![]()
04. Transfer Learning with TensorFlow Part 1: Feature Extraction¶
We've built a bunch of convolutional neural networks from scratch and they all seem to be learning, however, there is still plenty of room for improvement.
To improve our model(s), we could spend a while trying different configurations, adding more layers, changing the learning rate, adjusting the number of neurons per layer and more.
However, doing this is very time consuming.
Luckily, there's a technique we can use to save time.
It's called transfer learning, in other words, taking the patterns (also called weights) another model has learned from another problem and using them for our own problem.
There are two main benefits to using transfer learning:
- Can leverage an existing neural network architecture proven to work on problems similar to our own.
- Can leverage a working neural network architecture which has already learned patterns on similar data to our own. This often results in achieving great results with less custom data.
What this means is, instead of hand-crafting our own neural network architectures or building them from scratch, we can utilise models which have worked for others.
And instead of training our own models from scratch on our own datasets, we can take the patterns a model has learned from datasets such as ImageNet (millions of images of different objects) and use them as the foundation of our own. Doing this often leads to getting great results with less data.
Over the next few notebooks, we'll see the power of transfer learning in action.
What we're going to cover¶
We're going to go through the following with TensorFlow:
- Introduce transfer learning (a way to beat all of our old self-built models)
- Using a smaller dataset to experiment faster (10% of training samples of 10 classes of food)
- Build a transfer learning feature extraction model using TensorFlow Hub
- Introduce the TensorBoard callback to track model training results
- Compare model results using TensorBoard
How you can use this notebook¶
You can read through the descriptions and the code (it should all run, except for the cells which error on purpose), but there's a better option.
Write all of the code yourself.
Yes. I'm serious. Create a new notebook, and rewrite each line by yourself. Investigate it, see if you can break it, why does it break?
You don't have to write the text descriptions but writing the code yourself is a great way to get hands-on experience.
Don't worry if you make mistakes, we all do. The way to get better and make less mistakes is to write more code.
# Add timestamp
import datetime
print(f"Notebook last run (end-to-end): {datetime.datetime.now()}")
Notebook last run (end-to-end): 2023-05-11 04:43:01.173110
Using a GPU¶
To begin, let's check to see if we're using a GPU. Using a GPU will make sure our model trains faster than using just a CPU.
# Are we using a GPU?
!nvidia-smi
Thu May 11 04:22:37 2023
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 525.85.12 Driver Version: 525.85.12 CUDA Version: 12.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 NVIDIA A100-SXM... Off | 00000000:00:04.0 Off | 0 |
| N/A 40C P0 46W / 400W | 0MiB / 40960MiB | 0% Default |
| | | Disabled |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
If the cell above doesn't output something which looks like:
Fri Sep 4 03:35:21 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.66 Driver Version: 418.67 CUDA Version: 10.1 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:00:04.0 Off | 0 |
| N/A 35C P0 26W / 250W | 0MiB / 16280MiB | 0% Default |
| | | ERR! |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
Go to Runtime -> Change Runtime Type -> Hardware Accelerator and select "GPU", then rerun the cell above.
Transfer leanring with TensorFlow Hub: Getting great results with 10% of the data¶
If you've been thinking, "surely someone else has spent the time crafting the right model for the job..." then you're in luck.
For many of the problems you'll want to use deep learning for, chances are, a working model already exists.
And the good news is, you can access many of them on TensorFlow Hub.
TensorFlow Hub is a repository for existing model components. It makes it so you can import and use a fully trained model with as little as a URL.
Now, I really want to demonstrate the power of transfer learning to you.
To do so, what if I told you we could get much of the same results (or better) than our best model has gotten so far with only 10% of the original data, in other words, 10x less data.
This seems counterintuitive right?
Wouldn't you think more examples of what a picture of food looked like led to better results?
And you'd be right if you thought so, generally, more data leads to better results.
However, what if you didn't have more data? What if instead of 750 images per class, you had 75 images per class?
Collecting 675 more images of a certain class could take a long time.
So this is where another major benefit of transfer learning comes in.
Transfer learning often allows you to get great results with less data.
But don't just take my word for it. Let's download a subset of the data we've been using, namely 10% of the training data from the 10_food_classes dataset and use it to train a food image classifier on.
![]() What we're working towards building. Taking a pre-trained model and adding our own custom layers on top, extracting all of the underlying patterns learned on another dataset our own images.
What we're working towards building. Taking a pre-trained model and adding our own custom layers on top, extracting all of the underlying patterns learned on another dataset our own images.
