![]()
02. Neural Network Classification with TensorFlow¶
Okay, we've seen how to deal with a regression problem in TensorFlow, let's look at how we can approach a classification problem.
A classification problem involves predicting whether something is one thing or another.
For example, you might want to:
- Predict whether or not someone has heart disease based on their health parameters. This is called binary classification since there are only two options.
- Decide whether a photo of is of food, a person or a dog. This is called multi-class classification since there are more than two options.
- Predict what categories should be assigned to a Wikipedia article. This is called multi-label classification since a single article could have more than one category assigned.
In this notebook, we're going to work through a number of different classification problems with TensorFlow. In other words, taking a set of inputs and predicting what class those set of inputs belong to.
What we're going to cover¶
Specifically, we're going to go through doing the following with TensorFlow:
- Architecture of a classification model
- Input shapes and output shapes
X: features/data (inputs)y: labels (outputs)- "What class do the inputs belong to?"
- Creating custom data to view and fit
- Steps in modelling for binary and mutliclass classification
- Creating a model
- Compiling a model
- Defining a loss function
- Setting up an optimizer
- Finding the best learning rate
- Creating evaluation metrics
- Fitting a model (getting it to find patterns in our data)
- Improving a model
- The power of non-linearity
- Evaluating classification models
- Visualizng the model ("visualize, visualize, visualize")
- Looking at training curves
- Compare predictions to ground truth (using our evaluation metrics)
How you can use this notebook¶
You can read through the descriptions and the code (it should all run, except for the cells which error on purpose), but there's a better option.
Write all of the code yourself.
Yes. I'm serious. Create a new notebook, and rewrite each line by yourself. Investigate it, see if you can break it, why does it break?
You don't have to write the text descriptions but writing the code yourself is a great way to get hands-on experience.
Don't worry if you make mistakes, we all do. The way to get better and make less mistakes is to write more code.
Typical architecture of a classification neural network¶
The word typical is on purpose.
Because the architecture of a classification neural network can widely vary depending on the problem you're working on.
However, there are some fundamentals all deep neural networks contain:
- An input layer.
- Some hidden layers.
- An output layer.
Much of the rest is up to the data analyst creating the model.
The following are some standard values you'll often use in your classification neural networks.
| Hyperparameter | Binary Classification | Multiclass classification |
|---|---|---|
| Input layer shape | Same as number of features (e.g. 5 for age, sex, height, weight, smoking status in heart disease prediction) | Same as binary classification |
| Hidden layer(s) | Problem specific, minimum = 1, maximum = unlimited | Same as binary classification |
| Neurons per hidden layer | Problem specific, generally 10 to 100 | Same as binary classification |
| Output layer shape | 1 (one class or the other) | 1 per class (e.g. 3 for food, person or dog photo) |
| Hidden activation | Usually ReLU (rectified linear unit) | Same as binary classification |
| Output activation | Sigmoid | Softmax |
| Loss function | Cross entropy (tf.keras.losses.BinaryCrossentropy in TensorFlow) |
Cross entropy (tf.keras.losses.CategoricalCrossentropy in TensorFlow) |
| Optimizer | SGD (stochastic gradient descent), Adam | Same as binary classification |
Table 1: Typical architecture of a classification network. Source: Adapted from page 295 of Hands-On Machine Learning with Scikit-Learn, Keras & TensorFlow Book by Aurélien Géron
Don't worry if not much of the above makes sense right now, we'll get plenty of experience as we go through this notebook.
Let's start by importing TensorFlow as the common alias tf. For this notebook, make sure you're using version 2.x+.
import tensorflow as tf
print(tf.__version__)
import datetime
print(f"Notebook last run (end-to-end): {datetime.datetime.now()}")
2.13.0 Notebook last run (end-to-end): 2023-10-12 04:07:12.774646
Creating data to view and fit¶
We could start by importing a classification dataset but let's practice making some of our own classification data.
🔑 Note: It's a common practice to get you and model you build working on a toy (or simple) dataset before moving to your actual problem. Treat it as a rehersal experiment before the actual experiment(s).
Since classification is predicting whether something is one thing or another, let's make some data to reflect that.
To do so, we'll use Scikit-Learn's make_circles() function.
from sklearn.datasets import make_circles
# Make 1000 examples
n_samples = 1000
# Create circles
X, y = make_circles(n_samples,
noise=0.03,
random_state=42)
Wonderful, now we've created some data, let's look at the features (X) and labels (y).
# Check out the features
X
array([[ 0.75424625, 0.23148074],
[-0.75615888, 0.15325888],
[-0.81539193, 0.17328203],
...,
[-0.13690036, -0.81001183],
[ 0.67036156, -0.76750154],
[ 0.28105665, 0.96382443]])
# See the first 10 labels
y[:10]
array([1, 1, 1, 1, 0, 1, 1, 1, 1, 0])
Okay, we've seen some of our data and labels, how about we move towards visualizing?
🔑 Note: One important step of starting any kind of machine learning project is to become one with the data. And one of the best ways to do this is to visualize the data you're working with as much as possible. The data explorer's motto is "visualize, visualize, visualize".
We'll start with a DataFrame.
# Make dataframe of features and labels
import pandas as pd
circles = pd.DataFrame({"X0":X[:, 0], "X1":X[:, 1], "label":y})
circles.head()
| X0 | X1 | label | |
|---|---|---|---|
| 0 | 0.754246 | 0.231481 | 1 |
| 1 | -0.756159 | 0.153259 | 1 |
| 2 | -0.815392 | 0.173282 | 1 |
| 3 | -0.393731 | 0.692883 | 1 |
| 4 | 0.442208 | -0.896723 | 0 |
What kind of labels are we dealing with?
# Check out the different labels
circles.label.value_counts()
1 500 0 500 Name: label, dtype: int64
Alright, looks like we're dealing with a binary classification problem. It's binary because there are only two labels (0 or 1).
If there were more label options (e.g. 0, 1, 2, 3 or 4), it would be called multiclass classification.
Let's take our visualization a step further and plot our data.
# Visualize with a plot
import matplotlib.pyplot as plt
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.RdYlBu);

