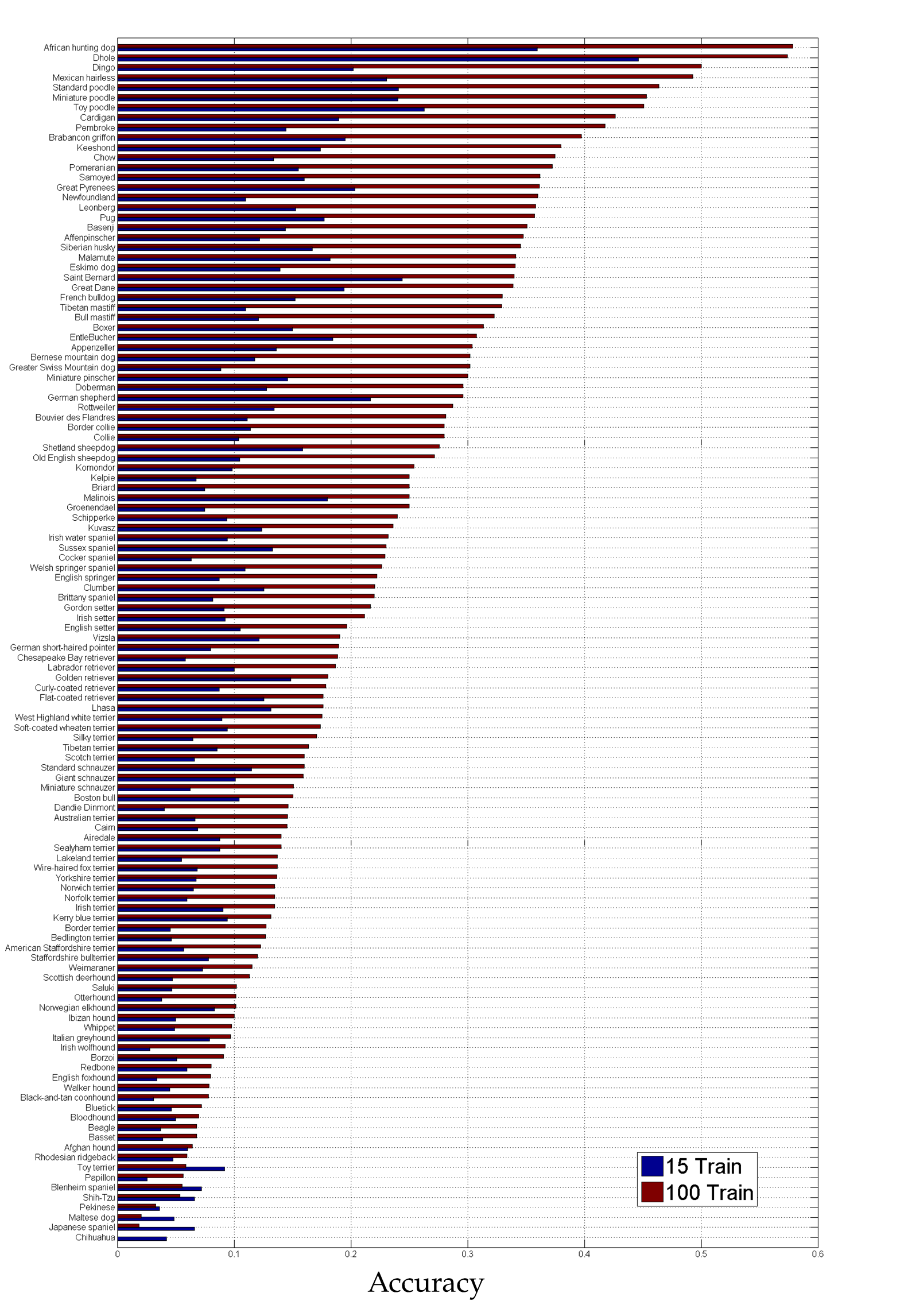{kind=link}
However, it's only when we take a look at our worst performing classes do we see a handful of classes just under 60% accuracy.
# Inspecting our worst performing classes (note how only a couple of classes perform at ~55% accuracy or below)
accuracy_per_class_df.tail()
| test_truth_class_name | correct | |
|---|---|---|
| 104 | staffordshire_bullterrier | 0.672727 |
| 76 | miniature_poodle | 0.654545 |
| 90 | rhodesian_ridgeback | 0.638889 |
| 71 | malamute | 0.615385 |
| 101 | siberian_husky | 0.271739 |
What an awesome result!
We've now replicated and even vastly improved a Stanford research paper.
You should be proud!
Now we've seen how well our model performs, how about we check where its performed poorly?
Finding the most wrong examples¶
A great way to inspect your models errors is to find the examples where the prediction had a high probability but the prediction was wrong.
This is often called the "most wrong" samples.
As in the model was very confident but wrong.
Let's filter for the top 100 most wrong by sorting the incorrect predictions by the "test_pred_prob" column.