Downloading and becoming one with the data¶
# Get data (10% of labels)
import zipfile
# Download data
!wget https://storage.googleapis.com/ztm_tf_course/food_vision/10_food_classes_10_percent.zip
# Unzip the downloaded file
zip_ref = zipfile.ZipFile("10_food_classes_10_percent.zip", "r")
zip_ref.extractall()
zip_ref.close()
--2023-05-11 04:22:37-- https://storage.googleapis.com/ztm_tf_course/food_vision/10_food_classes_10_percent.zip Resolving storage.googleapis.com (storage.googleapis.com)... 74.125.68.128, 74.125.24.128, 142.250.4.128, ... Connecting to storage.googleapis.com (storage.googleapis.com)|74.125.68.128|:443... connected. HTTP request sent, awaiting response... 200 OK Length: 168546183 (161M) [application/zip] Saving to: ‘10_food_classes_10_percent.zip’ 10_food_classes_10_ 100%[===================>] 160.74M 19.2MB/s in 9.7s 2023-05-11 04:22:48 (16.5 MB/s) - ‘10_food_classes_10_percent.zip’ saved [168546183/168546183]
# How many images in each folder?
import os
# Walk through 10 percent data directory and list number of files
for dirpath, dirnames, filenames in os.walk("10_food_classes_10_percent"):
print(f"There are {len(dirnames)} directories and {len(filenames)} images in '{dirpath}'.")
There are 2 directories and 0 images in '10_food_classes_10_percent'. There are 10 directories and 0 images in '10_food_classes_10_percent/test'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/chicken_wings'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/fried_rice'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/ice_cream'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/grilled_salmon'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/chicken_curry'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/hamburger'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/steak'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/pizza'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/sushi'. There are 0 directories and 250 images in '10_food_classes_10_percent/test/ramen'. There are 10 directories and 0 images in '10_food_classes_10_percent/train'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/chicken_wings'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/fried_rice'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/ice_cream'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/grilled_salmon'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/chicken_curry'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/hamburger'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/steak'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/pizza'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/sushi'. There are 0 directories and 75 images in '10_food_classes_10_percent/train/ramen'.
Notice how each of the training directories now has 75 images rather than 750 images. This is key to demonstrating how well transfer learning can perform with less labelled images.
The test directories still have the same amount of images. This means we'll be training on less data but evaluating our models on the same amount of test data.
Creating data loaders (preparing the data)¶
Now we've downloaded the data, let's use the ImageDataGenerator class along with the flow_from_directory method to load in our images.
# Setup data inputs
from tensorflow.keras.preprocessing.image import ImageDataGenerator
IMAGE_SHAPE = (224, 224)
BATCH_SIZE = 32
train_dir = "10_food_classes_10_percent/train/"
test_dir = "10_food_classes_10_percent/test/"
train_datagen = ImageDataGenerator(rescale=1/255.)
test_datagen = ImageDataGenerator(rescale=1/255.)
print("Training images:")
train_data_10_percent = train_datagen.flow_from_directory(train_dir,
target_size=IMAGE_SHAPE,
batch_size=BATCH_SIZE,
class_mode="categorical")
print("Testing images:")
test_data = train_datagen.flow_from_directory(test_dir,
target_size=IMAGE_SHAPE,
batch_size=BATCH_SIZE,
class_mode="categorical")
Training images: Found 750 images belonging to 10 classes. Testing images: Found 2500 images belonging to 10 classes.
Excellent! Loading in the data we can see we've got 750 images in the training dataset belonging to 10 classes (75 per class) and 2500 images in the test set belonging to 10 classes (250 per class).
Setting up callbacks (things to run whilst our model trains)¶
Before we build a model, there's an important concept we're going to get familiar with because it's going to play a key role in our future model building experiments.
And that concept is callbacks.
Callbacks are extra functionality you can add to your models to be performed during or after training. Some of the most popular callbacks include:
- Experiment tracking with TensorBoard - log the performance of multiple models and then view and compare these models in a visual way on TensorBoard (a dashboard for inspecting neural network parameters). Helpful to compare the results of different models on your data.
- Model checkpointing - save your model as it trains so you can stop training if needed and come back to continue off where you left. Helpful if training takes a long time and can't be done in one sitting.
- Early stopping - leave your model training for an arbitrary amount of time and have it stop training automatically when it ceases to improve. Helpful when you've got a large dataset and don't know how long training will take.
We'll explore each of these overtime but for this notebook, we'll see how the TensorBoard callback can be used.
The TensorBoard callback can be accessed using tf.keras.callbacks.TensorBoard().
Its main functionality is saving a model's training performance metrics to a specified log_dir.
By default, logs are recorded every epoch using the update_freq='epoch' parameter. This is a good default since tracking model performance too often can slow down model training.
To track our modelling experiments using TensorBoard, let's create a function which creates a TensorBoard callback for us.
🔑 Note: We create a function for creating a TensorBoard callback because as we'll see later on, each model needs its own TensorBoard callback instance (so the function will create a new one each time it's run).