Nice! From the plot, can you guess what kind of model we might want to build?
How about we try and build one to classify blue or red dots? As in, a model which is able to distinguish blue from red dots.
🛠 Practice: Before pushing forward, you might want to spend 10 minutes playing around with the TensorFlow Playground. Try adjusting the different hyperparameters you see and click play to see a neural network train. I think you'll find the data very similar to what we've just created.
Input and output shapes¶
One of the most common issues you'll run into when building neural networks is shape mismatches.
More specifically, the shape of the input data and the shape of the output data.
In our case, we want to input X and get our model to predict y.
So let's check out the shapes of X and y.
# Check the shapes of our features and labels
X.shape, y.shape
((1000, 2), (1000,))
Hmm, where do these numbers come from?
# Check how many samples we have
len(X), len(y)
(1000, 1000)
So we've got as many X values as we do y values, that makes sense.
Let's check out one example of each.
# View the first example of features and labels
X[0], y[0]
(array([0.75424625, 0.23148074]), 1)
Alright, so we've got two X features which lead to one y value.
This means our neural network input shape will has to accept a tensor with at least one dimension being two and output a tensor with at least one value.
🤔 Note:
yhaving a shape of (1000,) can seem confusing. However, this is because allyvalues are actually scalars (single values) and therefore don't have a dimension. For now, think of your output shape as being at least the same value as one example ofy(in our case, the output from our neural network has to be at least one value).
Steps in modelling¶
Now we know what data we have as well as the input and output shapes, let's see how we'd build a neural network to model it.
In TensorFlow, there are typically 3 fundamental steps to creating and training a model.
- Creating a model - piece together the layers of a neural network yourself (using the functional or sequential API) or import a previously built model (known as transfer learning).
- Compiling a model - defining how a model's performance should be measured (loss/metrics) as well as defining how it should improve (optimizer).
- Fitting a model - letting the model try to find patterns in the data (how does
Xget toy).
Let's see these in action using the Sequential API to build a model for our regression data. And then we'll step through each.
# Set random seed
tf.random.set_seed(42)
# 1. Create the model using the Sequential API
model_1 = tf.keras.Sequential([
tf.keras.layers.Dense(1)
])
# 2. Compile the model
model_1.compile(loss=tf.keras.losses.BinaryCrossentropy(), # binary since we are working with 2 clases (0 & 1)
optimizer=tf.keras.optimizers.SGD(),
metrics=['accuracy'])
# 3. Fit the model
model_1.fit(X, y, epochs=5)
Epoch 1/5 32/32 [==============================] - 5s 3ms/step - loss: 5.9177 - accuracy: 0.4800 Epoch 2/5 32/32 [==============================] - 0s 3ms/step - loss: 5.1146 - accuracy: 0.4620 Epoch 3/5 32/32 [==============================] - 0s 3ms/step - loss: 4.6022 - accuracy: 0.4720 Epoch 4/5 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 5/5 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000
<keras.src.callbacks.History at 0x7a25080c58d0>
Looking at the accuracy metric, our model performs poorly (50% accuracy on a binary classification problem is the equivalent of guessing), but what if we trained it for longer?
# Train our model for longer (more chances to look at the data)
model_1.fit(X, y, epochs=200, verbose=0) # set verbose=0 to remove training updates
model_1.evaluate(X, y)
32/32 [==============================] - 0s 2ms/step - loss: 7.7125 - accuracy: 0.5000
[7.712474346160889, 0.5]
Even after 200 passes of the data, it's still performing as if it's guessing.
What if we added an extra layer and trained for a little longer?
# Set random seed
tf.random.set_seed(42)
# 1. Create the model (same as model_1 but with an extra layer)
model_2 = tf.keras.Sequential([
tf.keras.layers.Dense(1), # add an extra layer
tf.keras.layers.Dense(1)
])
# 2. Compile the model
model_2.compile(loss=tf.keras.losses.BinaryCrossentropy(),
optimizer=tf.keras.optimizers.SGD(),
metrics=['accuracy'])
# 3. Fit the model
model_2.fit(X, y, epochs=100, verbose=0) # set verbose=0 to make the output print less
<keras.src.callbacks.History at 0x7a24b4b323e0>
# Evaluate the model
model_2.evaluate(X, y)
32/32 [==============================] - 0s 2ms/step - loss: 0.6934 - accuracy: 0.5000
[0.6933949589729309, 0.5]
Still not even as good as guessing (~50% accuracy)... hmm...?
Let's remind ourselves of a couple more ways we can use to improve our models.
Improving a model¶
To improve our model, we can alter almost every part of the 3 steps we went through before.
- Creating a model - here you might want to add more layers, increase the number of hidden units (also called neurons) within each layer, change the activation functions of each layer.
- Compiling a model - you might want to choose a different optimization function (such as the Adam optimizer, which is usually pretty good for many problems) or perhaps change the learning rate of the optimization function.
- Fitting a model - perhaps you could fit a model for more epochs (leave it training for longer).
 There are many different ways to potentially improve a neural network. Some of the most common include: increasing the number of layers (making the network deeper), increasing the number of hidden units (making the network wider) and changing the learning rate. Because these values are all human-changeable, they're referred to as hyperparameters) and the practice of trying to find the best hyperparameters is referred to as hyperparameter tuning.
There are many different ways to potentially improve a neural network. Some of the most common include: increasing the number of layers (making the network deeper), increasing the number of hidden units (making the network wider) and changing the learning rate. Because these values are all human-changeable, they're referred to as hyperparameters) and the practice of trying to find the best hyperparameters is referred to as hyperparameter tuning.
How about we try adding more neurons, an extra layer and our friend the Adam optimizer?
Surely doing this will result in predictions better than guessing...
Note: The following message (below this one) can be ignored if you're running TensorFlow 2.8.0+, the error seems to have been fixed.
Note: If you're using TensorFlow 2.7.0+ (but not 2.8.0+) the original code from the following cells may have caused some errors. They've since been updated to fix those errors. You can see explanations on what happened at the following resources:
# Set random seed
tf.random.set_seed(42)
# 1. Create the model (this time 3 layers)
model_3 = tf.keras.Sequential([
# Before TensorFlow 2.7.0
# tf.keras.layers.Dense(100), # add 100 dense neurons
# With TensorFlow 2.7.0
# tf.keras.layers.Dense(100, input_shape=(None, 1)), # add 100 dense neurons
## After TensorFlow 2.8.0 ##
tf.keras.layers.Dense(100), # add 100 dense neurons
tf.keras.layers.Dense(10), # add another layer with 10 neurons
tf.keras.layers.Dense(1)
])
# 2. Compile the model
model_3.compile(loss=tf.keras.losses.BinaryCrossentropy(),
optimizer=tf.keras.optimizers.Adam(), # use Adam instead of SGD
metrics=['accuracy'])
# 3. Fit the model
model_3.fit(X, y, epochs=100, verbose=1) # fit for 100 passes of the data
Epoch 1/100 32/32 [==============================] - 2s 3ms/step - loss: 3.5433 - accuracy: 0.4520 Epoch 2/100 32/32 [==============================] - 0s 3ms/step - loss: 1.0533 - accuracy: 0.4910 Epoch 3/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7210 - accuracy: 0.5000 Epoch 4/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6998 - accuracy: 0.5000 Epoch 5/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6952 - accuracy: 0.4830 Epoch 6/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6941 - accuracy: 0.4910 Epoch 7/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6938 - accuracy: 0.4940 Epoch 8/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6945 - accuracy: 0.4990 Epoch 9/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6943 - accuracy: 0.4880 Epoch 10/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6945 - accuracy: 0.4550 Epoch 11/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6954 - accuracy: 0.4490 Epoch 12/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6946 - accuracy: 0.4860 Epoch 13/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6958 - accuracy: 0.4920 Epoch 14/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6949 - accuracy: 0.5150 Epoch 15/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6961 - accuracy: 0.4720 Epoch 16/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6943 - accuracy: 0.4880 Epoch 17/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6983 - accuracy: 0.4930 Epoch 18/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6945 - accuracy: 0.4730 Epoch 19/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6954 - accuracy: 0.5030 Epoch 20/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6957 - accuracy: 0.4600 Epoch 21/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6956 - accuracy: 0.4790 Epoch 22/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6948 - accuracy: 0.4440 Epoch 23/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6943 - accuracy: 0.4850 Epoch 24/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6962 - accuracy: 0.4690 Epoch 25/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6973 - accuracy: 0.5070 Epoch 26/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6978 - accuracy: 0.4870 Epoch 27/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6965 - accuracy: 0.5010 Epoch 28/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6947 - accuracy: 0.4690 Epoch 29/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6974 - accuracy: 0.4860 Epoch 30/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6997 - accuracy: 0.4870 Epoch 31/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6947 - accuracy: 0.5060 Epoch 32/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6965 - accuracy: 0.4710 Epoch 33/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6955 - accuracy: 0.4590 Epoch 34/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6972 - accuracy: 0.4770 Epoch 35/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6961 - accuracy: 0.5020 Epoch 36/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6946 - accuracy: 0.4680 Epoch 37/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6952 - accuracy: 0.4980 Epoch 38/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6976 - accuracy: 0.4930 Epoch 39/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6950 - accuracy: 0.4750 Epoch 40/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6966 - accuracy: 0.4970 Epoch 41/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6978 - accuracy: 0.4840 Epoch 42/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6994 - accuracy: 0.4770 Epoch 43/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6954 - accuracy: 0.5060 Epoch 44/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6982 - accuracy: 0.4900 Epoch 45/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6960 - accuracy: 0.5040 Epoch 46/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6948 - accuracy: 0.4810 Epoch 47/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6974 - accuracy: 0.5120 Epoch 48/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6967 - accuracy: 0.4930 Epoch 49/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6975 - accuracy: 0.4820 Epoch 50/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6970 - accuracy: 0.4640 Epoch 51/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6977 - accuracy: 0.4810 Epoch 52/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6963 - accuracy: 0.5080 Epoch 53/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6969 - accuracy: 0.5070 Epoch 54/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6997 - accuracy: 0.5120 Epoch 55/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6952 - accuracy: 0.5180 Epoch 56/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6965 - accuracy: 0.4890 Epoch 57/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6980 - accuracy: 0.4730 Epoch 58/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6965 - accuracy: 0.5080 Epoch 59/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7003 - accuracy: 0.4970 Epoch 60/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7009 - accuracy: 0.4930 Epoch 61/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6997 - accuracy: 0.4710 Epoch 62/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6965 - accuracy: 0.4950 Epoch 63/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6948 - accuracy: 0.4840 Epoch 64/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6961 - accuracy: 0.4920 Epoch 65/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6993 - accuracy: 0.4830 Epoch 66/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6966 - accuracy: 0.4980 Epoch 67/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6977 - accuracy: 0.4490 Epoch 68/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6958 - accuracy: 0.5060 Epoch 69/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6949 - accuracy: 0.5280 Epoch 70/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6987 - accuracy: 0.4720 Epoch 71/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6976 - accuracy: 0.4720 Epoch 72/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6965 - accuracy: 0.5010 Epoch 73/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6960 - accuracy: 0.4890 Epoch 74/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6958 - accuracy: 0.5050 Epoch 75/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6960 - accuracy: 0.5070 Epoch 76/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6980 - accuracy: 0.4810 Epoch 77/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6972 - accuracy: 0.4990 Epoch 78/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6972 - accuracy: 0.4710 Epoch 79/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7007 - accuracy: 0.5130 Epoch 80/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6978 - accuracy: 0.5000 Epoch 81/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6975 - accuracy: 0.5020 Epoch 82/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6966 - accuracy: 0.4880 Epoch 83/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7003 - accuracy: 0.4510 Epoch 84/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6964 - accuracy: 0.5010 Epoch 85/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6968 - accuracy: 0.4660 Epoch 86/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7005 - accuracy: 0.4940 Epoch 87/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6976 - accuracy: 0.4540 Epoch 88/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6981 - accuracy: 0.4570 Epoch 89/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6982 - accuracy: 0.4740 Epoch 90/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6978 - accuracy: 0.4560 Epoch 91/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6980 - accuracy: 0.4880 Epoch 92/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6984 - accuracy: 0.4730 Epoch 93/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6982 - accuracy: 0.4710 Epoch 94/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7001 - accuracy: 0.4790 Epoch 95/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6972 - accuracy: 0.4560 Epoch 96/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6979 - accuracy: 0.4860 Epoch 97/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6972 - accuracy: 0.4580 Epoch 98/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6987 - accuracy: 0.4800 Epoch 99/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6975 - accuracy: 0.5080 Epoch 100/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6967 - accuracy: 0.4810
<keras.src.callbacks.History at 0x7a249bd86620>
Still!
We've pulled out a few tricks but our model isn't even doing better than guessing.
Let's make some visualizations to see what's happening.
🔑 Note: Whenever your model is performing strangely or there's something going on with your data you're not quite sure of, remember these three words: visualize, visualize, visualize. Inspect your data, inspect your model, inpsect your model's predictions.
To visualize our model's predictions we're going to create a function plot_decision_boundary() which:
- Takes in a trained model, features (
X) and labels (y). - Creates a meshgrid of the different
Xvalues. - Makes predictions across the meshgrid.
- Plots the predictions as well as a line between the different zones (where each unique class falls).
If this sounds confusing, let's see it in code and then see the output.
🔑 Note: If you're ever unsure of what a function does, try unraveling it and writing it line by line for yourself to see what it does. Break it into small parts and see what each part outputs.
import numpy as np
def plot_decision_boundary(model, X, y):
"""
Plots the decision boundary created by a model predicting on X.
This function has been adapted from two phenomenal resources:
1. CS231n - https://cs231n.github.io/neural-networks-case-study/
2. Made with ML basics - https://github.com/GokuMohandas/MadeWithML/blob/main/notebooks/08_Neural_Networks.ipynb
"""
# Define the axis boundaries of the plot and create a meshgrid
x_min, x_max = X[:, 0].min() - 0.1, X[:, 0].max() + 0.1
y_min, y_max = X[:, 1].min() - 0.1, X[:, 1].max() + 0.1
xx, yy = np.meshgrid(np.linspace(x_min, x_max, 100),
np.linspace(y_min, y_max, 100))
# Create X values (we're going to predict on all of these)
x_in = np.c_[xx.ravel(), yy.ravel()] # stack 2D arrays together: https://numpy.org/devdocs/reference/generated/numpy.c_.html
# Make predictions using the trained model
y_pred = model.predict(x_in)
# Check for multi-class
if model.output_shape[-1] > 1: # checks the final dimension of the model's output shape, if this is > (greater than) 1, it's multi-class
print("doing multiclass classification...")
# We have to reshape our predictions to get them ready for plotting
y_pred = np.argmax(y_pred, axis=1).reshape(xx.shape)
else:
print("doing binary classifcation...")
y_pred = np.round(np.max(y_pred, axis=1)).reshape(xx.shape)
# Plot decision boundary
plt.contourf(xx, yy, y_pred, cmap=plt.cm.RdYlBu, alpha=0.7)
plt.scatter(X[:, 0], X[:, 1], c=y, s=40, cmap=plt.cm.RdYlBu)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
Now we've got a function to plot our model's decision boundary (the cut off point its making between red and blue dots), let's try it out.
# Check out the predictions our model is making
plot_decision_boundary(model_3, X, y)
313/313 [==============================] - 0s 1ms/step doing binary classifcation...