# Get most wrong
top_100_most_wrong = test_results_df[test_results_df["correct"] == 0].sort_values("test_pred_prob", ascending=False)[:100]
top_100_most_wrong.head()
| test_pred_label | test_pred_prob | test_pred_class_name | test_truth_label | test_truth_class_name | correct | |
|---|---|---|---|---|---|---|
| 2727 | 75 | 0.997043 | miniature_pinscher | 38 | doberman | False |
| 5480 | 44 | 0.995325 | flat_coated_retriever | 78 | newfoundland | False |
| 6884 | 54 | 0.994142 | groenendael | 95 | schipperke | False |
| 4155 | 55 | 0.987126 | ibizan_hound | 60 | italian_greyhound | False |
| 1715 | 85 | 0.984834 | pekinese | 22 | brabancon_griffon | False |
One way would be to inspect these most wrong predictions would be to go through the different breeds one by one and see why the model would've confused them.
Such as comparing miniature_pinscher to doberman (two quite similar looking dog breeds).
Alternatively, we could get a random 10 samples and plot them to see what they look like.
Let's do the latter!
# Get 10 random indexes of "most wrong" predictions
top_100_most_wrong.sample(n=10).index
Index([2001, 1715, 8112, 1642, 5480, 6383, 7363, 4155, 7895, 4105], dtype='int64')
How about we plot these indexes?
# Choose a random 10 indexes from the test data and compare the values
import random
random_most_wrong_indexes = top_100_most_wrong.sample(n=10).index
# Iterate through test results and plot them
# Note: This is why we don't shuffle the test data, so that it's in original order when we evaluate it.
fig, axes = plt.subplots(2, 5, figsize=(15, 7))
for i, ax in enumerate(axes.flatten()):
target_index = random_most_wrong_indexes[i]
# Get relevant target image, label, prediction and prediction probabilities
test_image = test_ds_images[target_index]
test_image_truth_label = class_names[tf.argmax(test_ds_labels[target_index])]
test_image_pred_probs = test_preds[target_index]
test_image_pred_class = class_names[tf.argmax(test_image_pred_probs)]
# Plot the image
ax.imshow(test_image.astype("uint8"))
# Create sample title
title = f"""True: {test_image_truth_label}
Pred: {test_image_pred_class}
Prob: {np.max(test_image_pred_probs):.2f}"""
# Colour the title based on correctness of pred
ax.set_title(title,
color="green" if test_image_truth_label == test_image_pred_class else "red",
fontsize=10)
ax.axis("off")

Inspecting the "most wrong" examples, it's easy to see where the model got confused.
These samples can show us where we might want to collect more data or correct our data's labels.
Speaking of confused, how about we make a confusion matrix for further evaluation?
Create a confusion matrix¶
A confusion matrix helps to visualize which classes a predicted compared to which classes it should've predicted (truth vs. predictions).
We can create one using Scikit-Learn's sklearn.metrics.confusion_matrix and passing in our y_true and y_pred values.
And then we can display it using sklearn.metrics.ConfusionMatrixDisplay.
Note: Since we have 120 different classes, running the code bellow to show the confusion matrix plot may take a minute or so to load (it's quite a big plot!).
from sklearn.metrics import confusion_matrix, ConfusionMatrixDisplay
# Create a confusion matrix
confusion_matrix_dog_preds = confusion_matrix(y_true=test_ds_labels_argmax, # requires all labels to be in same format (e.g. not one-hot)
y_pred=test_preds_labels)
# Create a confusion matrix plot
confusion_matrix_display = ConfusionMatrixDisplay(confusion_matrix=confusion_matrix_dog_preds,
display_labels=class_names)
fig, ax = plt.subplots(figsize=(25, 25))
ax.set_title("Dog Vision Confusion Matrix")
confusion_matrix_display.plot(xticks_rotation="vertical",
cmap="Blues",
colorbar=False,
ax=ax);

Now that's one big confusion matrix!
It looks like most of the darker blue boxes are down the middle diagonal (we we'd like them to be).
But there are a few instances where the model confuses classes such as scottish_deerhound and irish_wolfhound.
And looking up those two breeds we can see that they look visually similar.
11. Save and load the best model¶
We've covered a lot of ground from loading data to training and evaluating a model.
But what if you wanted to use that model somewhere else?
Such as on a website or in an application?
The first step is saving it to file.
We can save our model using the tf.keras.Model.save() method and specifying the filepath as well as the save_format parameters.
We'll use filepath="dog_vision_model.keras" as well as save_format="keras' to save our model to the new and versatile .keras format.
Let's save our best performing model_1.
Note: You may also see models being saved with the
SavedModelformat as well asHDF5formats, however, it's recommended to use the newer.kerasformat. See the TensorFlow documentation on saving and loading a model for more.
# Save the model to .keras
model_save_path = "dog_vision_model.keras"
model_1.save(filepath=model_save_path,
save_format="keras")
Model saved!