# Create tensorboard callback (functionized because need to create a new one for each model)
import datetime
def create_tensorboard_callback(dir_name, experiment_name):
log_dir = dir_name + "/" + experiment_name + "/" + datetime.datetime.now().strftime("%Y%m%d-%H%M%S")
tensorboard_callback = tf.keras.callbacks.TensorBoard(
log_dir=log_dir
)
print(f"Saving TensorBoard log files to: {log_dir}")
return tensorboard_callback
Because you're likely to run multiple experiments, it's a good idea to be able to track them in some way.
In our case, our function saves a model's performance logs to a directory named [dir_name]/[experiment_name]/[current_timestamp], where:
dir_nameis the overall logs directoryexperiment_nameis the particular experimentcurrent_timestampis the time the experiment started based on Python'sdatetime.datetime().now()
🔑 Note: Depending on your use case, the above experimenting tracking naming method may work or you might require something more specific. The good news is, the TensorBoard callback makes it easy to track modelling logs as long as you specify where to track them. So you can get as creative as you like with how you name your experiments, just make sure you or your team can understand them.
Creating models using TensorFlow Hub¶
In the past we've used TensorFlow to create our own models layer by layer from scratch.
Now we're going to do a similar process, except the majority of our model's layers are going to come from TensorFlow Hub.
In fact, we're going to use two models from TensorFlow Hub:
- ResNetV2 - a state of the art computer vision model architecture from 2016.
- EfficientNet - a state of the art computer vision architecture from 2019.
State of the art means that at some point, both of these models have achieved the lowest error rate on ImageNet (ILSVRC-2012-CLS), the gold standard of computer vision benchmarks.
You might be wondering, how do you find these models on TensorFlow Hub?
Here are the steps I took:
- Go to tfhub.dev.
- Choose your problem domain, e.g. "Image" (we're using food images).
- Select your TF version, which in our case is TF2.
- Remove all "Problem domanin" filters except for the problem you're working on.
- Note: "Image feature vector" can be used alongside almost any problem, we'll get to this soon.
- The models listed are all models which could potentially be used for your problem.
🤔 Question: I see many options for image classification models, how do I know which is best?
You can see a list of state of the art models on paperswithcode.com, a resource for collecting the latest in deep learning paper results which have code implementations for the findings they report.
Since we're working with images, our target are the models which perform best on ImageNet.
You'll probably find not all of the model architectures listed on paperswithcode appear on TensorFlow Hub. And this is okay, we can still use what's available.
To find our models, let's narrow down our search using the Architecture tab.
- Select the Architecture tab on TensorFlow Hub and you'll see a dropdown menu of architecture names appear.
- The rule of thumb here is generally, names with larger numbers means better performing models. For example, EfficientNetB4 performs better than EfficientNetB0.
- However, the tradeoff with larger numbers can mean they take longer to compute.
- Select EfficientNetB0 and you should see something like the following:
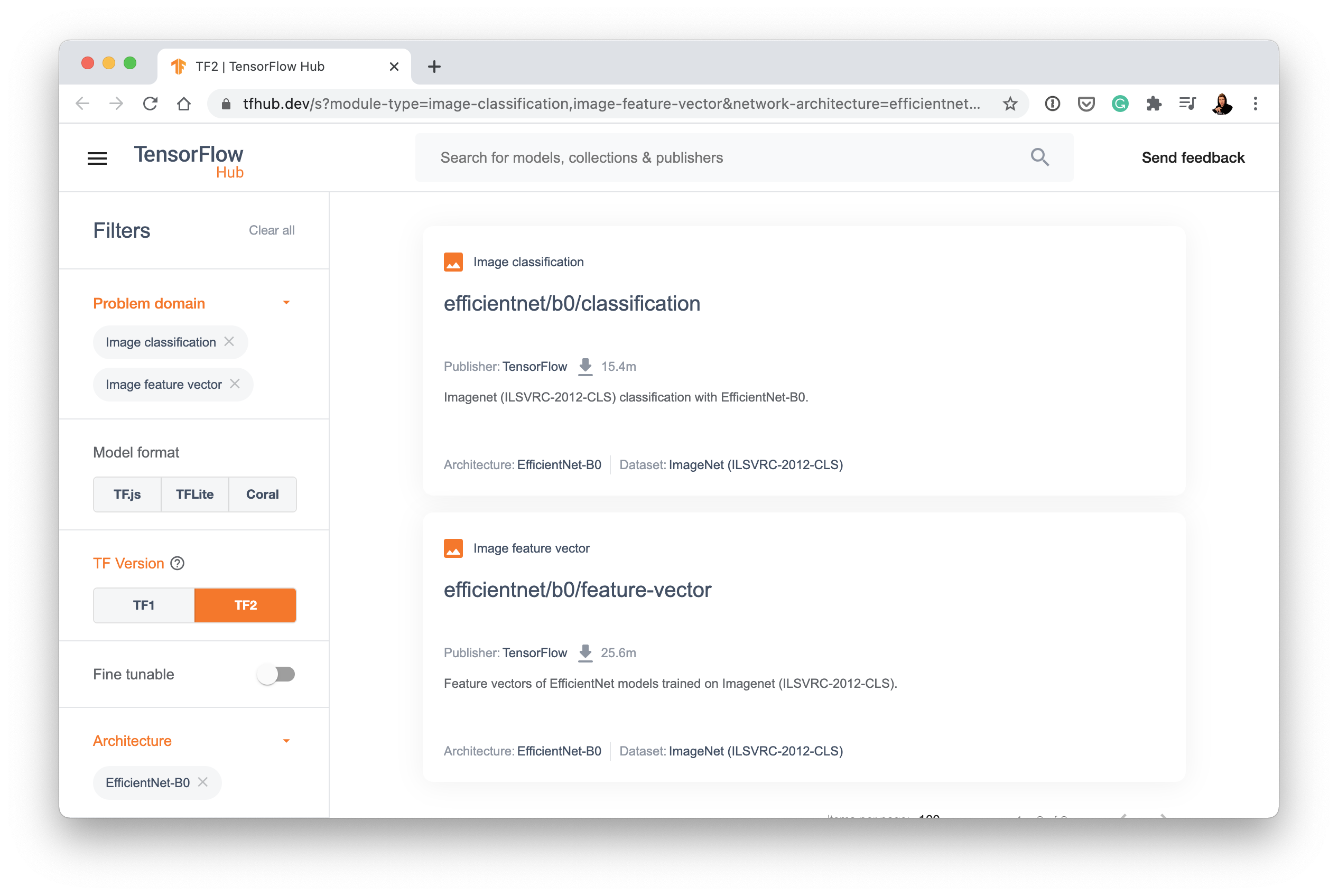
- Clicking the one titled "efficientnet/b0/feature-vector" brings us to a page with a button that says "Copy URL". That URL is what we can use to harness the power of EfficientNetB0.
- Copying the URL should give you something like this: https://tfhub.dev/tensorflow/efficientnet/b0/feature-vector/1