Looks like our model is trying to draw a straight line through the data.
What's wrong with doing this?
The main issue is our data isn't separable by a straight line.
In a regression problem, our model might work. In fact, let's try it.
# Set random seed
tf.random.set_seed(42)
# Create some regression data
X_regression = np.arange(0, 1000, 5)
y_regression = np.arange(100, 1100, 5)
# Split it into training and test sets
X_reg_train = X_regression[:150]
X_reg_test = X_regression[150:]
y_reg_train = y_regression[:150]
y_reg_test = y_regression[150:]
# Fit our model to the data
# Note: Before TensorFlow 2.7.0, this line would work
# model_3.fit(X_reg_train, y_reg_train, epochs=100)
# After TensorFlow 2.7.0, see here for more: https://github.com/mrdbourke/tensorflow-deep-learning/discussions/278
model_3.fit(tf.expand_dims(X_reg_train, axis=-1),
y_reg_train,
epochs=100)
Epoch 1/100
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-18-2f683d96fa34> in <cell line: 19>() 17 18 # After TensorFlow 2.7.0, see here for more: https://github.com/mrdbourke/tensorflow-deep-learning/discussions/278 ---> 19 model_3.fit(tf.expand_dims(X_reg_train, axis=-1), 20 y_reg_train, 21 epochs=100) /usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py in error_handler(*args, **kwargs) 68 # To get the full stack trace, call: 69 # `tf.debugging.disable_traceback_filtering()` ---> 70 raise e.with_traceback(filtered_tb) from None 71 finally: 72 del filtered_tb /usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py in tf__train_function(iterator) 13 try: 14 do_return = True ---> 15 retval_ = ag__.converted_call(ag__.ld(step_function), (ag__.ld(self), ag__.ld(iterator)), None, fscope) 16 except: 17 do_return = False ValueError: in user code: File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 1338, in train_function * return step_function(self, iterator) File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 1322, in step_function ** outputs = model.distribute_strategy.run(run_step, args=(data,)) File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 1303, in run_step ** outputs = model.train_step(data) File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/training.py", line 1080, in train_step y_pred = self(x, training=True) File "/usr/local/lib/python3.10/dist-packages/keras/src/utils/traceback_utils.py", line 70, in error_handler raise e.with_traceback(filtered_tb) from None File "/usr/local/lib/python3.10/dist-packages/keras/src/engine/input_spec.py", line 280, in assert_input_compatibility raise ValueError( ValueError: Exception encountered when calling layer 'sequential_2' (type Sequential). Input 0 of layer "dense_3" is incompatible with the layer: expected axis -1 of input shape to have value 2, but received input with shape (None, 1) Call arguments received by layer 'sequential_2' (type Sequential): • inputs=tf.Tensor(shape=(None, 1), dtype=int64) • training=True • mask=None
model_3.summary()
Model: "sequential_2"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_3 (Dense) (None, 100) 300
dense_4 (Dense) (None, 10) 1010
dense_5 (Dense) (None, 1) 11
=================================================================
Total params: 1321 (5.16 KB)
Trainable params: 1321 (5.16 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Oh wait... we compiled our model for a binary classification problem.
No trouble, we can recreate it for a regression problem.
# Setup random seed
tf.random.set_seed(42)
# Recreate the model
model_3 = tf.keras.Sequential([
tf.keras.layers.Dense(100),
tf.keras.layers.Dense(10),
tf.keras.layers.Dense(1)
])
# Change the loss and metrics of our compiled model
model_3.compile(loss=tf.keras.losses.mae, # change the loss function to be regression-specific
optimizer=tf.keras.optimizers.Adam(),
metrics=['mae']) # change the metric to be regression-specific
# Fit the recompiled model
model_3.fit(tf.expand_dims(X_reg_train, axis=-1),
y_reg_train,
epochs=100)
Epoch 1/100 5/5 [==============================] - 1s 5ms/step - loss: 447.6102 - mae: 447.6102 Epoch 2/100 5/5 [==============================] - 0s 4ms/step - loss: 313.3108 - mae: 313.3108 Epoch 3/100 5/5 [==============================] - 0s 4ms/step - loss: 182.3118 - mae: 182.3118 Epoch 4/100 5/5 [==============================] - 0s 4ms/step - loss: 58.6317 - mae: 58.6317 Epoch 5/100 5/5 [==============================] - 0s 4ms/step - loss: 83.0025 - mae: 83.0025 Epoch 6/100 5/5 [==============================] - 0s 4ms/step - loss: 86.4671 - mae: 86.4671 Epoch 7/100 5/5 [==============================] - 0s 3ms/step - loss: 49.6151 - mae: 49.6151 Epoch 8/100 5/5 [==============================] - 0s 4ms/step - loss: 57.7703 - mae: 57.7703 Epoch 9/100 5/5 [==============================] - 0s 3ms/step - loss: 50.1641 - mae: 50.1641 Epoch 10/100 5/5 [==============================] - 0s 4ms/step - loss: 47.7698 - mae: 47.7698 Epoch 11/100 5/5 [==============================] - 0s 4ms/step - loss: 48.6194 - mae: 48.6194 Epoch 12/100 5/5 [==============================] - 0s 4ms/step - loss: 43.2044 - mae: 43.2044 Epoch 13/100 5/5 [==============================] - 0s 4ms/step - loss: 42.6293 - mae: 42.6293 Epoch 14/100 5/5 [==============================] - 0s 4ms/step - loss: 42.4557 - mae: 42.4557 Epoch 15/100 5/5 [==============================] - 0s 4ms/step - loss: 41.9446 - mae: 41.9446 Epoch 16/100 5/5 [==============================] - 0s 4ms/step - loss: 41.7290 - mae: 41.7290 Epoch 17/100 5/5 [==============================] - 0s 4ms/step - loss: 41.5669 - mae: 41.5669 Epoch 18/100 5/5 [==============================] - 0s 4ms/step - loss: 41.2955 - mae: 41.2955 Epoch 19/100 5/5 [==============================] - 0s 4ms/step - loss: 41.1274 - mae: 41.1274 Epoch 20/100 5/5 [==============================] - 0s 4ms/step - loss: 41.1121 - mae: 41.1121 Epoch 21/100 5/5 [==============================] - 0s 4ms/step - loss: 41.1519 - mae: 41.1519 Epoch 22/100 5/5 [==============================] - 0s 4ms/step - loss: 41.0565 - mae: 41.0565 Epoch 23/100 5/5 [==============================] - 0s 4ms/step - loss: 41.1133 - mae: 41.1133 Epoch 24/100 5/5 [==============================] - 0s 60ms/step - loss: 41.0074 - mae: 41.0074 Epoch 25/100 5/5 [==============================] - 0s 4ms/step - loss: 40.9870 - mae: 40.9870 Epoch 26/100 5/5 [==============================] - 0s 4ms/step - loss: 41.0249 - mae: 41.0249 Epoch 27/100 5/5 [==============================] - 0s 3ms/step - loss: 40.8403 - mae: 40.8403 Epoch 28/100 5/5 [==============================] - 0s 4ms/step - loss: 40.9965 - mae: 40.9965 Epoch 29/100 5/5 [==============================] - 0s 4ms/step - loss: 41.0225 - mae: 41.0225 Epoch 30/100 5/5 [==============================] - 0s 4ms/step - loss: 40.8058 - mae: 40.8058 Epoch 31/100 5/5 [==============================] - 0s 4ms/step - loss: 41.3589 - mae: 41.3589 Epoch 32/100 5/5 [==============================] - 0s 4ms/step - loss: 41.0084 - mae: 41.0084 Epoch 33/100 5/5 [==============================] - 0s 4ms/step - loss: 41.0701 - mae: 41.0701 Epoch 34/100 5/5 [==============================] - 0s 4ms/step - loss: 41.2035 - mae: 41.2035 Epoch 35/100 5/5 [==============================] - 0s 3ms/step - loss: 40.5885 - mae: 40.5885 Epoch 36/100 5/5 [==============================] - 0s 4ms/step - loss: 41.0615 - mae: 41.0615 Epoch 37/100 5/5 [==============================] - 0s 4ms/step - loss: 40.6438 - mae: 40.6438 Epoch 38/100 5/5 [==============================] - 0s 4ms/step - loss: 40.3412 - mae: 40.3412 Epoch 39/100 5/5 [==============================] - 0s 4ms/step - loss: 40.6498 - mae: 40.6498 Epoch 40/100 5/5 [==============================] - 0s 4ms/step - loss: 40.4421 - mae: 40.4421 Epoch 41/100 5/5 [==============================] - 0s 4ms/step - loss: 40.3558 - mae: 40.3558 Epoch 42/100 5/5 [==============================] - 0s 4ms/step - loss: 40.3041 - mae: 40.3041 Epoch 43/100 5/5 [==============================] - 0s 4ms/step - loss: 40.5277 - mae: 40.5277 Epoch 44/100 5/5 [==============================] - 0s 4ms/step - loss: 40.1808 - mae: 40.1808 Epoch 45/100 5/5 [==============================] - 0s 4ms/step - loss: 40.6292 - mae: 40.6292 Epoch 46/100 5/5 [==============================] - 0s 3ms/step - loss: 40.4382 - mae: 40.4382 Epoch 47/100 5/5 [==============================] - 0s 4ms/step - loss: 40.1801 - mae: 40.1801 Epoch 48/100 5/5 [==============================] - 0s 4ms/step - loss: 40.2386 - mae: 40.2386 Epoch 49/100 5/5 [==============================] - 0s 3ms/step - loss: 40.7914 - mae: 40.7914 Epoch 50/100 5/5 [==============================] - 0s 3ms/step - loss: 40.1259 - mae: 40.1259 Epoch 51/100 5/5 [==============================] - 0s 4ms/step - loss: 40.4617 - mae: 40.4617 Epoch 52/100 5/5 [==============================] - 0s 4ms/step - loss: 40.8686 - mae: 40.8686 Epoch 53/100 5/5 [==============================] - 0s 4ms/step - loss: 41.0441 - mae: 41.0441 Epoch 54/100 5/5 [==============================] - 0s 4ms/step - loss: 41.1022 - mae: 41.1022 Epoch 55/100 5/5 [==============================] - 0s 4ms/step - loss: 42.1498 - mae: 42.1498 Epoch 56/100 5/5 [==============================] - 0s 4ms/step - loss: 42.3732 - mae: 42.3732 Epoch 57/100 5/5 [==============================] - 0s 4ms/step - loss: 40.9868 - mae: 40.9868 Epoch 58/100 5/5 [==============================] - 0s 4ms/step - loss: 40.4022 - mae: 40.4022 Epoch 59/100 5/5 [==============================] - 0s 4ms/step - loss: 41.1762 - mae: 41.1762 Epoch 60/100 5/5 [==============================] - 0s 4ms/step - loss: 40.0280 - mae: 40.0280 Epoch 61/100 5/5 [==============================] - 0s 4ms/step - loss: 39.4377 - mae: 39.4377 Epoch 62/100 5/5 [==============================] - 0s 4ms/step - loss: 40.2227 - mae: 40.2227 Epoch 63/100 5/5 [==============================] - 0s 4ms/step - loss: 39.7379 - mae: 39.7379 Epoch 64/100 5/5 [==============================] - 0s 4ms/step - loss: 39.4851 - mae: 39.4851 Epoch 65/100 5/5 [==============================] - 0s 4ms/step - loss: 39.8735 - mae: 39.8735 Epoch 66/100 5/5 [==============================] - 0s 4ms/step - loss: 39.5498 - mae: 39.5498 Epoch 67/100 5/5 [==============================] - 0s 3ms/step - loss: 39.5944 - mae: 39.5944 Epoch 68/100 5/5 [==============================] - 0s 3ms/step - loss: 39.5087 - mae: 39.5087 Epoch 69/100 5/5 [==============================] - 0s 3ms/step - loss: 39.3758 - mae: 39.3758 Epoch 70/100 5/5 [==============================] - 0s 4ms/step - loss: 39.8543 - mae: 39.8543 Epoch 71/100 5/5 [==============================] - 0s 4ms/step - loss: 41.2924 - mae: 41.2924 Epoch 72/100 5/5 [==============================] - 0s 4ms/step - loss: 39.0309 - mae: 39.0309 Epoch 73/100 5/5 [==============================] - 0s 3ms/step - loss: 39.7582 - mae: 39.7582 Epoch 74/100 5/5 [==============================] - 0s 4ms/step - loss: 39.1621 - mae: 39.1621 Epoch 75/100 5/5 [==============================] - 0s 4ms/step - loss: 39.9158 - mae: 39.9158 Epoch 76/100 5/5 [==============================] - 0s 4ms/step - loss: 40.2419 - mae: 40.2419 Epoch 77/100 5/5 [==============================] - 0s 4ms/step - loss: 38.9030 - mae: 38.9030 Epoch 78/100 5/5 [==============================] - 0s 3ms/step - loss: 39.5400 - mae: 39.5400 Epoch 79/100 5/5 [==============================] - 0s 3ms/step - loss: 39.2044 - mae: 39.2044 Epoch 80/100 5/5 [==============================] - 0s 3ms/step - loss: 38.7893 - mae: 38.7893 Epoch 81/100 5/5 [==============================] - 0s 3ms/step - loss: 38.8879 - mae: 38.8879 Epoch 82/100 5/5 [==============================] - 0s 4ms/step - loss: 38.9441 - mae: 38.9441 Epoch 83/100 5/5 [==============================] - 0s 4ms/step - loss: 38.6721 - mae: 38.6721 Epoch 84/100 5/5 [==============================] - 0s 4ms/step - loss: 38.7601 - mae: 38.7601 Epoch 85/100 5/5 [==============================] - 0s 4ms/step - loss: 39.0045 - mae: 39.0045 Epoch 86/100 5/5 [==============================] - 0s 4ms/step - loss: 38.9378 - mae: 38.9378 Epoch 87/100 5/5 [==============================] - 0s 3ms/step - loss: 38.3988 - mae: 38.3988 Epoch 88/100 5/5 [==============================] - 0s 3ms/step - loss: 38.5840 - mae: 38.5840 Epoch 89/100 5/5 [==============================] - 0s 3ms/step - loss: 38.4868 - mae: 38.4868 Epoch 90/100 5/5 [==============================] - 0s 4ms/step - loss: 38.3730 - mae: 38.3730 Epoch 91/100 5/5 [==============================] - 0s 3ms/step - loss: 38.2209 - mae: 38.2209 Epoch 92/100 5/5 [==============================] - 0s 4ms/step - loss: 38.3540 - mae: 38.3540 Epoch 93/100 5/5 [==============================] - 0s 4ms/step - loss: 38.6931 - mae: 38.6931 Epoch 94/100 5/5 [==============================] - 0s 4ms/step - loss: 37.9931 - mae: 37.9931 Epoch 95/100 5/5 [==============================] - 0s 4ms/step - loss: 38.0585 - mae: 38.0585 Epoch 96/100 5/5 [==============================] - 0s 4ms/step - loss: 38.4031 - mae: 38.4031 Epoch 97/100 5/5 [==============================] - 0s 4ms/step - loss: 38.0610 - mae: 38.0610 Epoch 98/100 5/5 [==============================] - 0s 4ms/step - loss: 38.3810 - mae: 38.3810 Epoch 99/100 5/5 [==============================] - 0s 4ms/step - loss: 38.4900 - mae: 38.4900 Epoch 100/100 5/5 [==============================] - 0s 4ms/step - loss: 37.9673 - mae: 37.9673
<keras.src.callbacks.History at 0x7a24c5b179a0>
Okay, it seems like our model is learning something (the mae value trends down with each epoch), let's plot its predictions.
# Make predictions with our trained model
y_reg_preds = model_3.predict(X_reg_test)
# Plot the model's predictions against our regression data
plt.figure(figsize=(10, 7))
plt.scatter(X_reg_train, y_reg_train, c='b', label='Training data')
plt.scatter(X_reg_test, y_reg_test, c='g', label='Testing data')
plt.scatter(X_reg_test, y_reg_preds.squeeze(), c='r', label='Predictions')
plt.legend();
2/2 [==============================] - 0s 4ms/step