And we can load it back in using the tf.keras.models.load_model() method.
# Load the model
loaded_model = tf.keras.models.load_model(filepath=model_save_path)
And now we can evaluate our loaded_model to make sure it performs well on the test dataset.
# Evaluate the loaded model
loaded_model_results = loaded_model.evaluate(test_ds)
269/269 [==============================] - 15s 47ms/step - loss: 0.3753 - accuracy: 0.8767
How about we check if the loaded_model_results are the same as the model_1_results?
assert model_1_results == loaded_model_results
Our trained model and loaded model results are the same!
We could now use our dog_vision_model.keras file in an application to predict a dog breed based on an image.
Note: If you're using Google Colab, remember that after a period of time if you Google Colab instance gets disconnected, it will delete all local files. So if you want to keep your
dog_vision_model.kerasbe sure to download it or copy it to Google Drive.
12. Make predictions on custom images with the best model¶
Now what fun would it be if we only made predictions on the test dataset?
How about we see how our model goes on real world images?
That's the whole goal of machine learning right? To see how your model goes in the real world?
Well, let's make some predictions on custom images!
Specifically, let's try our best model on images of my dogs (Bella 🐶 and Seven 7️⃣, yes, Seven is her actual name) and an extra wildcard image.
We can download the photos from the course GitHub.
# Download a set of custom images from GitHub and unzip them
!wget -nc https://github.com/mrdbourke/zero-to-mastery-ml/raw/master/images/dog-photos.zip
!unzip dog-photos.zip
--2024-04-26 01:43:26-- https://github.com/mrdbourke/zero-to-mastery-ml/raw/master/images/dog-photos.zip Resolving github.com (github.com)... 140.82.113.4 Connecting to github.com (github.com)|140.82.113.4|:443... connected. HTTP request sent, awaiting response... 302 Found Location: https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/images/dog-photos.zip [following] --2024-04-26 01:43:26-- https://raw.githubusercontent.com/mrdbourke/zero-to-mastery-ml/master/images/dog-photos.zip Resolving raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.108.133, 185.199.109.133, 185.199.110.133, ... Connecting to raw.githubusercontent.com (raw.githubusercontent.com)|185.199.108.133|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 1091355 (1.0M) [application/zip] Saving to: ‘dog-photos.zip’ dog-photos.zip 100%[===================>] 1.04M --.-KB/s in 0.05s 2024-04-26 01:43:27 (21.6 MB/s) - ‘dog-photos.zip’ saved [1091355/1091355] Archive: dog-photos.zip inflating: dog-photo-4.jpeg inflating: dog-photo-1.jpeg inflating: dog-photo-2.jpeg inflating: dog-photo-3.jpeg
Wonderful! We can inspect our images in the file browser and see that they're under the name dog-photo-*.jpeg.
How about we iterate through them and visualize each one?
# Create list of paths for custom dog images
custom_image_paths = ["dog-photo-1.jpeg",
"dog-photo-2.jpeg",
"dog-photo-3.jpeg",
"dog-photo-4.jpeg"]
# Iterate through list of dog images and plot each one
fig, axes = plt.subplots(1, 4, figsize=(15, 7))
for i, ax in enumerate(axes.flatten()):
ax.imshow(plt.imread(custom_image_paths[i]))
ax.axis("off")
ax.set_title(custom_image_paths[i])

What?
The first three photos look well and good but we can see dog-photo-4.jpeg is a photo of me in a black hoodie pulling a blue steel face.
We'll see why this is later.
For now, let's use our loaded_model to try and make a prediction on the first dog image (dog-photo-1.jpeg)!
We can do so with the predict() method.
# Try and make a prediction on the first dog image
loaded_model.predict("dog-photo-1.jpeg")
--------------------------------------------------------------------------- IndexError Traceback (most recent call last) <ipython-input-129-336b90293288> in <cell line: 2>() 1 # Try and make a prediction on the first dog image ----> 2 loaded_model.predict("dog-photo-1.jpeg") /usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs) 68 # To get the full stack trace, call: 69 # `tf.debugging.disable_traceback_filtering()` ---> 70 raise e.with_traceback(filtered_tb) from None 71 finally: 72 del filtered_tb /usr/local/lib/python3.10/dist-packages/tensorflow/python/framework/tensor_shape.py in __getitem__(self, key) 960 else: 961 if self._v2_behavior: --> 962 return self._dims[key] 963 else: 964 return self.dims[key] IndexError: tuple index out of range
Oh no!
We get an error:
IndexError: tuple index out of range
This is a little hard to understand. But we can see the code is trying to get the shape of our image.
However, we didn't pass an image to the predict() method.
We only passed a filepath.
Our model expects inputs in the same format it was trained on.
So let's load our image and resize it.
We can do so with tf.keras.utils.load_img().