🤔 Question: I thought we were doing image classification, why do we choose feature vector and not classification?
Great observation. This is where the differnet types of transfer learning come into play, as is, feature extraction and fine-tuning.
- "As is" transfer learning is when you take a pretrained model as it is and apply it to your task without any changes.
For example, many computer vision models are pretrained on the ImageNet dataset which contains 1000 different classes of images. This means passing a single image to this model will produce 1000 different prediction probability values (1 for each class).
- This is helpful if you have 1000 classes of image you'd like to classify and they're all the same as the ImageNet classes, however, it's not helpful if you want to classify only a small subset of classes (such as 10 different kinds of food). Model's with
"/classification"in their name on TensorFlow Hub provide this kind of functionality.
- This is helpful if you have 1000 classes of image you'd like to classify and they're all the same as the ImageNet classes, however, it's not helpful if you want to classify only a small subset of classes (such as 10 different kinds of food). Model's with
- Feature extraction transfer learning is when you take the underlying patterns (also called weights) a pretrained model has learned and adjust its outputs to be more suited to your problem.
For example, say the pretrained model you were using had 236 different layers (EfficientNetB0 has 236 layers), but the top layer outputs 1000 classes because it was pretrained on ImageNet. To adjust this to your own problem, you might remove the original activation layer and replace it with your own but with the right number of output classes. The important part here is that only the top few layers become trainable, the rest remain frozen.
- This way all the underlying patterns remain in the rest of the layers and you can utilise them for your own problem. This kind of transfer learning is very helpful when your data is similar to the data a model has been pretrained on.
Fine-tuning transfer learning is when you take the underlying patterns (also called weights) of a pretrained model and adjust (fine-tune) them to your own problem.
- This usually means training some, many or all of the layers in the pretrained model. This is useful when you've got a large dataset (e.g. 100+ images per class) where your data is slightly different to the data the original model was trained on.
A common workflow is to "freeze" all of the learned patterns in the bottom layers of a pretrained model so they're untrainable. And then train the top 2-3 layers of so the pretrained model can adjust its outputs to your custom data (feature extraction).
After you've trained the top 2-3 layers, you can then gradually "unfreeze" more and more layers and run the training process on your own data to further fine-tune the pretrained model.
🤔 Question: Why train only the top 2-3 layers in feature extraction?
The lower a layer is in a computer vision model as in, the closer it is to the input layer, the larger the features it learn. For example, a bottom layer in a computer vision model to identify images of cats or dogs might learn the outline of legs, where as, layers closer to the output might learn the shape of teeth. Often, you'll want the larger features (learned patterns are also called features) to remain, since these are similar for both animals, where as, the differences remain in the more fine-grained features.
![]() The different kinds of transfer learning. An original model, a feature extraction model (only top 2-3 layers change) and a fine-tuning model (many or all of original model get changed).