Okay, the predictions aren't perfect (if the predictions were perfect, the red would line up with the green), but they look better than complete guessing.
So this means our model must be learning something...
There must be something we're missing out on for our classification problem.
The missing piece: Non-linearity¶
Okay, so we saw our neural network can model straight lines (with ability a little bit better than guessing).
What about non-straight (non-linear) lines?
If we're going to model our classification data (the red and blue circles), we're going to need some non-linear lines.
🔨 Practice: Before we get to the next steps, I'd encourage you to play around with the TensorFlow Playground (check out what the data has in common with our own classification data) for 10-minutes. In particular the tab which says "activation". Once you're done, come back.
Did you try out the activation options? If so, what did you find?
If you didn't, don't worry, let's see it in code.
We're going to replicate the neural network you can see at this link: TensorFlow Playground.
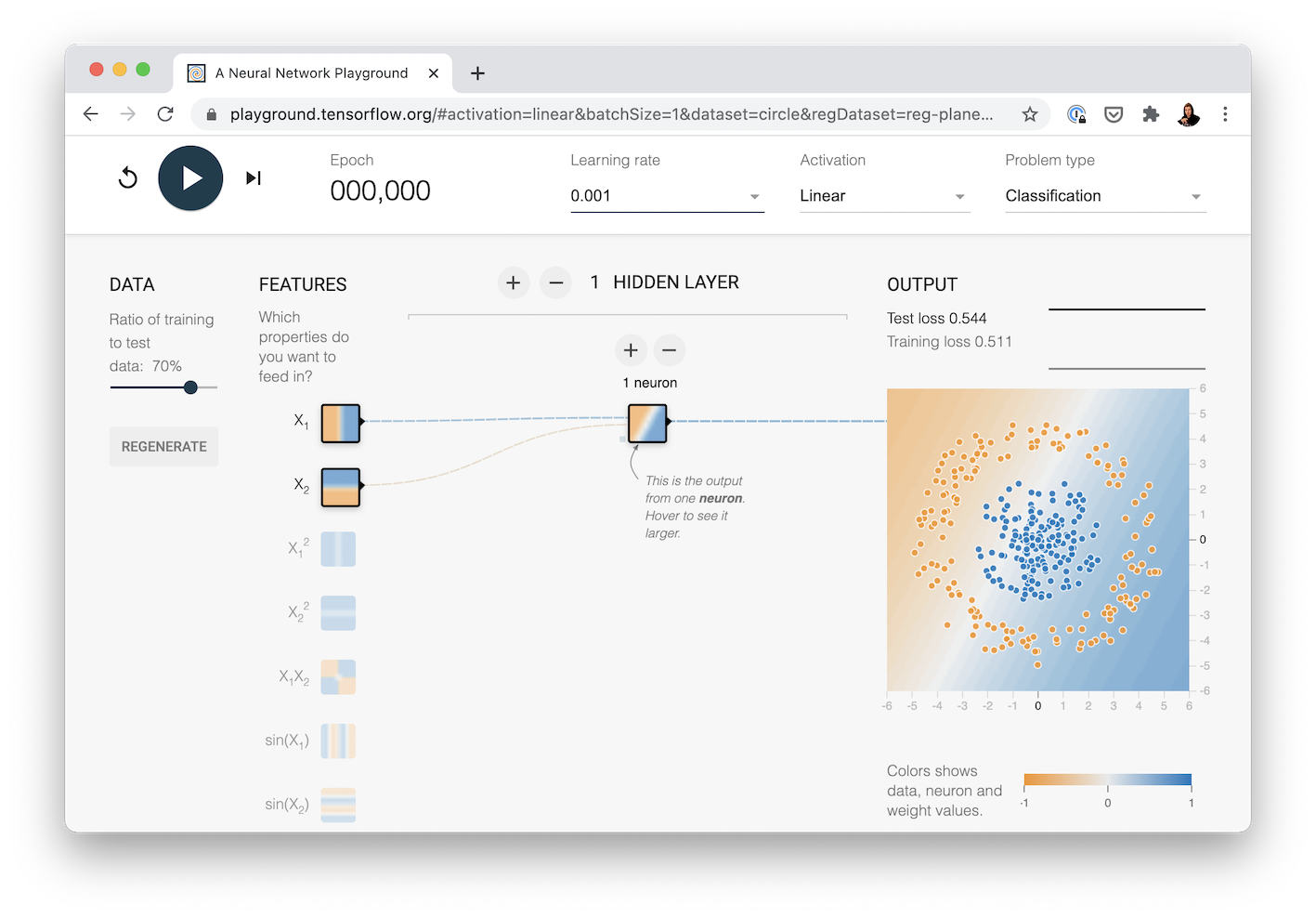 The neural network we're going to recreate with TensorFlow code. See it live at TensorFlow Playground.
The neural network we're going to recreate with TensorFlow code. See it live at TensorFlow Playground.
The main change we'll add to models we've built before is the use of the activation keyword.
# Set the random seed
tf.random.set_seed(42)
# Create the model
model_4 = tf.keras.Sequential([
tf.keras.layers.Dense(1, activation=tf.keras.activations.linear), # 1 hidden layer with linear activation
tf.keras.layers.Dense(1) # output layer
])
# Compile the model
model_4.compile(loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), # note: "lr" used to be what was used, now "learning_rate" is favoured
metrics=["accuracy"])
# Fit the model
history = model_4.fit(X, y, epochs=100)
Epoch 1/100 32/32 [==============================] - 1s 3ms/step - loss: 4.2584 - accuracy: 0.5000 Epoch 2/100 32/32 [==============================] - 0s 3ms/step - loss: 4.0332 - accuracy: 0.5000 Epoch 3/100 32/32 [==============================] - 0s 3ms/step - loss: 3.8635 - accuracy: 0.4970 Epoch 4/100 32/32 [==============================] - 0s 3ms/step - loss: 3.6277 - accuracy: 0.4670 Epoch 5/100 32/32 [==============================] - 0s 3ms/step - loss: 3.3772 - accuracy: 0.4490 Epoch 6/100 32/32 [==============================] - 0s 3ms/step - loss: 3.0635 - accuracy: 0.4460 Epoch 7/100 32/32 [==============================] - 0s 3ms/step - loss: 2.7472 - accuracy: 0.4450 Epoch 8/100 32/32 [==============================] - 0s 3ms/step - loss: 2.1925 - accuracy: 0.4470 Epoch 9/100 32/32 [==============================] - 0s 3ms/step - loss: 1.1191 - accuracy: 0.4790 Epoch 10/100 32/32 [==============================] - 0s 3ms/step - loss: 0.9511 - accuracy: 0.4900 Epoch 11/100 32/32 [==============================] - 0s 3ms/step - loss: 0.9207 - accuracy: 0.4880 Epoch 12/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8991 - accuracy: 0.4850 Epoch 13/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8814 - accuracy: 0.4770 Epoch 14/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8662 - accuracy: 0.4720 Epoch 15/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8530 - accuracy: 0.4620 Epoch 16/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8421 - accuracy: 0.4510 Epoch 17/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8320 - accuracy: 0.4470 Epoch 18/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8227 - accuracy: 0.4420 Epoch 19/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8146 - accuracy: 0.4330 Epoch 20/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8070 - accuracy: 0.4290 Epoch 21/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8001 - accuracy: 0.4210 Epoch 22/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7937 - accuracy: 0.4140 Epoch 23/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7877 - accuracy: 0.4090 Epoch 24/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7823 - accuracy: 0.4090 Epoch 25/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7771 - accuracy: 0.4100 Epoch 26/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7722 - accuracy: 0.4140 Epoch 27/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7677 - accuracy: 0.4220 Epoch 28/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7633 - accuracy: 0.4320 Epoch 29/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7594 - accuracy: 0.4350 Epoch 30/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7557 - accuracy: 0.4460 Epoch 31/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7522 - accuracy: 0.4480 Epoch 32/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7489 - accuracy: 0.4470 Epoch 33/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7460 - accuracy: 0.4540 Epoch 34/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7432 - accuracy: 0.4520 Epoch 35/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7406 - accuracy: 0.4590 Epoch 36/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7381 - accuracy: 0.4620 Epoch 37/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7357 - accuracy: 0.4640 Epoch 38/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7335 - accuracy: 0.4640 Epoch 39/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7314 - accuracy: 0.4660 Epoch 40/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7295 - accuracy: 0.4670 Epoch 41/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7276 - accuracy: 0.4720 Epoch 42/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7259 - accuracy: 0.4740 Epoch 43/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7241 - accuracy: 0.4780 Epoch 44/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7227 - accuracy: 0.4770 Epoch 45/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7212 - accuracy: 0.4770 Epoch 46/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7198 - accuracy: 0.4760 Epoch 47/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7186 - accuracy: 0.4760 Epoch 48/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7173 - accuracy: 0.4780 Epoch 49/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7161 - accuracy: 0.4810 Epoch 50/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7150 - accuracy: 0.4780 Epoch 51/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7139 - accuracy: 0.4800 Epoch 52/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7129 - accuracy: 0.4820 Epoch 53/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7119 - accuracy: 0.4850 Epoch 54/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7110 - accuracy: 0.4850 Epoch 55/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7101 - accuracy: 0.4880 Epoch 56/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7092 - accuracy: 0.4870 Epoch 57/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7085 - accuracy: 0.4860 Epoch 58/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7078 - accuracy: 0.4910 Epoch 59/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7072 - accuracy: 0.4870 Epoch 60/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7064 - accuracy: 0.4900 Epoch 61/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7058 - accuracy: 0.4890 Epoch 62/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7053 - accuracy: 0.4900 Epoch 63/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7046 - accuracy: 0.4900 Epoch 64/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7041 - accuracy: 0.4900 Epoch 65/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7036 - accuracy: 0.4910 Epoch 66/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7031 - accuracy: 0.4870 Epoch 67/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7026 - accuracy: 0.4880 Epoch 68/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7022 - accuracy: 0.4880 Epoch 69/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7017 - accuracy: 0.4860 Epoch 70/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7013 - accuracy: 0.4860 Epoch 71/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7009 - accuracy: 0.4870 Epoch 72/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7005 - accuracy: 0.4900 Epoch 73/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7002 - accuracy: 0.4890 Epoch 74/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6999 - accuracy: 0.4890 Epoch 75/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6996 - accuracy: 0.4900 Epoch 76/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6993 - accuracy: 0.4900 Epoch 77/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6990 - accuracy: 0.4890 Epoch 78/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6987 - accuracy: 0.4890 Epoch 79/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6984 - accuracy: 0.4890 Epoch 80/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6981 - accuracy: 0.4870 Epoch 81/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6978 - accuracy: 0.4850 Epoch 82/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6976 - accuracy: 0.4850 Epoch 83/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6974 - accuracy: 0.4860 Epoch 84/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6971 - accuracy: 0.4870 Epoch 85/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6969 - accuracy: 0.4880 Epoch 86/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6968 - accuracy: 0.4880 Epoch 87/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6965 - accuracy: 0.4900 Epoch 88/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6964 - accuracy: 0.4860 Epoch 89/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6963 - accuracy: 0.4840 Epoch 90/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6962 - accuracy: 0.4900 Epoch 91/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6959 - accuracy: 0.4890 Epoch 92/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6958 - accuracy: 0.4880 Epoch 93/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6957 - accuracy: 0.4910 Epoch 94/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6956 - accuracy: 0.4860 Epoch 95/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6954 - accuracy: 0.4880 Epoch 96/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6953 - accuracy: 0.4850 Epoch 97/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6952 - accuracy: 0.4880 Epoch 98/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6951 - accuracy: 0.4880 Epoch 99/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6950 - accuracy: 0.4850 Epoch 100/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6948 - accuracy: 0.4900
Okay, our model performs a little worse than guessing.
Let's remind ourselves what our data looks like.
# Check out our data
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.RdYlBu);
And let's see how our model is making predictions on it.
# Check the deicison boundary (blue is blue class, yellow is the crossover, red is red class)
plot_decision_boundary(model_4, X, y)
313/313 [==============================] - 0s 1ms/step doing binary classifcation...