# Load the image (into PIL format)
custom_image = tf.keras.utils.load_img(
path="dog-photo-1.jpeg",
color_mode="rgb",
target_size=IMG_SIZE, # (224, 224) or (img_height, img_width)
)
type(custom_image), custom_image
(PIL.Image.Image, <PIL.Image.Image image mode=RGB size=224x224>)
Excellent, we've loaded our first custom image.
But now let's turn our image into a tensor (our model was trained on image tensors, so it expects image tensors as input).
We can convert our image from PIL format to array format with tf.keras.utils.img_to_array().
# Turn the image into a tensor
custom_image_tensor = tf.keras.utils.img_to_array(custom_image)
custom_image_tensor.shape
(224, 224, 3)
Nice! We've got an image tensor of shape (224, 224, 3).
How about we make a prediction on it?
# Make a prediction on our custom image tensor
loaded_model.predict(custom_image_tensor)
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-132-bd82d1e41fed> in <cell line: 2>() 1 # Make a prediction on our custom image tensor ----> 2 loaded_model.predict(custom_image_tensor) /usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs) 68 # To get the full stack trace, call: 69 # `tf.debugging.disable_traceback_filtering()` ---> 70 raise e.with_traceback(filtered_tb) from None 71 finally: 72 del filtered_tb /usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py in tf__predict_function(iterator) 13 try: 14 do_return = True ---> 15 retval_ = ag__.converted_call(ag__.ld(step_function), (ag__.ld(self), ag__.ld(iterator)), None, fscope) 16 except: 17 do_return = False ValueError: in user code: File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 2440, in predict_function * return step_function(self, iterator) File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 2425, in step_function ** outputs = model.distribute_strategy.run(run_step, args=(data,)) File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 2413, in run_step ** outputs = model.predict_step(data) File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 2381, in predict_step return self(x, training=False) File "/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py", line 70, in error_handler raise e.with_traceback(filtered_tb) from None File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/input_spec.py", line 298, in assert_input_compatibility raise ValueError( ValueError: Input 0 of layer "model_1" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(32, 224, 3)
What?!?
We get another error...
ValueError: Input 0 of layer "model_1" is incompatible with the layer: expected shape=(None, 224, 224, 3), found shape=(32, 224, 3)
Hmm.
Looks like our model is expecting a batch size dimension on our input tensor.
We can do this by either turning the input tensor into a single element array or by using tf.expand_dims(input, axis=0) to expand the dimenion of the tensor on 0th axis.
# Option 1: Add batch dimension to custom_image_tensor
print(f"Shape of custom image tensor: {np.array([custom_image_tensor]).shape}")
print(f"Shape of custom image tensor: {tf.expand_dims(custom_image_tensor, axis=0).shape}")
Shape of custom image tensor: (1, 224, 224, 3) Shape of custom image tensor: (1, 224, 224, 3)
Wonderful! We've now got a custom image tensor of shape (1, 224, 224, 3) ((batch_size, img_height, img_width, colour_channels)).
Let's try and predict!
# Get prediction probabilities from our mdoel
pred_probs = loaded_model.predict(tf.expand_dims(custom_image_tensor, axis=0))
pred_probs
1/1 [==============================] - 2s 2s/step
array([[1.83611644e-06, 3.09535017e-06, 3.86047805e-06, 3.19048486e-05,
1.66974694e-03, 1.27542022e-04, 7.03033629e-06, 1.19856362e-04,
1.01050091e-05, 3.87266744e-04, 6.44192414e-06, 1.67636438e-06,
8.94749770e-04, 5.01931618e-06, 1.60283549e-03, 9.41093604e-05,
4.67637838e-05, 8.51367513e-05, 5.67736897e-05, 6.14693909e-06,
2.67342989e-06, 1.47549901e-04, 4.17501433e-05, 3.90995192e-05,
9.50478498e-05, 1.47656752e-02, 3.08718845e-05, 1.58209339e-04,
8.39364156e-03, 1.17800606e-03, 2.69454729e-04, 1.02170045e-04,
7.42143384e-05, 8.22680071e-04, 1.73064705e-04, 8.98789040e-06,
6.77722392e-06, 2.46034167e-03, 1.21447938e-05, 3.06540052e-04,
1.12927992e-04, 1.30907722e-06, 1.19819895e-04, 3.28008295e-03,
4.22435085e-04, 2.56334723e-04, 6.35078293e-04, 6.96951101e-05,
1.82968670e-05, 6.66733533e-02, 1.65604251e-06, 4.85742465e-04,
3.82422912e-03, 4.36909148e-04, 1.34899176e-06, 4.04351122e-05,
2.30197293e-05, 7.29483800e-05, 1.31009811e-05, 1.30437169e-04,
1.27625071e-05, 3.21804691e-06, 6.78410470e-06, 3.72191658e-03,
9.23305777e-07, 4.05427454e-06, 1.32554891e-02, 8.34832132e-01,
1.84010264e-06, 5.39118366e-04, 2.44915718e-05, 1.35658804e-04,
9.53144918e-04, 3.80869096e-05, 3.43683018e-06, 3.57066506e-06,
2.41459438e-05, 2.93612948e-06, 1.27533756e-04, 2.15716864e-05,
3.21038242e-05, 7.87725276e-06, 1.70349504e-05, 4.27997729e-05,
5.72475437e-06, 1.81680916e-05, 1.28094471e-04, 7.12008550e-05,
8.24760180e-04, 6.14038622e-03, 4.27179504e-03, 3.55221750e-03,
1.20739173e-03, 4.15856484e-04, 1.61429329e-04, 1.58363022e-04,
3.78229856e-06, 1.03004022e-05, 2.00551622e-05, 1.21213234e-04,
2.68000053e-06, 1.00253812e-04, 4.04065868e-05, 9.84299404e-05,
1.29673525e-03, 3.07669543e-05, 1.62672077e-05, 1.17529435e-05,
3.74953932e-04, 4.74653389e-05, 1.00191637e-05, 1.36496616e-04,
3.76833777e-05, 1.55215133e-02, 2.33796614e-04, 1.01105807e-05,
8.56942424e-05, 1.37508148e-04, 3.79100857e-06, 1.04301716e-05]],
dtype=float32)
It worked!!!