The different kinds of transfer learning. An original model, a feature extraction model (only top 2-3 layers change) and a fine-tuning model (many or all of original model get changed).
Okay, enough talk, let's see this in action. Once we do, we'll explain what's happening.
First we'll import TensorFlow and TensorFlow Hub.
import tensorflow as tf
import tensorflow_hub as hub
from tensorflow.keras import layers
Now we'll get the feature vector URLs of two common computer vision architectures, EfficientNetB0 (2019) and ResNetV250 (2016) from TensorFlow Hub using the steps above.
We're getting both of these because we're going to compare them to see which performs better on our data.
🔑 Note: Comparing different model architecture performance on the same data is a very common practice. The simple reason is because you want to know which model performs best for your problem.
Update: As of 14 August 2021, EfficientNet V2 pretrained models are available on TensorFlow Hub. The original code in this notebook uses EfficientNet V1, it has been left unchanged. In my experiments with this dataset, V1 outperforms V2. Best to experiment with your own data and see what suits you.
# Resnet 50 V2 feature vector
resnet_url = "https://tfhub.dev/google/imagenet/resnet_v2_50/feature_vector/4"
# Original: EfficientNetB0 feature vector (version 1)
efficientnet_url = "https://tfhub.dev/tensorflow/efficientnet/b0/feature-vector/1"
# # New: EfficientNetB0 feature vector (version 2)
# efficientnet_url = "https://tfhub.dev/google/imagenet/efficientnet_v2_imagenet1k_b0/feature_vector/2"
These URLs link to a saved pretrained model on TensorFlow Hub.
When we use them in our model, the model will automatically be downloaded for us to use.
To do this, we can use the KerasLayer() model inside the TensorFlow hub library.
Since we're going to be comparing two models, to save ourselves code, we'll create a function create_model(). This function will take a model's TensorFlow Hub URL, instatiate a Keras Sequential model with the appropriate number of output layers and return the model.
def create_model(model_url, num_classes=10):
"""Takes a TensorFlow Hub URL and creates a Keras Sequential model with it.
Args:
model_url (str): A TensorFlow Hub feature extraction URL.
num_classes (int): Number of output neurons in output layer,
should be equal to number of target classes, default 10.
Returns:
An uncompiled Keras Sequential model with model_url as feature
extractor layer and Dense output layer with num_classes outputs.
"""
# Download the pretrained model and save it as a Keras layer
feature_extractor_layer = hub.KerasLayer(model_url,
trainable=False, # freeze the underlying patterns
name='feature_extraction_layer',
input_shape=IMAGE_SHAPE+(3,)) # define the input image shape
# Create our own model
model = tf.keras.Sequential([
feature_extractor_layer, # use the feature extraction layer as the base
layers.Dense(num_classes, activation='softmax', name='output_layer') # create our own output layer
])
return model
Great! Now we've got a function for creating a model, we'll use it to first create a model using the ResNetV250 architecture as our feature extraction layer.
Once the model is instantiated, we'll compile it using categorical_crossentropy as our loss function, the Adam optimizer and accuracy as our metric.