Well, it looks like we're getting a straight (linear) line prediction again.
But our data is non-linear (not a straight line)...
What we're going to have to do is add some non-linearity to our model.
To do so, we'll use the activation parameter in on of our layers.
# Set random seed
tf.random.set_seed(42)
# Create a model with a non-linear activation
model_5 = tf.keras.Sequential([
tf.keras.layers.Dense(1, activation=tf.keras.activations.relu), # can also do activation='relu'
tf.keras.layers.Dense(1) # output layer
])
# Compile the model
model_5.compile(loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
# Fit the model
history = model_5.fit(X, y, epochs=100)
Epoch 1/100 32/32 [==============================] - 1s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 2/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 3/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 4/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 5/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 6/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 7/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 8/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 9/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 10/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 11/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 12/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 13/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 14/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 15/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 16/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 17/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 18/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 19/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 20/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 21/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 22/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 23/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 24/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 25/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 26/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 27/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 28/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 29/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 30/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 31/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 32/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 33/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 34/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 35/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 36/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 37/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 38/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 39/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 40/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 41/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 42/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 43/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 44/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 45/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 46/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 47/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 48/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 49/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 50/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 51/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 52/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 53/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 54/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 55/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 56/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 57/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 58/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 59/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 60/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 61/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 62/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 63/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 64/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 65/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 66/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 67/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 68/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 69/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 70/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 71/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 72/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 73/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 74/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 75/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 76/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 77/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 78/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 79/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 80/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 81/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 82/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 83/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 84/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 85/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 86/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 87/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 88/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 89/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 90/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 91/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 92/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 93/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 94/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 95/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 96/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 97/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 98/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 99/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000 Epoch 100/100 32/32 [==============================] - 0s 3ms/step - loss: 7.7125 - accuracy: 0.5000
Hmm... still not learning...
What we if increased the number of neurons and layers?
Say, 2 hidden layers, with ReLU, pronounced "rel-u", (short for rectified linear unit), activation on the first one, and 4 neurons each?
To see this network in action, check out the TensorFlow Playground demo.
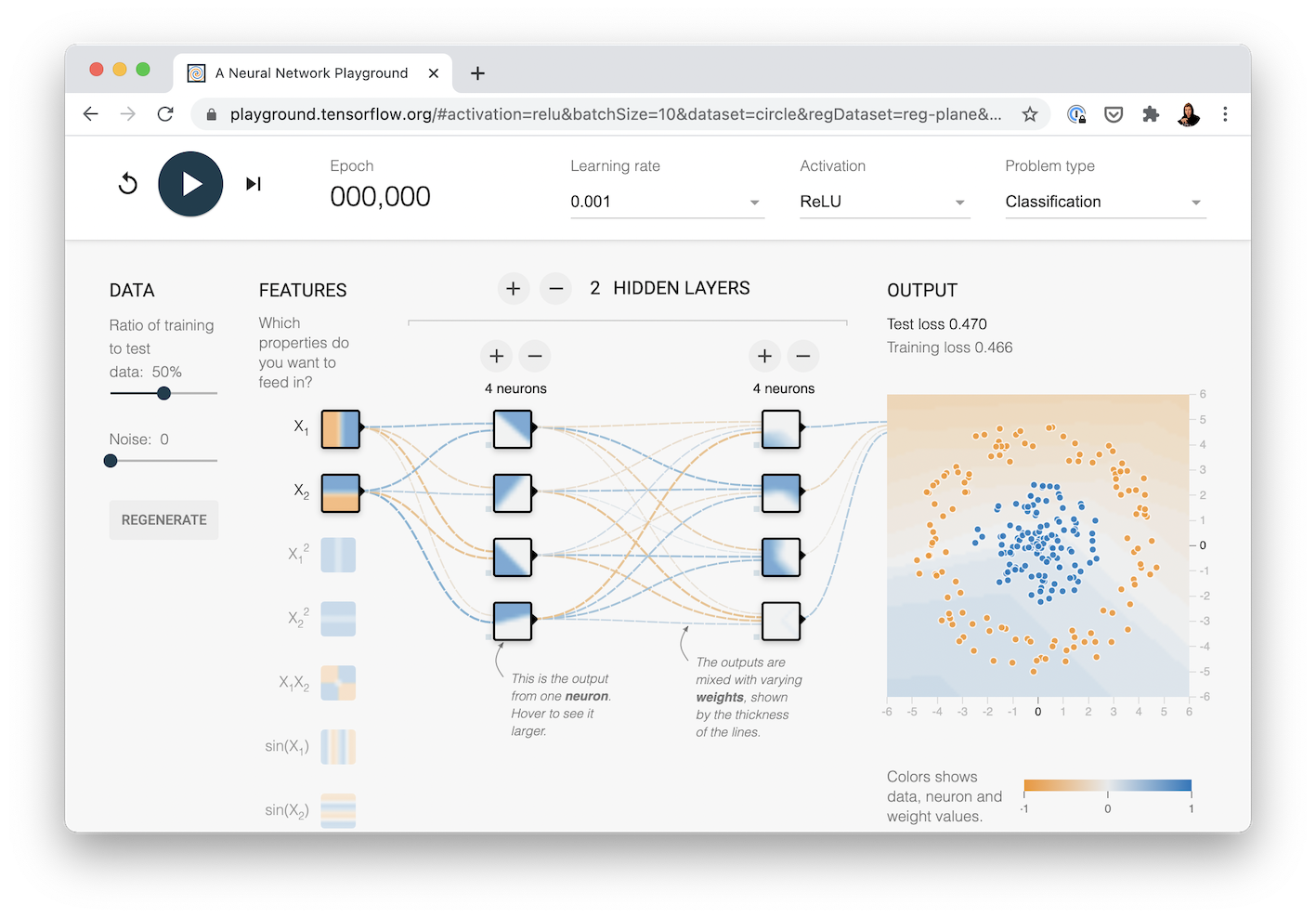 The neural network we're going to recreate with TensorFlow code. See it live at TensorFlow Playground.
The neural network we're going to recreate with TensorFlow code. See it live at TensorFlow Playground.
Let's try.
Note: in the course, Daniel used lr instead of learning_rate. But for the update, we had changed to learning_rate instead of lr.
# Set random seed
tf.random.set_seed(42)
# Create a model
model_6 = tf.keras.Sequential([
tf.keras.layers.Dense(4, activation=tf.keras.activations.relu), # hidden layer 1, 4 neurons, ReLU activation
tf.keras.layers.Dense(4, activation=tf.keras.activations.relu), # hidden layer 2, 4 neurons, ReLU activation
tf.keras.layers.Dense(1) # ouput layer
])
# Compile the model
model_6.compile(loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), # Adam's default learning rate is 0.001
metrics=['accuracy'])
# Fit the model
history = model_6.fit(X, y, epochs=100)
Epoch 1/100 32/32 [==============================] - 2s 3ms/step - loss: 4.3069 - accuracy: 0.5000 Epoch 2/100 32/32 [==============================] - 0s 3ms/step - loss: 4.0916 - accuracy: 0.5000 Epoch 3/100 32/32 [==============================] - 0s 3ms/step - loss: 3.9820 - accuracy: 0.4520 Epoch 4/100 32/32 [==============================] - 0s 3ms/step - loss: 3.8302 - accuracy: 0.4150 Epoch 5/100 32/32 [==============================] - 0s 3ms/step - loss: 3.7048 - accuracy: 0.4500 Epoch 6/100 32/32 [==============================] - 0s 3ms/step - loss: 3.5944 - accuracy: 0.4650 Epoch 7/100 32/32 [==============================] - 0s 3ms/step - loss: 3.1921 - accuracy: 0.4650 Epoch 8/100 32/32 [==============================] - 0s 3ms/step - loss: 2.6196 - accuracy: 0.4680 Epoch 9/100 32/32 [==============================] - 0s 3ms/step - loss: 1.3332 - accuracy: 0.4740 Epoch 10/100 32/32 [==============================] - 0s 3ms/step - loss: 0.9951 - accuracy: 0.4750 Epoch 11/100 32/32 [==============================] - 0s 3ms/step - loss: 0.9489 - accuracy: 0.4750 Epoch 12/100 32/32 [==============================] - 0s 3ms/step - loss: 0.9082 - accuracy: 0.4730 Epoch 13/100 32/32 [==============================] - 0s 3ms/step - loss: 0.8345 - accuracy: 0.4720 Epoch 14/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7435 - accuracy: 0.4690 Epoch 15/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7288 - accuracy: 0.4550 Epoch 16/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7245 - accuracy: 0.4620 Epoch 17/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7213 - accuracy: 0.4630 Epoch 18/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7186 - accuracy: 0.4670 Epoch 19/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7166 - accuracy: 0.4600 Epoch 20/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7143 - accuracy: 0.4560 Epoch 21/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7127 - accuracy: 0.4600 Epoch 22/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7107 - accuracy: 0.4580 Epoch 23/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7090 - accuracy: 0.4590 Epoch 24/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7075 - accuracy: 0.4640 Epoch 25/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7061 - accuracy: 0.4690 Epoch 26/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7046 - accuracy: 0.4640 Epoch 27/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7033 - accuracy: 0.4720 Epoch 28/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7012 - accuracy: 0.4650 Epoch 29/100 32/32 [==============================] - 0s 3ms/step - loss: 0.7002 - accuracy: 0.4660 Epoch 30/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6987 - accuracy: 0.4650 Epoch 31/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6973 - accuracy: 0.4660 Epoch 32/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6961 - accuracy: 0.4710 Epoch 33/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6944 - accuracy: 0.4760 Epoch 34/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6935 - accuracy: 0.4690 Epoch 35/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6922 - accuracy: 0.4850 Epoch 36/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6907 - accuracy: 0.4740 Epoch 37/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6895 - accuracy: 0.4940 Epoch 38/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6887 - accuracy: 0.4770 Epoch 39/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6875 - accuracy: 0.4680 Epoch 40/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6867 - accuracy: 0.4800 Epoch 41/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6862 - accuracy: 0.4850 Epoch 42/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6847 - accuracy: 0.4640 Epoch 43/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6837 - accuracy: 0.4730 Epoch 44/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6841 - accuracy: 0.4590 Epoch 45/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6820 - accuracy: 0.4520 Epoch 46/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6812 - accuracy: 0.4500 Epoch 47/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6813 - accuracy: 0.4730 Epoch 48/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6798 - accuracy: 0.4570 Epoch 49/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6791 - accuracy: 0.5190 Epoch 50/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6784 - accuracy: 0.5360 Epoch 51/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6779 - accuracy: 0.5270 Epoch 52/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6773 - accuracy: 0.5030 Epoch 53/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6766 - accuracy: 0.5350 Epoch 54/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6757 - accuracy: 0.5400 Epoch 55/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6756 - accuracy: 0.5410 Epoch 56/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6749 - accuracy: 0.5430 Epoch 57/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6744 - accuracy: 0.5420 Epoch 58/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6741 - accuracy: 0.5430 Epoch 59/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6737 - accuracy: 0.5420 Epoch 60/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6729 - accuracy: 0.5400 Epoch 61/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6727 - accuracy: 0.5410 Epoch 62/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6722 - accuracy: 0.5420 Epoch 63/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6715 - accuracy: 0.5390 Epoch 64/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6712 - accuracy: 0.5410 Epoch 65/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6709 - accuracy: 0.5400 Epoch 66/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6704 - accuracy: 0.5390 Epoch 67/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6701 - accuracy: 0.5400 Epoch 68/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6698 - accuracy: 0.5400 Epoch 69/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6691 - accuracy: 0.5420 Epoch 70/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6691 - accuracy: 0.5420 Epoch 71/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6684 - accuracy: 0.5410 Epoch 72/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6682 - accuracy: 0.5440 Epoch 73/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6680 - accuracy: 0.5480 Epoch 74/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6673 - accuracy: 0.5400 Epoch 75/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6675 - accuracy: 0.5500 Epoch 76/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6671 - accuracy: 0.5420 Epoch 77/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6666 - accuracy: 0.5530 Epoch 78/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6661 - accuracy: 0.5440 Epoch 79/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6657 - accuracy: 0.5490 Epoch 80/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6648 - accuracy: 0.5570 Epoch 81/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6647 - accuracy: 0.5580 Epoch 82/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6643 - accuracy: 0.5510 Epoch 83/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6637 - accuracy: 0.5460 Epoch 84/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6628 - accuracy: 0.5590 Epoch 85/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6625 - accuracy: 0.5540 Epoch 86/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6624 - accuracy: 0.5600 Epoch 87/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6615 - accuracy: 0.5560 Epoch 88/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6606 - accuracy: 0.5590 Epoch 89/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6605 - accuracy: 0.5650 Epoch 90/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6604 - accuracy: 0.5480 Epoch 91/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6588 - accuracy: 0.5580 Epoch 92/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6587 - accuracy: 0.5580 Epoch 93/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6586 - accuracy: 0.5490 Epoch 94/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6574 - accuracy: 0.5610 Epoch 95/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6567 - accuracy: 0.5560 Epoch 96/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6559 - accuracy: 0.5560 Epoch 97/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6551 - accuracy: 0.5590 Epoch 98/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6535 - accuracy: 0.5580 Epoch 99/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6538 - accuracy: 0.5760 Epoch 100/100 32/32 [==============================] - 0s 3ms/step - loss: 0.6523 - accuracy: 0.5640
# Evaluate the model
model_6.evaluate(X, y)
32/32 [==============================] - 0s 2ms/step - loss: 0.6508 - accuracy: 0.5640
[0.6507635116577148, 0.5640000104904175]
We're still hitting 50% accuracy, our model is still practically as good as guessing.
How do the predictions look?
# Check out the predictions using 2 hidden layers
plot_decision_boundary(model_6, X, y)
313/313 [==============================] - 0s 1ms/step doing binary classifcation...

What gives?
It seems like our model is the same as the one in the TensorFlow Playground but model it's still drawing straight lines...
Ideally, the yellow lines go on the inside of the red circle and the blue circle.
Okay, okay, let's model this circle once and for all.
One more model (I promise... actually, I'm going to have to break that promise... we'll be building plenty more models).
This time we'll change the activation function on our output layer too. Remember the architecture of a classification model? For binary classification, the output layer activation is usually the Sigmoid activation function.
# Set random seed
tf.random.set_seed(42)
# Create a model
model_7 = tf.keras.Sequential([
tf.keras.layers.Dense(4, activation=tf.keras.activations.relu), # hidden layer 1, ReLU activation
tf.keras.layers.Dense(4, activation=tf.keras.activations.relu), # hidden layer 2, ReLU activation
tf.keras.layers.Dense(1, activation=tf.keras.activations.sigmoid) # ouput layer, sigmoid activation
])
# Compile the model
model_7.compile(loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(),
metrics=['accuracy'])
# Fit the model
history = model_7.fit(X, y, epochs=100, verbose=0)
# Evaluate our model
model_7.evaluate(X, y)
32/32 [==============================] - 0s 2ms/step - loss: 0.2082 - accuracy: 0.9950
[0.20816797018051147, 0.9950000047683716]
Woah! It looks like our model is getting some incredible results, let's check them out.
# View the predictions of the model with relu and sigmoid activations
plot_decision_boundary(model_7, X, y)
313/313 [==============================] - 0s 1ms/step doing binary classifcation...