Our model output a tensor of prediction probabilities.
We can find the predicted label by taking the argmax of the pred_probs tensor.
And we get the predicted class name by indexing on the class_names list using the predicted label.
# Get the predicted class label
pred_label = tf.argmax(pred_probs, axis=-1).numpy()[0]
# Get the predicted class name
pred_class_name = class_names[pred_label]
print(f"Predicted class label: {pred_label}")
print(f"Predicted class name: {pred_class_name}")
Predicted class label: 67 Predicted class name: labrador_retriever
Ho ho! That's looking good!
In summary, a model wants to make predictions on data in the same shape and format it was trained on.
So if you trained a model on image tensors with a certain shape and datatype, your model will want to make predictions on the same kind of image tensors with the same shape and datatype.
How about we try make predictions on multiple images?
To do so, let's make a function which replicates the workflow from above.
def pred_on_custom_image(image_path: str, # Path to the image file
model, # Trained TensorFlow model for prediction
target_size: tuple[int, int] = (224, 224), # Desired size of the image for input to the model
class_names: list = None, # List of class names (optional for plotting)
plot: bool = True): # Whether to plot the image and predicted class
"""
Loads an image, preprocesses it, makes a prediction using a provided model,
and optionally plots the image with the predicted class.
Args:
image_path (str): Path to the image file.
model: Trained TensorFlow model for prediction.
target_size (int, optional): Desired size of the image for input to the model. Defaults to 224.
class_names (list, optional): List of class names for plotting. Defaults to None.
plot (bool, optional): Whether to plot the image and predicted class. Defaults to True.
Returns:
str: The predicted class.
"""
# Prepare and load image
custom_image = tf.keras.utils.load_img(
path=image_path,
color_mode="rgb",
target_size=target_size,
)
# Turn the image into a tensor
custom_image_tensor = tf.keras.utils.img_to_array(custom_image)
# Add a batch dimension to the target tensor (e.g. (224, 224, 3) -> (1, 224, 224, 3))
custom_image_tensor = tf.expand_dims(custom_image_tensor, axis=0)
# Make a prediction with the target model
pred_probs = model.predict(custom_image_tensor)
# pred_probs = tf.keras.activations.softmax(tf.constant(pred_probs))
pred_class = class_names[tf.argmax(pred_probs, axis=-1).numpy()[0]]
# Plot if we want
if not plot:
return pred_class, pred_probs
else:
plt.figure(figsize=(5, 3))
plt.imshow(plt.imread(image_path))
plt.title(f"pred: {pred_class}\nprob: {tf.reduce_max(pred_probs):.3f}")
plt.axis("off")
What a good looking function!
How about we try it out on dog-photo-2.jpeg?
# Make prediction on custom dog photo 2
pred_on_custom_image(image_path="dog-photo-2.jpeg",
model=loaded_model,
class_names=class_names)
1/1 [==============================] - 0s 27ms/step

Woohoo!!! Our model got it right!
Let's repeat the process for our other custom images.
# Predict on multiple images
fig, axes = plt.subplots(1, 4, figsize=(15, 7))
for i, ax in enumerate(axes.flatten()):
image_path = custom_image_paths[i]
pred_class, pred_probs = pred_on_custom_image(image_path=image_path,
model=loaded_model,
class_names=class_names,
plot=False)
ax.imshow(plt.imread(image_path))
ax.set_title(f"pred: {pred_class}\nprob: {tf.reduce_max(pred_probs):.3f}")
ax.axis("off");
1/1 [==============================] - 0s 28ms/step 1/1 [==============================] - 0s 26ms/step 1/1 [==============================] - 0s 25ms/step 1/1 [==============================] - 0s 28ms/step

Epic!!