# Create model
resnet_model = create_model(resnet_url, num_classes=train_data_10_percent.num_classes)
# Compile
resnet_model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
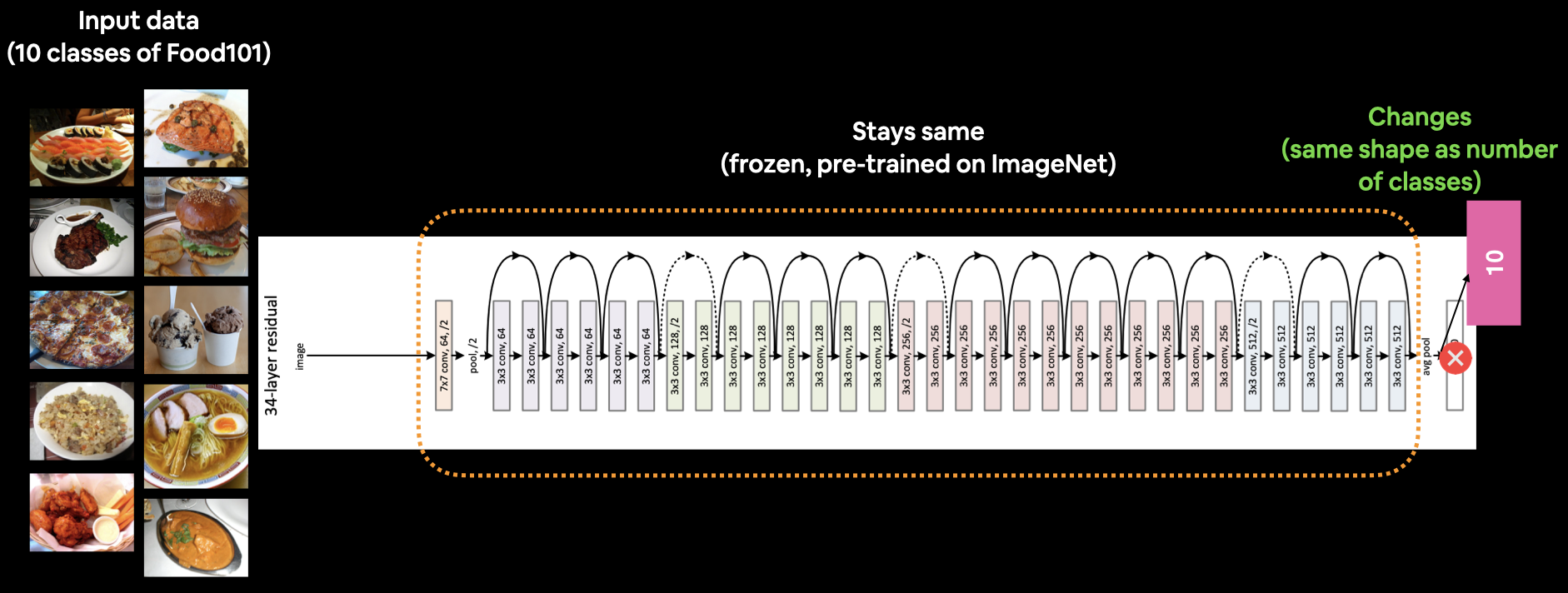 What our current model looks like. A ResNet50V2 backbone with a custom dense layer on top (10 classes instead of 1000 ImageNet classes). Note: The Image shows ResNet34 instead of ResNet50. Image source: https://arxiv.org/abs/1512.03385.
What our current model looks like. A ResNet50V2 backbone with a custom dense layer on top (10 classes instead of 1000 ImageNet classes). Note: The Image shows ResNet34 instead of ResNet50. Image source: https://arxiv.org/abs/1512.03385.
Beautiful. Time to fit the model.
We've got the training data ready in train_data_10_percent as well as the test data saved as test_data.
But before we call the fit function, there's one more thing we're going to add, a callback. More specifically, a TensorBoard callback so we can track the performance of our model on TensorBoard.
We can add a callback to our model by using the callbacks parameter in the fit function.
In our case, we'll pass the callbacks parameter the create_tensorboard_callback() we created earlier with some specific inputs so we know what experiments we're running.
Let's keep this experiment short and train for 5 epochs.
# Fit the model
resnet_history = resnet_model.fit(train_data_10_percent,
epochs=5,
steps_per_epoch=len(train_data_10_percent),
validation_data=test_data,
validation_steps=len(test_data),
# Add TensorBoard callback to model (callbacks parameter takes a list)
callbacks=[create_tensorboard_callback(dir_name="tensorflow_hub", # save experiment logs here
experiment_name="resnet50V2")]) # name of log files
Saving TensorBoard log files to: tensorflow_hub/resnet50V2/20230511-042304 Epoch 1/5 24/24 [==============================] - 28s 680ms/step - loss: 1.7915 - accuracy: 0.3880 - val_loss: 1.1463 - val_accuracy: 0.6368 Epoch 2/5 24/24 [==============================] - 14s 620ms/step - loss: 0.8710 - accuracy: 0.7560 - val_loss: 0.8359 - val_accuracy: 0.7352 Epoch 3/5 24/24 [==============================] - 14s 618ms/step - loss: 0.6160 - accuracy: 0.8373 - val_loss: 0.7385 - val_accuracy: 0.7676 Epoch 4/5 24/24 [==============================] - 15s 624ms/step - loss: 0.4705 - accuracy: 0.8907 - val_loss: 0.7016 - val_accuracy: 0.7728 Epoch 5/5 24/24 [==============================] - 15s 640ms/step - loss: 0.3744 - accuracy: 0.9200 - val_loss: 0.6764 - val_accuracy: 0.7772
Wow!
It seems that after only 5 epochs, the ResNetV250 feature extraction model was able to blow any of the architectures we made out of the water, achieving around 90% accuracy on the training set and nearly 80% accuracy on the test set...with only 10 percent of the training images!
That goes to show the power of transfer learning. And it's one of the main reasons whenever you're trying to model your own datasets, you should look into what pretrained models already exist.
Let's check out our model's training curves using our plot_loss_curves function.
# If you wanted to, you could really turn this into a helper function to load in with a helper.py script...
import matplotlib.pyplot as plt
# Plot the validation and training data separately
def plot_loss_curves(history):
"""
Returns separate loss curves for training and validation metrics.