Nice! It looks like our model is almost perfectly (apart from a few examples) separating the two circles.
🤔 Question: What's wrong with the predictions we've made? Are we really evaluating our model correctly here? Hint: what data did the model learn on and what did we predict on?
Before we answer that, it's important to recognize what we've just covered.
🔑 Note: The combination of linear (straight lines) and non-linear (non-straight lines) functions is one of the key fundamentals of neural networks.
Think of it like this:
If I gave you an unlimited amount of straight lines and non-straight lines, what kind of patterns could you draw?
That's essentially what neural networks do to find patterns in data.
Now you might be thinking, "but I haven't seen a linear function or a non-linear function before..."
Oh but you have.
We've been using them the whole time.
They're what power the layers in the models we just built.
To get some intuition about the activation functions we've just used, let's create them and then try them on some toy data.
# Create a toy tensor (similar to the data we pass into our model)
A = tf.cast(tf.range(-10, 10), tf.float32)
A
<tf.Tensor: shape=(20,), dtype=float32, numpy=
array([-10., -9., -8., -7., -6., -5., -4., -3., -2., -1., 0.,
1., 2., 3., 4., 5., 6., 7., 8., 9.],
dtype=float32)>
How does this look?
# Visualize our toy tensor
plt.plot(A);

A straight (linear) line!
Nice, now let's recreate the sigmoid function and see what it does to our data. You can also find a pre-built sigmoid function at tf.keras.activations.sigmoid.
# Sigmoid - https://www.tensorflow.org/api_docs/python/tf/keras/activations/sigmoid
def sigmoid(x):
return 1 / (1 + tf.exp(-x))
# Use the sigmoid function on our tensor
sigmoid(A)
<tf.Tensor: shape=(20,), dtype=float32, numpy=
array([4.5397868e-05, 1.2339458e-04, 3.3535014e-04, 9.1105117e-04,
2.4726230e-03, 6.6928510e-03, 1.7986210e-02, 4.7425874e-02,
1.1920292e-01, 2.6894143e-01, 5.0000000e-01, 7.3105854e-01,
8.8079703e-01, 9.5257413e-01, 9.8201376e-01, 9.9330717e-01,
9.9752742e-01, 9.9908900e-01, 9.9966466e-01, 9.9987662e-01],
dtype=float32)>
And how does it look?
# Plot sigmoid modified tensor
plt.plot(sigmoid(A));

A non-straight (non-linear) line!
Okay, how about the ReLU function (ReLU turns all negatives to 0 and positive numbers stay the same)?
# ReLU - https://www.tensorflow.org/api_docs/python/tf/keras/activations/relu
def relu(x):
return tf.maximum(0, x)
# Pass toy tensor through ReLU function
relu(A)
<tf.Tensor: shape=(20,), dtype=float32, numpy=
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 2., 3., 4., 5., 6.,
7., 8., 9.], dtype=float32)>
How does the ReLU-modified tensor look?
# Plot ReLU-modified tensor
plt.plot(relu(A));

Another non-straight line!
Well, how about TensorFlow's linear activation function?
# Linear - https://www.tensorflow.org/api_docs/python/tf/keras/activations/linear (returns input non-modified...)
tf.keras.activations.linear(A)
<tf.Tensor: shape=(20,), dtype=float32, numpy=
array([-10., -9., -8., -7., -6., -5., -4., -3., -2., -1., 0.,
1., 2., 3., 4., 5., 6., 7., 8., 9.],
dtype=float32)>
Hmm, it looks like our inputs are unmodified...
# Does the linear activation change anything?
A == tf.keras.activations.linear(A)
<tf.Tensor: shape=(20,), dtype=bool, numpy=
array([ True, True, True, True, True, True, True, True, True,
True, True, True, True, True, True, True, True, True,
True, True])>
Okay, so it makes sense now the model doesn't really learn anything when using only linear activation functions, because the linear activation function doesn't change our input data in anyway.
Where as, with our non-linear functions, our data gets manipulated. A neural network uses these kind of transformations at a large scale to figure draw patterns between its inputs and outputs.
Now rather than dive into the guts of neural networks, we're going to keep coding applying what we've learned to different problems but if you want a more in-depth look at what's going on behind the scenes, check out the Extra Curriculum section below.
📖 Resource: For more on activation functions, check out the machine learning cheatsheet page on them.
Evaluating and improving our classification model¶
If you answered the question above, you might've picked up what we've been doing wrong.
We've been evaluating our model on the same data it was trained on.
A better approach would be to split our data into training, validation (optional) and test sets.
Once we've done that, we'll train our model on the training set (let it find patterns in the data) and then see how well it learned the patterns by using it to predict values on the test set.
Let's do it.
# How many examples are in the whole dataset?
len(X)
1000
# Split data into train and test sets
X_train, y_train = X[:800], y[:800] # 80% of the data for the training set
X_test, y_test = X[800:], y[800:] # 20% of the data for the test set
# Check the shapes of the data
X_train.shape, X_test.shape # 800 examples in the training set, 200 examples in the test set
((800, 2), (200, 2))
Great, now we've got training and test sets, let's model the training data and evaluate what our model has learned on the test set.
# Set random seed
tf.random.set_seed(42)
# Create the model (same as model_7)
model_8 = tf.keras.Sequential([
tf.keras.layers.Dense(4, activation="relu"), # hidden layer 1, using "relu" for activation (same as tf.keras.activations.relu)
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid") # output layer, using 'sigmoid' for the output
])
# Compile the model
model_8.compile(loss=tf.keras.losses.binary_crossentropy,
optimizer=tf.keras.optimizers.Adam(learning_rate=0.01), # increase learning rate from 0.001 to 0.01 for faster learning
metrics=['accuracy'])
# Fit the model
history = model_8.fit(X_train, y_train, epochs=25)
Epoch 1/25 25/25 [==============================] - 1s 3ms/step - loss: 0.6902 - accuracy: 0.5075 Epoch 2/25 25/25 [==============================] - 0s 3ms/step - loss: 0.6878 - accuracy: 0.5325 Epoch 3/25 25/25 [==============================] - 0s 3ms/step - loss: 0.6862 - accuracy: 0.5200 Epoch 4/25 25/25 [==============================] - 0s 3ms/step - loss: 0.6830 - accuracy: 0.5462 Epoch 5/25 25/25 [==============================] - 0s 3ms/step - loss: 0.6770 - accuracy: 0.5700 Epoch 6/25 25/25 [==============================] - 0s 3ms/step - loss: 0.6676 - accuracy: 0.5450 Epoch 7/25 25/25 [==============================] - 0s 3ms/step - loss: 0.6511 - accuracy: 0.6650 Epoch 8/25 25/25 [==============================] - 0s 3ms/step - loss: 0.6341 - accuracy: 0.7075 Epoch 9/25 25/25 [==============================] - 0s 3ms/step - loss: 0.6085 - accuracy: 0.7588 Epoch 10/25 25/25 [==============================] - 0s 3ms/step - loss: 0.5821 - accuracy: 0.7538 Epoch 11/25 25/25 [==============================] - 0s 3ms/step - loss: 0.5565 - accuracy: 0.7763 Epoch 12/25 25/25 [==============================] - 0s 3ms/step - loss: 0.5284 - accuracy: 0.7962 Epoch 13/25 25/25 [==============================] - 0s 3ms/step - loss: 0.5035 - accuracy: 0.8037 Epoch 14/25 25/25 [==============================] - 0s 3ms/step - loss: 0.4585 - accuracy: 0.8450 Epoch 15/25 25/25 [==============================] - 0s 3ms/step - loss: 0.4156 - accuracy: 0.8838 Epoch 16/25 25/25 [==============================] - 0s 3ms/step - loss: 0.3831 - accuracy: 0.8975 Epoch 17/25 25/25 [==============================] - 0s 3ms/step - loss: 0.3542 - accuracy: 0.9125 Epoch 18/25 25/25 [==============================] - 0s 3ms/step - loss: 0.3288 - accuracy: 0.9312 Epoch 19/25 25/25 [==============================] - 0s 3ms/step - loss: 0.2976 - accuracy: 0.9588 Epoch 20/25 25/25 [==============================] - 0s 3ms/step - loss: 0.2850 - accuracy: 0.9450 Epoch 21/25 25/25 [==============================] - 0s 3ms/step - loss: 0.2571 - accuracy: 0.9563 Epoch 22/25 25/25 [==============================] - 0s 3ms/step - loss: 0.2353 - accuracy: 0.9613 Epoch 23/25 25/25 [==============================] - 0s 3ms/step - loss: 0.2209 - accuracy: 0.9725 Epoch 24/25 25/25 [==============================] - 0s 3ms/step - loss: 0.2108 - accuracy: 0.9588 Epoch 25/25 25/25 [==============================] - 0s 3ms/step - loss: 0.2010 - accuracy: 0.9700
# Evaluate our model on the test set
loss, accuracy = model_8.evaluate(X_test, y_test)
print(f"Model loss on the test set: {loss}")
print(f"Model accuracy on the test set: {100*accuracy:.2f}%")
7/7 [==============================] - 0s 3ms/step - loss: 0.2052 - accuracy: 0.9700 Model loss on the test set: 0.20516908168792725 Model accuracy on the test set: 97.00%
100% accuracy? Nice!
Now, when we started to create model_8 we said it was going to be the same as model_7 but you might've found that to be a little lie.
That's because we changed a few things:
- The
activationparameter - We used strings ("relu"&"sigmoid") instead of using library paths (tf.keras.activations.relu), in TensorFlow, they both offer the same functionality. - The
learning_rate(alsolr) parameter - We increased the learning rate parameter in the Adam optimizer to0.01instead of0.001(an increase of 10x).- You can think of the learning rate as how quickly a model learns. The higher the learning rate, the faster the model's capacity to learn, however, there's such a thing as a too high learning rate, where a model tries to learn too fast and doesn't learn anything. We'll see a trick to find the ideal learning rate soon.
- The number of epochs - We lowered the number of epochs (using the
epochsparameter) from 100 to 25 but our model still got an incredible result on both the training and test sets.- One of the reasons our model performed well in even less epochs (remember a single epoch is the model trying to learn patterns in the data by looking at it once, so 25 epochs means the model gets 25 chances) than before is because we increased the learning rate.
We know our model is performing well based on the evaluation metrics but let's see how it performs visually.
# Plot the decision boundaries for the training and test sets
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_8, X=X_train, y=y_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_8, X=X_test, y=y_test)
plt.show()
313/313 [==============================] - 0s 1ms/step doing binary classifcation... 313/313 [==============================] - 0s 1ms/step doing binary classifcation...

Check that out! How cool. With a few tweaks, our model is now predicting the blue and red circles almost perfectly.
Plot the loss curves¶
Looking at the plots above, we can see the outputs of our model are very good.
But how did our model go whilst it was learning?
As in, how did the performance change everytime the model had a chance to look at the data (once every epoch)?
To figure this out, we can check the loss curves (also referred to as the learning curves).
You might've seen we've been using the variable history when calling the fit() function on a model (fit() returns a History object).
This is where we'll get the information for how our model is performing as it learns.
Let's see how we might use it.
# You can access the information in the history variable using the .history attribute
pd.DataFrame(history.history)
| loss | accuracy | |
|---|---|---|
| 0 | 0.690183 | 0.50750 |
| 1 | 0.687798 | 0.53250 |
| 2 | 0.686171 | 0.52000 |
| 3 | 0.683011 | 0.54625 |
| 4 | 0.677036 | 0.57000 |
| 5 | 0.667617 | 0.54500 |
| 6 | 0.651129 | 0.66500 |
| 7 | 0.634132 | 0.70750 |
| 8 | 0.608484 | 0.75875 |
| 9 | 0.582073 | 0.75375 |
| 10 | 0.556544 | 0.77625 |
| 11 | 0.528435 | 0.79625 |
| 12 | 0.503492 | 0.80375 |
| 13 | 0.458543 | 0.84500 |
| 14 | 0.415571 | 0.88375 |
| 15 | 0.383102 | 0.89750 |
| 16 | 0.354211 | 0.91250 |
| 17 | 0.328809 | 0.93125 |
| 18 | 0.297566 | 0.95875 |
| 19 | 0.285039 | 0.94500 |
| 20 | 0.257121 | 0.95625 |
| 21 | 0.235265 | 0.96125 |
| 22 | 0.220926 | 0.97250 |
| 23 | 0.210754 | 0.95875 |
| 24 | 0.201047 | 0.97000 |
Inspecting the outputs, we can see the loss values going down and the accuracy going up.
How's it look (visualize, visualize, visualize)?
# Plot the loss curves
pd.DataFrame(history.history).plot()
plt.title("Model_8 training curves")
Text(0.5, 1.0, 'Model_8 training curves')