Our Dog Vision 🐶👁 model has come to life!
Looks like our model got it right for 3/4 of our custom dog photos (my dogs Bella and Seven are labrador retrievers, with a potential mix of something else).
But the model seemed to also think the photo of me was a soft_coated_wheaten_terrier (note: due to the randomness of machine learning, your result may be different here, if so, please let me know, I'd love to see what other kinds of dogs the model thinks I am :D).
You might be wondering, why does it do this?
It's because our model has been strictly trained to always predict a dog breed no matter what image it recieves.
So no matter what image we pass to our model, it will always predict a certain dog breed.
You can try this with your own images.
How would you fix this?
One way would be to train another model to predict whether the input image is of a dog or is not of a dog.
And then only letting our Dog Vision 🐶👁 model predict on the images that are of dogs.

Example of combining multiple machine learning models to create a workflow. One model for detecting food (Food Not Food) and another model for identifying what food is in the image (FoodVision, similar to Dog Vision). If an app is designed to take photos of food, taking photos of objects that aren't food and having them identified as food can be a poor customer experience. Source: Nutrify.
These are some of the workflows you'll have to think about when you eventually deploy your own machine learning models.
Machine learning models are often very powerful.
But they aren't perfect.
Implementing guidelines and checks around them is still a very active area of research.
13. Key Takeaways¶
- Data, data, data! In any machine learning problem, getting a dataset and preparing it so that it is in a usable format will likely be the first and often most important step (hence why we spent so much time getting the data ready). It will also be an ongoing process, as although we've worked with thousands of dog images, our models could still be improved. And as we saw going from training with 10% of the data to 100% of the data, one of the best ways to improve a model is with more data. Explore your data early and often.
- When starting out, use transfer learning where possible. For most new problems, you should generally look to see if a pretrained model exists and see if you can adapt it to your use case. Ask yourself: What format is my data in? What are my ideal inputs and outputs? Is there a pretrained model for my use case?
- TensorFlow and Keras provide building blocks for neural networks which are powerful machine learning models capable of learning patterns in a wide range of data from text to audio to images and more.
- Experiment, experiment, experiment! It's highly unlikely you'll ever get the best performing model on your first try. Machine learning is very experimental by nature. This includes experimenting on the data, the model, the training setup and the outputs (how does your model work in practice?). Always keep this front of mind in any machine learning project. Your results are never stationary and can often always be improved.
Extensions & Exercises¶
The following are a series of exercises and extensions which build on what we've covered throughout this module.
I'd highly recommend going thorugh each one and spending time practicing what you've learned.
This is where the real knowledge is built. Trying things out for yourself.
- Try a prediction with our trained model on your own images of dogs and see if the model is correct.
- Try training another model from
tf.keras.applications(e.g. ConvNeXt) and see if it performs better than EfficientNetV2. - Try training a model on your own images in different classes, for example, apple vs. banana vs. orange. You could download images from the internet and sort them into different folders and then load them how we've done in the data loading section. Or you could take photos of your own and build a model to differentiate between them.
- For more advanced model training, you may want to look into the concept of "Callbacks", these are functions which run during the model training. TensorFlow and Keras have a series of built-in callbacks which can be helpful for training. Have a read of the
tf.keras.callbacks.Callbackdocumentation and see which ones may be useful to you. - We touched on the concept of overfitting when we trained our model. This is when a model performs far better on the training set than on the test set. The concept of trying to prevent overfitting is known as regularization. Spend 20-minutes researching "ways to prevent overfitting" and write a list of 2-3 techniques and how they might come into play with our model training. Tip: One of the most common regularization techniques in computer vision is data augmentation (also see the brief example below).
- One of the most important parts of machine learning is having good data. The next most important part is loading that data in a way that can used to train models as fast and efficiently as possible. For more on this, I'd highly recommend reading more about the
tf.dataAPI (this API is TensorFlow focused, however, the concepts can be bridged to other dataloading needs) as well as reviewing thetf.databest practices (better performance with thetf.dataAPI). - Right now our model works well, however, we have to write code to interact with it. You could turn it into a small machine learning app using Gradio so people can upload their own images of dogs and see what the model predicts. See the example for image classification with TensorFlow and Keras for an idea of what you could build. See an example of this below as well as a running demo of Dog Vision on Hugging Face.
In this project we've only really scratched the surface of what's possible with TensorFlow/Keras and deep learning.
For a more comprehensive overview of TensorFlow/Keras, see the following:
- 14-hour TensorFlow Tutorial on YouTube (this is the first 14 hours of the ZTM TensorFlow course).
- Zero to Mastery TensorFlow for Deep Learning course (a 50+ hour course diving into many applications of TensorFlow and deep learning).
Extension example: data augmentation¶
Data augmentation is a regularization technique to help prevent overfitting.