"""
loss = history.history['loss']
val_loss = history.history['val_loss']
accuracy = history.history['accuracy']
val_accuracy = history.history['val_accuracy']
epochs = range(len(history.history['loss']))
# Plot loss
plt.plot(epochs, loss, label='training_loss')
plt.plot(epochs, val_loss, label='val_loss')
plt.title('Loss')
plt.xlabel('Epochs')
plt.legend()
# Plot accuracy
plt.figure()
plt.plot(epochs, accuracy, label='training_accuracy')
plt.plot(epochs, val_accuracy, label='val_accuracy')
plt.title('Accuracy')
plt.xlabel('Epochs')
plt.legend();
plot_loss_curves(resnet_history)


And what about a summary of our model?
# Resnet summary
resnet_model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
feature_extraction_layer (K (None, 2048) 23564800
erasLayer)
output_layer (Dense) (None, 10) 20490
=================================================================
Total params: 23,585,290
Trainable params: 20,490
Non-trainable params: 23,564,800
_________________________________________________________________
You can see the power of TensorFlow Hub here. The feature extraction layer has 23,564,800 parameters which are prelearned patterns the model has already learned on the ImageNet dataset. Since we set trainable=False, these patterns remain frozen (non-trainable) during training.
This means during training the model updates the 20,490 parameters in the output layer to suit our dataset.
Okay, we've trained a ResNetV250 model, time to do the same with EfficientNetB0 model.
The setup will be the exact same as before, except for the model_url parameter in the create_model() function and the experiment_name parameter in the create_tensorboard_callback() function.
# Create model
efficientnet_model = create_model(model_url=efficientnet_url, # use EfficientNetB0 TensorFlow Hub URL
num_classes=train_data_10_percent.num_classes)
# Compile EfficientNet model
efficientnet_model.compile(loss='categorical_crossentropy',
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
# Fit EfficientNet model
efficientnet_history = efficientnet_model.fit(train_data_10_percent, # only use 10% of training data
epochs=5, # train for 5 epochs
steps_per_epoch=len(train_data_10_percent),
validation_data=test_data,
validation_steps=len(test_data),
callbacks=[create_tensorboard_callback(dir_name="tensorflow_hub",
# Track logs under different experiment name
experiment_name="efficientnetB0")])
Saving TensorBoard log files to: tensorflow_hub/efficientnetB0/20230511-042443 Epoch 1/5 24/24 [==============================] - 26s 693ms/step - loss: 1.7622 - accuracy: 0.5053 - val_loss: 1.2434 - val_accuracy: 0.7268 Epoch 2/5 24/24 [==============================] - 15s 634ms/step - loss: 1.0120 - accuracy: 0.7693 - val_loss: 0.8459 - val_accuracy: 0.8240 Epoch 3/5 24/24 [==============================] - 15s 642ms/step - loss: 0.7289 - accuracy: 0.8347 - val_loss: 0.6823 - val_accuracy: 0.8460 Epoch 4/5 24/24 [==============================] - 15s 637ms/step - loss: 0.5871 - accuracy: 0.8667 - val_loss: 0.6004 - val_accuracy: 0.8592 Epoch 5/5 24/24 [==============================] - 14s 620ms/step - loss: 0.5013 - accuracy: 0.8947 - val_loss: 0.5504 - val_accuracy: 0.8636
Holy smokes! The EfficientNetB0 model does even better than the ResNetV250 model! Achieving over 85% accuracy on the test set...again with only 10% of the training data.
How cool is that?
With a couple of lines of code we're able to leverage state of the art models and adjust them to our own use case.
Let's check out the loss curves.
plot_loss_curves(efficientnet_history)


From the look of the EfficientNetB0 model's loss curves, it looks like if we kept training our model for longer, it might improve even further. Perhaps that's something you might want to try?
Let's check out the model summary.
efficientnet_model.summary()
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
feature_extraction_layer (K (None, 1280) 4049564
erasLayer)
output_layer (Dense) (None, 10) 12810
=================================================================
Total params: 4,062,374
Trainable params: 12,810
Non-trainable params: 4,049,564
_________________________________________________________________
It seems despite having over four times less parameters (4,049,564 vs. 23,564,800) than the ResNet50V2 extraction layer, the EfficientNetB0 feature extraction layer yields better performance. Now it's clear where the "efficient" name came from.
Comparing models using TensorBoard¶
Alright, even though we've already compared the performance of our two models by looking at the accuracy scores. But what if you had more than two models?
That's where an experiment tracking tool like TensorBoard (preinstalled in Google Colab) comes in.
The good thing is, since we set up a TensorBoard callback, all of our model's training logs have been saved automatically. To visualize them, we can upload the results to TensorBoard.dev.
Uploading your results to TensorBoard.dev enables you to track and share multiple different modelling experiments. So if you needed to show someone your results, you could send them a link to your TensorBoard.dev as well as the accompanying Colab notebook.
🔑 Note: These experiments are public, do not upload sensitive data. You can delete experiments if needed.