Beautiful. This is the ideal plot we'd be looking for when dealing with a classification problem, loss going down, accuracy going up.
🔑 Note: For many problems, the loss function going down means the model is improving (the predictions it's making are getting closer to the ground truth labels).
Finding the best learning rate¶
Aside from the architecture itself (the layers, number of neurons, activations, etc), the most important hyperparameter you can tune for your neural network models is the learning rate.
In model_8 you saw we lowered the Adam optimizer's learning rate from the default of 0.001 (default) to 0.01.
And you might be wondering why we did this.
Put it this way, it was a lucky guess.
I just decided to try a lower learning rate and see how the model went.
Now you might be thinking, "Seriously? You can do that?"
And the answer is yes. You can change any of the hyperparamaters of your neural networks.
With practice, you'll start to see what kind of hyperparameters work and what don't.
That's an important thing to understand about machine learning and deep learning in general. It's very experimental. You build a model and evaluate it, build a model and evaluate it.
That being said, I want to introduce you a trick which will help you find the optimal learning rate (at least to begin training with) for your models going forward.
To do so, we're going to use the following:
- A learning rate callback.
- You can think of a callback as an extra piece of functionality you can add to your model while its training.
- Another model (we could use the same ones as above, we we're practicing building models here).
- A modified loss curves plot.
We'll go through each with code, then explain what's going on.
🔑 Note: The default hyperparameters of many neural network building blocks in TensorFlow are setup in a way which usually work right out of the box (e.g. the Adam optimizer's default settings can usually get good results on many datasets). So it's a good idea to try the defaults first, then adjust as needed.
# Set random seed
tf.random.set_seed(42)
# Create a model (same as model_8)
model_9 = tf.keras.Sequential([
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
# Compile the model
model_9.compile(loss="binary_crossentropy", # we can use strings here too
optimizer="Adam", # same as tf.keras.optimizers.Adam() with default settings
metrics=["accuracy"])
# Create a learning rate scheduler callback
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(lambda epoch: 1e-4 * 10**(epoch/20)) # traverse a set of learning rate values starting from 1e-4, increasing by 10**(epoch/20) every epoch
# Fit the model (passing the lr_scheduler callback)
history = model_9.fit(X_train,
y_train,
epochs=100,
callbacks=[lr_scheduler])
Epoch 1/100 25/25 [==============================] - 1s 3ms/step - loss: 0.6918 - accuracy: 0.5088 - lr: 1.0000e-04 Epoch 2/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6918 - accuracy: 0.5038 - lr: 1.1220e-04 Epoch 3/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6917 - accuracy: 0.5038 - lr: 1.2589e-04 Epoch 4/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6917 - accuracy: 0.5025 - lr: 1.4125e-04 Epoch 5/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6917 - accuracy: 0.5063 - lr: 1.5849e-04 Epoch 6/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6916 - accuracy: 0.5050 - lr: 1.7783e-04 Epoch 7/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6915 - accuracy: 0.5088 - lr: 1.9953e-04 Epoch 8/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6915 - accuracy: 0.5075 - lr: 2.2387e-04 Epoch 9/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6914 - accuracy: 0.5088 - lr: 2.5119e-04 Epoch 10/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6913 - accuracy: 0.5088 - lr: 2.8184e-04 Epoch 11/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6912 - accuracy: 0.5075 - lr: 3.1623e-04 Epoch 12/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6912 - accuracy: 0.5100 - lr: 3.5481e-04 Epoch 13/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6910 - accuracy: 0.5113 - lr: 3.9811e-04 Epoch 14/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6909 - accuracy: 0.5138 - lr: 4.4668e-04 Epoch 15/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6907 - accuracy: 0.5150 - lr: 5.0119e-04 Epoch 16/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6905 - accuracy: 0.5188 - lr: 5.6234e-04 Epoch 17/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6903 - accuracy: 0.5225 - lr: 6.3096e-04 Epoch 18/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6901 - accuracy: 0.5238 - lr: 7.0795e-04 Epoch 19/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6899 - accuracy: 0.5250 - lr: 7.9433e-04 Epoch 20/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6895 - accuracy: 0.5288 - lr: 8.9125e-04 Epoch 21/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6891 - accuracy: 0.5300 - lr: 0.0010 Epoch 22/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6885 - accuracy: 0.5375 - lr: 0.0011 Epoch 23/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6880 - accuracy: 0.5350 - lr: 0.0013 Epoch 24/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6868 - accuracy: 0.5412 - lr: 0.0014 Epoch 25/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6856 - accuracy: 0.5350 - lr: 0.0016 Epoch 26/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6844 - accuracy: 0.5387 - lr: 0.0018 Epoch 27/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6830 - accuracy: 0.5425 - lr: 0.0020 Epoch 28/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6811 - accuracy: 0.5437 - lr: 0.0022 Epoch 29/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6794 - accuracy: 0.5475 - lr: 0.0025 Epoch 30/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6773 - accuracy: 0.5587 - lr: 0.0028 Epoch 31/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6743 - accuracy: 0.5600 - lr: 0.0032 Epoch 32/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6712 - accuracy: 0.5788 - lr: 0.0035 Epoch 33/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6668 - accuracy: 0.5938 - lr: 0.0040 Epoch 34/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6611 - accuracy: 0.6300 - lr: 0.0045 Epoch 35/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6541 - accuracy: 0.6513 - lr: 0.0050 Epoch 36/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6456 - accuracy: 0.6400 - lr: 0.0056 Epoch 37/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6316 - accuracy: 0.6862 - lr: 0.0063 Epoch 38/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6141 - accuracy: 0.6850 - lr: 0.0071 Epoch 39/100 25/25 [==============================] - 0s 3ms/step - loss: 0.5986 - accuracy: 0.7287 - lr: 0.0079 Epoch 40/100 25/25 [==============================] - 0s 3ms/step - loss: 0.5662 - accuracy: 0.7588 - lr: 0.0089 Epoch 41/100 25/25 [==============================] - 0s 3ms/step - loss: 0.5288 - accuracy: 0.7663 - lr: 0.0100 Epoch 42/100 25/25 [==============================] - 0s 3ms/step - loss: 0.5150 - accuracy: 0.7588 - lr: 0.0112 Epoch 43/100 25/25 [==============================] - 0s 3ms/step - loss: 0.5029 - accuracy: 0.7837 - lr: 0.0126 Epoch 44/100 25/25 [==============================] - 0s 3ms/step - loss: 0.4472 - accuracy: 0.8213 - lr: 0.0141 Epoch 45/100 25/25 [==============================] - 0s 3ms/step - loss: 0.3744 - accuracy: 0.8662 - lr: 0.0158 Epoch 46/100 25/25 [==============================] - 0s 3ms/step - loss: 0.2755 - accuracy: 0.9312 - lr: 0.0178 Epoch 47/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1886 - accuracy: 0.9600 - lr: 0.0200 Epoch 48/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1305 - accuracy: 0.9812 - lr: 0.0224 Epoch 49/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1161 - accuracy: 0.9762 - lr: 0.0251 Epoch 50/100 25/25 [==============================] - 0s 3ms/step - loss: 0.0870 - accuracy: 0.9900 - lr: 0.0282 Epoch 51/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1532 - accuracy: 0.9325 - lr: 0.0316 Epoch 52/100 25/25 [==============================] - 0s 3ms/step - loss: 0.0809 - accuracy: 0.9775 - lr: 0.0355 Epoch 53/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1048 - accuracy: 0.9600 - lr: 0.0398 Epoch 54/100 25/25 [==============================] - 0s 3ms/step - loss: 0.0923 - accuracy: 0.9600 - lr: 0.0447 Epoch 55/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1136 - accuracy: 0.9538 - lr: 0.0501 Epoch 56/100 25/25 [==============================] - 0s 3ms/step - loss: 0.2233 - accuracy: 0.9200 - lr: 0.0562 Epoch 57/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1119 - accuracy: 0.9563 - lr: 0.0631 Epoch 58/100 25/25 [==============================] - 0s 3ms/step - loss: 0.2204 - accuracy: 0.9125 - lr: 0.0708 Epoch 59/100 25/25 [==============================] - 0s 3ms/step - loss: 0.0781 - accuracy: 0.9725 - lr: 0.0794 Epoch 60/100 25/25 [==============================] - 0s 3ms/step - loss: 0.0548 - accuracy: 0.9787 - lr: 0.0891 Epoch 61/100 25/25 [==============================] - 0s 3ms/step - loss: 0.0916 - accuracy: 0.9688 - lr: 0.1000 Epoch 62/100 25/25 [==============================] - 0s 3ms/step - loss: 0.4185 - accuracy: 0.8838 - lr: 0.1122 Epoch 63/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1851 - accuracy: 0.9350 - lr: 0.1259 Epoch 64/100 25/25 [==============================] - 0s 3ms/step - loss: 0.0893 - accuracy: 0.9688 - lr: 0.1413 Epoch 65/100 25/25 [==============================] - 0s 3ms/step - loss: 0.0730 - accuracy: 0.9775 - lr: 0.1585 Epoch 66/100 25/25 [==============================] - 0s 3ms/step - loss: 0.3190 - accuracy: 0.9050 - lr: 0.1778 Epoch 67/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6285 - accuracy: 0.6950 - lr: 0.1995 Epoch 68/100 25/25 [==============================] - 0s 3ms/step - loss: 0.4084 - accuracy: 0.7812 - lr: 0.2239 Epoch 69/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1803 - accuracy: 0.9350 - lr: 0.2512 Epoch 70/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1364 - accuracy: 0.9500 - lr: 0.2818 Epoch 71/100 25/25 [==============================] - 0s 3ms/step - loss: 0.3171 - accuracy: 0.9013 - lr: 0.3162 Epoch 72/100 25/25 [==============================] - 0s 3ms/step - loss: 0.2477 - accuracy: 0.9150 - lr: 0.3548 Epoch 73/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1354 - accuracy: 0.9525 - lr: 0.3981 Epoch 74/100 25/25 [==============================] - 0s 3ms/step - loss: 0.3741 - accuracy: 0.8712 - lr: 0.4467 Epoch 75/100 25/25 [==============================] - 0s 3ms/step - loss: 0.3701 - accuracy: 0.8550 - lr: 0.5012 Epoch 76/100 25/25 [==============================] - 0s 3ms/step - loss: 0.2392 - accuracy: 0.9125 - lr: 0.5623 Epoch 77/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1684 - accuracy: 0.9312 - lr: 0.6310 Epoch 78/100 25/25 [==============================] - 0s 3ms/step - loss: 0.1817 - accuracy: 0.9312 - lr: 0.7079 Epoch 79/100 25/25 [==============================] - 0s 3ms/step - loss: 0.4512 - accuracy: 0.8250 - lr: 0.7943 Epoch 80/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6677 - accuracy: 0.5938 - lr: 0.8913 Epoch 81/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6764 - accuracy: 0.5400 - lr: 1.0000 Epoch 82/100 25/25 [==============================] - 0s 3ms/step - loss: 0.6678 - accuracy: 0.5775 - lr: 1.1220 Epoch 83/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7416 - accuracy: 0.4900 - lr: 1.2589 Epoch 84/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7138 - accuracy: 0.5063 - lr: 1.4125 Epoch 85/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7237 - accuracy: 0.5038 - lr: 1.5849 Epoch 86/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7751 - accuracy: 0.5063 - lr: 1.7783 Epoch 87/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7665 - accuracy: 0.5063 - lr: 1.9953 Epoch 88/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7566 - accuracy: 0.5163 - lr: 2.2387 Epoch 89/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7552 - accuracy: 0.4938 - lr: 2.5119 Epoch 90/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7816 - accuracy: 0.5238 - lr: 2.8184 Epoch 91/100 25/25 [==============================] - 0s 3ms/step - loss: 0.8113 - accuracy: 0.5213 - lr: 3.1623 Epoch 92/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7351 - accuracy: 0.4888 - lr: 3.5481 Epoch 93/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7429 - accuracy: 0.5063 - lr: 3.9811 Epoch 94/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7601 - accuracy: 0.5063 - lr: 4.4668 Epoch 95/100 25/25 [==============================] - 0s 3ms/step - loss: 0.8247 - accuracy: 0.4863 - lr: 5.0119 Epoch 96/100 25/25 [==============================] - 0s 3ms/step - loss: 0.7877 - accuracy: 0.4737 - lr: 5.6234 Epoch 97/100 25/25 [==============================] - 0s 3ms/step - loss: 0.8081 - accuracy: 0.5013 - lr: 6.3096 Epoch 98/100 25/25 [==============================] - 0s 3ms/step - loss: 0.9653 - accuracy: 0.4963 - lr: 7.0795 Epoch 99/100 25/25 [==============================] - 0s 3ms/step - loss: 0.9762 - accuracy: 0.4913 - lr: 7.9433 Epoch 100/100 25/25 [==============================] - 0s 3ms/step - loss: 0.8582 - accuracy: 0.4613 - lr: 8.9125
Now our model has finished training, let's have a look at the training history.
# Checkout the history
pd.DataFrame(history.history).plot(figsize=(10,7), xlabel="epochs");

As you you see the learning rate exponentially increases as the number of epochs increases.
And you can see the model's accuracy goes up (and loss goes down) at a specific point when the learning rate slowly increases.
To figure out where this infliction point is, we can plot the loss versus the log-scale learning rate.
# Plot the learning rate versus the loss
lrs = 1e-4 * (10 ** (np.arange(100)/20))
plt.figure(figsize=(10, 7))
plt.semilogx(lrs, history.history["loss"]) # we want the x-axis (learning rate) to be log scale
plt.xlabel("Learning Rate")
plt.ylabel("Loss")
plt.title("Learning rate vs. loss");