It's designed to alter training images to artifically increase the diversity of the training dataset and hopefully help to generalize better to test images as well as real-life images.
For example, we want our models to be able to identify the same breed of dog in an image regardless if the dog is facing left or right.
So one simple data augmentation technique is to randomly flip the image horizontally so the model learns to recognize the same dog from different points of view.
You can repeat this for many different types of image modifications such as rotation, zone, colour alterations and more.
The following code is a brief example of how to incorporate a data augmentation layer into a model (note that in practice data augmentation is only applied during training time and not during testing/prediction time, this is set automatically within layers aimed at data augmentation).
For more, see the TensorFlow guide on data augmentation.
from tensorflow.keras import layers
# Note: Could functionize all of this
# Setup hyperparameters
img_size = 224
num_classes = 120
# Create data augmentation layer
data_augmentation_layer = tf.keras.Sequential(
[
layers.RandomFlip("horizontal"), # randomly flip image across horizontal axis
layers.RandomRotation(factor=0.2), # randomly rotate image
layers.RandomZoom(height_factor=0.2, width_factor=0.2) # randomly zoom into image
# More augmentation can go here
],
name="data_augmentation"
)
# Setup base model
base_model = tf.keras.applications.efficientnet_v2.EfficientNetV2B0(
include_top=False,
weights='imagenet',
input_shape=(img_size, img_size, 3),
include_preprocessing=True
)
# Freeze the base model
base_model.trainable = False
# Create new model
inputs = tf.keras.Input(shape=(224, 224, 3))
# Create data augmentation
x = data_augmentation_layer(inputs)
# Craft model
x = base_model(x, training=False)
x = tf.keras.layers.GlobalAveragePooling2D()(x)
x = tf.keras.layers.Dropout(0.2)(x)
outputs = tf.keras.layers.Dense(num_classes,
name="output_layer",
activation="softmax")(x) # Note: If you have "softmax" activation, use from_logits=False in loss function
model_2 = tf.keras.Model(inputs, outputs, name="model_2")
# Uncomment for full model summary with augmentation layers
# model_2.summary()
Extension Example: Gradio App Demo¶
This is a modified version of the Gradio Image Classification Tutorial with TensorFlow and Keras.
You can see a guide on Hugging Face for how to host it on Hugging Face Spaces (a place where you can host and share your machine learning apps).
First we'll install Gradio.
!pip install -q gradio
import gradio as gr
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 12.2/12.2 MB 34.0 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 91.9/91.9 kB 12.9 MB/s eta 0:00:00 Preparing metadata (setup.py) ... done ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 314.4/314.4 kB 33.7 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 75.6/75.6 kB 10.1 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 141.1/141.1 kB 18.2 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 8.8/8.8 MB 91.6 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 47.2/47.2 kB 4.3 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 60.8/60.8 kB 8.8 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 129.9/129.9 kB 16.6 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 77.9/77.9 kB 9.8 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 58.3/58.3 kB 8.3 MB/s eta 0:00:00 ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 71.9/71.9 kB 9.7 MB/s eta 0:00:00 Building wheel for ffmpy (setup.py) ... done ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. spacy 3.7.4 requires typer<0.10.0,>=0.3.0, but you have typer 0.12.3 which is incompatible. weasel 0.3.4 requires typer<0.10.0,>=0.3.0, but you have typer 0.12.3 which is incompatible.
Then we'll download the saved model (the same model we trained during the Dog Vision notebook) along with the assosciated labels.
I've stored my saved model as well as the Stanford Dogs class names on Hugging Face.
You can see my files at huggingface.co/spaces/mrdbourke/dog_vision.
import tensorflow as tf
# Download saved model and labels from Hugging Face
!wget -q https://huggingface.co/spaces/mrdbourke/dog_vision/resolve/main/dog_vision_model_demo.keras
!wget -q https://huggingface.co/spaces/mrdbourke/dog_vision/resolve/main/stanford_dogs_class_names.txt
# Load model
model_save_path = "dog_vision_model_demo.keras"
loaded_model_for_demo = tf.keras.models.load_model(model_save_path)
# Load labels
with open("stanford_dogs_class_names.txt", "r") as f:
class_names = [line.strip() for line in f.readlines()]
The prediction function should take in an image and return a dictionary of classes and their prediction probabilities.
# Create prediction function
def pred_on_custom_image(image, # input image (preprocessed by Gradio's Image input to be numpy.array)
model: tf.keras.Model = loaded_model_for_demo, # Trained TensorFlow model for prediction
target_size: int = 224, # Desired size of the image for input to the model
class_names: list = class_names): # List of class names
"""
Loads an image, preprocesses it, makes a prediction using a provided model,
and returns a dictionary of prediction probabilities per class name.
Args:
image: Input image.
model: Trained TensorFlow model for prediction.
target_size (int, optional): Desired size of the image for input to the model. Defaults to 224.
class_names (list, optional): List of class names for plotting. Defaults to None.