Uploading experiments to TensorBoard¶
To upload a series of TensorFlow logs to TensorBoard, we can use the following command:
Upload TensorBoard dev records
!tensorboard dev upload --logdir ./tensorflow_hub/ \
--name "EfficientNetB0 vs. ResNet50V2" \
--description "Comparing two different TF Hub feature extraction models architectures using 10% of training images" \
--one_shot
Where:
--logdiris the target upload directory--nameis the name of the experiment--descriptionis a brief description of the experiment--one_shotexits the TensorBoard uploader once uploading is finished
Running the tensorboard dev upload command will first ask you to authorize the upload to TensorBoard.dev. After you've authorized the upload, your log files will be uploaded.
# Upload TensorBoard dev records
!tensorboard dev upload --logdir ./tensorflow_hub/ \
--name "EfficientNetB0 vs. ResNet50V2" \
--description "Comparing two different TF Hub feature extraction models architectures using 10% of training images" \
--one_shot
2023-05-11 04:26:10.912881: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT ***** TensorBoard Uploader ***** This will upload your TensorBoard logs to https://tensorboard.dev/ from the following directory: ./tensorflow_hub/ This TensorBoard will be visible to everyone. Do not upload sensitive data. Your use of this service is subject to Google's Terms of Service <https://policies.google.com/terms> and Privacy Policy <https://policies.google.com/privacy>, and TensorBoard.dev's Terms of Service <https://tensorboard.dev/policy/terms/>. This notice will not be shown again while you are logged into the uploader. To log out, run `tensorboard dev auth revoke`. Continue? (yes/NO) yes To sign in with the TensorBoard uploader: 1. On your computer or phone, visit: https://www.google.com/device 2. Sign in with your Google account, then enter: PCB-DVW-YTS New experiment created. View your TensorBoard at: https://tensorboard.dev/experiment/dIzMI7IkT7OHD1PmA4mMRQ/ [2023-05-11T04:41:27] Started scanning logdir. [2023-05-11T04:41:32] Total uploaded: 60 scalars, 0 tensors, 2 binary objects (5.7 MB) [2023-05-11T04:41:32] Done scanning logdir. Done. View your TensorBoard at https://tensorboard.dev/experiment/dIzMI7IkT7OHD1PmA4mMRQ/
Every time you upload something to TensorBoad.dev you'll get a new experiment ID. The experiment ID will look something like this: https://tensorboard.dev/experiment/73taSKxXQeGPQsNBcVvY3g/ (this is the actual experiment from this notebook).
If you upload the same directory again, you'll get a new experiment ID to go along with it.
This means to track your experiments, you may want to look into how you name your uploads. That way when you find them on TensorBoard.dev you can tell what happened during each experiment (e.g. "efficientnet0_10_percent_data").
Listing experiments you've saved to TensorBoard¶
To see all of the experiments you've uploaded you can use the command:
tensorboard dev list
# Check out experiments
# !tensorboard dev list # uncomment to see
Deleting experiments from TensorBoard¶
Remember, all uploads to TensorBoard.dev are public, so to delete an experiment you can use the command:
tensorboard dev delete --experiment_id [INSERT_EXPERIMENT_ID]
# Delete an experiment
!tensorboard dev delete --experiment_id n6kd8XZ3Rdy1jSgSLH5WjA
2023-05-11 04:41:41.121171: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT No such experiment n6kd8XZ3Rdy1jSgSLH5WjA. Either it never existed or it has already been deleted.
# Check to see if experiments still exist
# !tensorboard dev list # uncomment to see
🛠 Exercises¶
- Build and fit a model using the same data we have here but with the MobileNetV2 architecture feature extraction (
mobilenet_v2_100_224/feature_vector) from TensorFlow Hub, how does it perform compared to our other models? - Name 3 different image classification models on TensorFlow Hub that we haven't used.
- Build a model to classify images of two different things you've taken photos of.
- You can use any feature extraction layer from TensorFlow Hub you like for this.
- You should aim to have at least 10 images of each class, for example to build a fridge versus oven classifier, you'll want 10 images of fridges and 10 images of ovens.
- What is the current best performing model on ImageNet?
- Hint: you might want to check sotabench.com for this.
📖 Extra-curriculum¶
- Read through the TensorFlow Transfer Learning Guide and define the main two types of transfer learning in your own words.
- Go through the Transfer Learning with TensorFlow Hub tutorial on the TensorFlow website and rewrite all of the code yourself into a new Google Colab notebook making comments about what each step does along the way.
- We haven't covered fine-tuning with TensorFlow Hub in this notebook, but if you'd like to know more, go through the fine-tuning a TensorFlow Hub model tutorial on the TensorFlow homepage.How to fine-tune a tensorflow hub model:
- Look into experiment tracking with Weights & Biases, how could you integrate it with our existing TensorBoard logs?