Returns:
Dict[str: float]: A dictionary of string class names and their respective prediction probability.
"""
# Note: gradio.inputs.Image handles opening the image
# # Prepare and load image
# custom_image = tf.keras.utils.load_img(
# path=image_path,
# color_mode="rgb",
# target_size=target_size,
# )
# Create resizing layer to resize the image
resize = tf.keras.layers.Resizing(height=target_size,
width=target_size)
# Turn the image into a tensor and resize it
custom_image_tensor = resize(tf.keras.utils.img_to_array(image))
# Add a batch dimension to the target tensor (e.g. (224, 224, 3) -> (1, 224, 224, 3))
custom_image_tensor = tf.expand_dims(custom_image_tensor, axis=0)
# Make a prediction with the target model
pred_probs = model.predict(custom_image_tensor)[0]
# Predictions get returned as a dictionary of {label: pred_prob}
pred_probs_dict = {class_names[i]: float(pred_probs[i]) for i in range(len(class_names))}
return pred_probs_dict
interface_title = "Dog Vision 🐶👁️"
interface_description = "Identify different dogs in images with deep learning. Model trained with TensorFlow/Keras."
interface = gr.Interface(fn=pred_on_custom_image,
inputs=gr.Image(),
outputs=gr.Label(num_top_classes=3),
examples=["dog-photo-1.jpeg",
"dog-photo-2.jpeg",
"dog-photo-3.jpeg",
"dog-photo-4.jpeg"],
title=interface_title,
description=interface_description)
# Uncomment to launch the interface directly in a notebook
# interface.launch(debug=True)
Save the following code to an app.py file for running on Hugging Face spaces.
Finally, you can see the running demo on Hugging Face.
Try it out with your own images of dogs and see Dog Vision 🐶👁️ come to life!
from IPython.display import HTML
# Embed the Hugging Face Space as an iframe
html_string = """
<iframe src="https://mrdbourke-dog-vision.hf.space" frameborder="0" width="850" height="850"></iframe>
"""
display(HTML(html_string))
The following will write the whole cell to a Python file called app.py, this can uploaded to Hugging Face and run as a Space. As long as all available files (e.g. model file and class names file) are available.
# %%writefile app.py
# import gradio as gr
# import tensorflow as tf
# # Load model
# model_save_path = "dog_vision_model_demo.keras"
# loaded_model_for_demo = tf.keras.models.load_model(model_save_path)
# # Load labels
# with open("stanford_dogs_class_names.txt", "r") as f:
# class_names = [line.strip() for line in f.readlines()]
# # Create prediction function
# def pred_on_custom_image(image, # input image (preprocessed by Gradio's Image input to be numpy.array)
# model: tf.keras.Model =loaded_model_for_demo, # Trained TensorFlow model for prediction
# target_size: int = 224, # Desired size of the image for input to the model
# class_names: list = class_names): # List of class names
# """
# Loads an image, preprocesses it, makes a prediction using a provided model,
# and returns a dictionary of prediction probabilities per class name.
# Args:
# image: Input image.
# model: Trained TensorFlow model for prediction.
# target_size (int, optional): Desired size of the image for input to the model. Defaults to 224.
# class_names (list, optional): List of class names for plotting. Defaults to None.
# Returns:
# Dict[str: float]: A dictionary of string class names and their respective prediction probability.
# """
# # Note: gradio.inputs.Image handles opening the image
# # # Prepare and load image
# # custom_image = tf.keras.utils.load_img(
# # path=image_path,
# # color_mode="rgb",
# # target_size=target_size,
# # )
# # Create resizing layer to resize the image
# resize = tf.keras.layers.Resizing(height=target_size,
# width=target_size)
# # Turn the image into a tensor and resize it
# custom_image_tensor = resize(tf.keras.utils.img_to_array(image))
# # Add a batch dimension to the target tensor (e.g. (224, 224, 3) -> (1, 224, 224, 3))
# custom_image_tensor = tf.expand_dims(custom_image_tensor, axis=0)
# # Make a prediction with the target model
# pred_probs = model.predict(custom_image_tensor)[0]
# # Predictions get returned as a dictionary of {label: pred_prob}
# pred_probs_dict = {class_names[i]: float(pred_probs[i]) for i in range(len(class_names))}
# return pred_probs_dict
# # Create Gradio interface
# interface_title = "Dog Vision 🐶👁️"
# interface_description = "Identify different dogs in images with deep learning. Model trained with TensorFlow/Keras."
# interface = gr.Interface(fn=pred_on_custom_image,
# inputs=gr.Image(),
# outputs=gr.Label(num_top_classes=3),
# examples=["dog-photo-1.jpeg",
# "dog-photo-2.jpeg",
# "dog-photo-3.jpeg",
# "dog-photo-4.jpeg"],
# title=interface_title,
# description=interface_description)
# interface.launch(debug=True)