To figure out the ideal value of the learning rate (at least the ideal value to begin training our model), the rule of thumb is to take the learning rate value where the loss is still decreasing but not quite flattened out (usually about 10x smaller than the bottom of the curve).
In this case, our ideal learning rate ends up between 0.01 ($10^{-2}$) and 0.02.
The ideal learning rate at the start of model training is somewhere just before the loss curve bottoms out (a value where the loss is still decreasing).
# Example of other typical learning rate values
10**0, 10**-1, 10**-2, 10**-3, 1e-4
(1, 0.1, 0.01, 0.001, 0.0001)
Now we've estimated the ideal learning rate (we'll use 0.02) for our model, let's refit it.
# Set the random seed
tf.random.set_seed(42)
# Create the model
model_10 = tf.keras.Sequential([
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(1, activation="sigmoid")
])
# Compile the model with the ideal learning rate
model_10.compile(loss="binary_crossentropy",
optimizer=tf.keras.optimizers.Adam(learning_rate=0.02), # to adjust the learning rate, you need to use tf.keras.optimizers.Adam (not "adam")
metrics=["accuracy"])
# Fit the model for 20 epochs (5 less than before)
history = model_10.fit(X_train, y_train, epochs=20)
Epoch 1/20 25/25 [==============================] - 2s 3ms/step - loss: 0.6844 - accuracy: 0.5650 Epoch 2/20 25/25 [==============================] - 0s 3ms/step - loss: 0.6692 - accuracy: 0.6612 Epoch 3/20 25/25 [==============================] - 0s 3ms/step - loss: 0.6408 - accuracy: 0.7250 Epoch 4/20 25/25 [==============================] - 0s 3ms/step - loss: 0.5839 - accuracy: 0.7812 Epoch 5/20 25/25 [==============================] - 0s 3ms/step - loss: 0.5135 - accuracy: 0.8250 Epoch 6/20 25/25 [==============================] - 0s 3ms/step - loss: 0.4106 - accuracy: 0.9187 Epoch 7/20 25/25 [==============================] - 0s 3ms/step - loss: 0.3194 - accuracy: 0.9513 Epoch 8/20 25/25 [==============================] - 0s 3ms/step - loss: 0.2379 - accuracy: 0.9762 Epoch 9/20 25/25 [==============================] - 0s 3ms/step - loss: 0.1835 - accuracy: 0.9850 Epoch 10/20 25/25 [==============================] - 0s 3ms/step - loss: 0.1439 - accuracy: 0.9925 Epoch 11/20 25/25 [==============================] - 0s 3ms/step - loss: 0.1122 - accuracy: 0.9950 Epoch 12/20 25/25 [==============================] - 0s 3ms/step - loss: 0.0928 - accuracy: 0.9937 Epoch 13/20 25/25 [==============================] - 0s 3ms/step - loss: 0.0849 - accuracy: 0.9937 Epoch 14/20 25/25 [==============================] - 0s 3ms/step - loss: 0.0818 - accuracy: 0.9875 Epoch 15/20 25/25 [==============================] - 0s 3ms/step - loss: 0.0714 - accuracy: 0.9925 Epoch 16/20 25/25 [==============================] - 0s 3ms/step - loss: 0.0624 - accuracy: 0.9950 Epoch 17/20 25/25 [==============================] - 0s 3ms/step - loss: 0.0535 - accuracy: 0.9912 Epoch 18/20 25/25 [==============================] - 0s 3ms/step - loss: 0.0501 - accuracy: 0.9975 Epoch 19/20 25/25 [==============================] - 0s 3ms/step - loss: 0.0588 - accuracy: 0.9875 Epoch 20/20 25/25 [==============================] - 0s 3ms/step - loss: 0.0470 - accuracy: 0.9887
Nice! With a little higher learning rate (0.02 instead of 0.01) we reach a higher accuracy than model_8 in less epochs (20 instead of 25).
🛠 Practice: Now you've seen an example of what can happen when you change the learning rate, try changing the learning rate value in the TensorFlow Playground and see what happens. What happens if you increase it? What happens if you decrease it?
# Evaluate model on the test dataset
model_10.evaluate(X_test, y_test)
7/7 [==============================] - 0s 3ms/step - loss: 0.0425 - accuracy: 1.0000
[0.042508091777563095, 1.0]
Let's see how the predictions look.
# Plot the decision boundaries for the training and test sets
plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1)
plt.title("Train")
plot_decision_boundary(model_10, X=X_train, y=y_train)
plt.subplot(1, 2, 2)
plt.title("Test")
plot_decision_boundary(model_10, X=X_test, y=y_test)
plt.show()
313/313 [==============================] - 0s 1ms/step doing binary classifcation... 313/313 [==============================] - 0s 1ms/step doing binary classifcation...

And as we can see, almost perfect again.
These are the kind of experiments you'll be running often when building your own models.
Start with default settings and see how they perform on your data.
And if they don't perform as well as you'd like, improve them.
Let's look at a few more ways to evaluate our classification models.
More classification evaluation methods¶
Alongside the visualizations we've been making, there are a number of different evaluation metrics we can use to evaluate our classification models.
| Metric name/Evaluation method | Defintion | Code |
|---|---|---|
| Accuracy | Out of 100 predictions, how many does your model get correct? E.g. 95% accuracy means it gets 95/100 predictions correct. | sklearn.metrics.accuracy_score() or tf.keras.metrics.Accuracy() |
| Precision | Proportion of true positives over total number of samples. Higher precision leads to less false positives (model predicts 1 when it should've been 0). | sklearn.metrics.precision_score() or tf.keras.metrics.Precision() |
| Recall | Proportion of true positives over total number of true positives and false negatives (model predicts 0 when it should've been 1). Higher recall leads to less false negatives. | sklearn.metrics.recall_score() or tf.keras.metrics.Recall() |
| F1-score | Combines precision and recall into one metric. 1 is best, 0 is worst. | sklearn.metrics.f1_score() |
| Confusion matrix | Compares the predicted values with the true values in a tabular way, if 100% correct, all values in the matrix will be top left to bottom right (diagnol line). | Custom function or sklearn.metrics.plot_confusion_matrix() |
| Classification report | Collection of some of the main classification metrics such as precision, recall and f1-score. | sklearn.metrics.classification_report() |
🔑 Note: Every classification problem will require different kinds of evaluation methods. But you should be familiar with at least the ones above.
Let's start with accuracy.
Because we passed ["accuracy"] to the metrics parameter when we compiled our model, calling evaluate() on it will return the loss as well as accuracy.
# Check the accuracy of our model
loss, accuracy = model_10.evaluate(X_test, y_test)
print(f"Model loss on test set: {loss}")
print(f"Model accuracy on test set: {(accuracy*100):.2f}%")
7/7 [==============================] - 0s 3ms/step - loss: 0.0425 - accuracy: 1.0000 Model loss on test set: 0.042508091777563095 Model accuracy on test set: 100.00%
How about a confusion matrix?
 Anatomy of a confusion matrix (what we're going to be creating). Correct predictions appear down the diagonal (from top left to bottom right).
Anatomy of a confusion matrix (what we're going to be creating). Correct predictions appear down the diagonal (from top left to bottom right).
We can make a confusion matrix using Scikit-Learn's confusion_matrix method.
# Create a confusion matrix
from sklearn.metrics import confusion_matrix
# Make predictions
y_preds = model_10.predict(X_test)
# Create confusion matrix
confusion_matrix(y_test, y_preds)
7/7 [==============================] - 0s 2ms/step
--------------------------------------------------------------------------- ValueError Traceback (most recent call last) <ipython-input-58-f9843efd97f5> in <cell line: 8>() 6 7 # Create confusion matrix ----> 8 confusion_matrix(y_test, y_preds) /usr/local/lib/python3.10/dist-packages/sklearn/metrics/_classification.py in confusion_matrix(y_true, y_pred, labels, sample_weight, normalize) 315 (0, 2, 1, 1) 316 """ --> 317 y_type, y_true, y_pred = _check_targets(y_true, y_pred) 318 if y_type not in ("binary", "multiclass"): 319 raise ValueError("%s is not supported" % y_type) /usr/local/lib/python3.10/dist-packages/sklearn/metrics/_classification.py in _check_targets(y_true, y_pred) 93 94 if len(y_type) > 1: ---> 95 raise ValueError( 96 "Classification metrics can't handle a mix of {0} and {1} targets".format( 97 type_true, type_pred ValueError: Classification metrics can't handle a mix of binary and continuous targets
Ahh, it seems our predictions aren't in the format they need to be.
Let's check them out.
# View the first 10 predictions
y_preds[:10]
array([[0.9740965 ],
[0.9740965 ],
[0.9740965 ],
[0.9740965 ],
[0.47072026],
[0.00771922],
[0.9740965 ],
[0.00127994],
[0.9740965 ],
[0.00113649]], dtype=float32)
What about our test labels?
# View the first 10 test labels
y_test[:10]
array([1, 1, 1, 1, 0, 0, 1, 0, 1, 0])
It looks like we need to get our predictions into the binary format (0 or 1).
But you might be wondering, what format are they currently in?
In their current format (9.8526537e-01), they're in a form called prediction probabilities.
You'll see this often with the outputs of neural networks. Often they won't be exact values but more a probability of how likely they are to be one value or another.
So one of the steps you'll often see after making predicitons with a neural network is converting the prediction probabilities into labels.
In our case, since our ground truth labels (y_test) are binary (0 or 1), we can convert the prediction probabilities using to their binary form using tf.round().
# Convert prediction probabilities to binary format and view the first 10
tf.round(y_preds)[:10]
<tf.Tensor: shape=(10, 1), dtype=float32, numpy=
array([[1.],
[1.],
[1.],
[1.],
[0.],
[0.],
[1.],
[0.],
[1.],
[0.]], dtype=float32)>
Wonderful! Now we can use the confusion_matrix function.
# Create a confusion matrix
confusion_matrix(y_test, tf.round(y_preds))
array([[101, 0],
[ 0, 99]])
Alright, we can see the highest numbers are down the diagonal (from top left to bottom right) so this a good sign, but the rest of the matrix doesn't really tell us much.
How about we make a function to make our confusion matrix a little more visual?
# Note: The following confusion matrix code is a remix of Scikit-Learn's
# plot_confusion_matrix function - https://scikit-learn.org/stable/modules/generated/sklearn.metrics.plot_confusion_matrix.html
# and Made with ML's introductory notebook - https://github.com/GokuMohandas/MadeWithML/blob/main/notebooks/08_Neural_Networks.ipynb
import itertools
figsize = (10, 10)
# Create the confusion matrix
cm = confusion_matrix(y_test, tf.round(y_preds))
cm_norm = cm.astype("float") / cm.sum(axis=1)[:, np.newaxis] # normalize it
n_classes = cm.shape[0]
# Let's prettify it
fig, ax = plt.subplots(figsize=figsize)
# Create a matrix plot
cax = ax.matshow(cm, cmap=plt.cm.Blues) # https://matplotlib.org/3.2.0/api/_as_gen/matplotlib.axes.Axes.matshow.html
fig.colorbar(cax)
# Create classes
classes = False
if classes:
labels = classes
else:
labels = np.arange(cm.shape[0])
# Label the axes
ax.set(title="Confusion Matrix",
xlabel="Predicted label",
ylabel="True label",
xticks=np.arange(n_classes),
yticks=np.arange(n_classes),
xticklabels=labels,
yticklabels=labels)
# Set x-axis labels to bottom
ax.xaxis.set_label_position("bottom")
ax.xaxis.tick_bottom()
# Adjust label size
ax.xaxis.label.set_size(20)
ax.yaxis.label.set_size(20)
ax.title.set_size(20)
# Set threshold for different colors
threshold = (cm.max() + cm.min()) / 2.
# Plot the text on each cell
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, f"{cm[i, j]} ({cm_norm[i, j]*100:.1f}%)",
horizontalalignment="center",
color="white" if cm[i, j] > threshold else "black",
size=15)

That looks much better. It seems our model has made almost perfect predictions on the test set except for two false positives (top right corner).
# What does itertools.product do? Combines two things into each combination
import itertools
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
print(i, j)
0 0 0 1 1 0 1 1
Working with a larger example (multiclass classification)¶
We've seen a binary classification example (predicting if a data point is part of a red circle or blue circle) but what if you had multiple different classes of things?
For example, say you were a fashion company and you wanted to build a neural network to predict whether a piece of clothing was a shoe, a shirt or a jacket (3 different options).
When you have more than two classes as an option, this is known as multiclass classification.
The good news is, the things we've learned so far (with a few tweaks) can be applied to multiclass classification problems as well.
Let's see it in action.
To start, we'll need some data. The good thing for us is TensorFlow has a multiclass classication dataset known as Fashion MNIST built-in. Meaning we can get started straight away.
We can import it using the tf.keras.datasets module.
📖 Resource: The following multiclass classification problem has been adapted from the TensorFlow classification guide. A good exercise would be to once you've gone through the following example, replicate the TensorFlow guide.
import tensorflow as tf
from tensorflow.keras.datasets import fashion_mnist
# The data has already been sorted into training and test sets for us
(train_data, train_labels), (test_data, test_labels) = fashion_mnist.load_data()
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz 29515/29515 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz 26421880/26421880 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz 5148/5148 [==============================] - 0s 0us/step Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz 4422102/4422102 [==============================] - 0s 0us/step
Now let's check out an example.
# Show the first training example
print(f"Training sample:\n{train_data[0]}\n")
print(f"Training label: {train_labels[0]}")
Training sample:
[[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 13 73 0
0 1 4 0 0 0 0 1 1 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 3 0 36 136 127 62
54 0 0 0 1 3 4 0 0 3]
[ 0 0 0 0 0 0 0 0 0 0 0 0 6 0 102 204 176 134
144 123 23 0 0 0 0 12 10 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 155 236 207 178
107 156 161 109 64 23 77 130 72 15]
[ 0 0 0 0 0 0 0 0 0 0 0 1 0 69 207 223 218 216
216 163 127 121 122 146 141 88 172 66]
[ 0 0 0 0 0 0 0 0 0 1 1 1 0 200 232 232 233 229
223 223 215 213 164 127 123 196 229 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 183 225 216 223 228
235 227 224 222 224 221 223 245 173 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 193 228 218 213 198
180 212 210 211 213 223 220 243 202 0]
[ 0 0 0 0 0 0 0 0 0 1 3 0 12 219 220 212 218 192
169 227 208 218 224 212 226 197 209 52]
[ 0 0 0 0 0 0 0 0 0 0 6 0 99 244 222 220 218 203
198 221 215 213 222 220 245 119 167 56]
[ 0 0 0 0 0 0 0 0 0 4 0 0 55 236 228 230 228 240
232 213 218 223 234 217 217 209 92 0]
[ 0 0 1 4 6 7 2 0 0 0 0 0 237 226 217 223 222 219
222 221 216 223 229 215 218 255 77 0]
[ 0 3 0 0 0 0 0 0 0 62 145 204 228 207 213 221 218 208
211 218 224 223 219 215 224 244 159 0]
[ 0 0 0 0 18 44 82 107 189 228 220 222 217 226 200 205 211 230
224 234 176 188 250 248 233 238 215 0]
[ 0 57 187 208 224 221 224 208 204 214 208 209 200 159 245 193 206 223
255 255 221 234 221 211 220 232 246 0]
[ 3 202 228 224 221 211 211 214 205 205 205 220 240 80 150 255 229 221
188 154 191 210 204 209 222 228 225 0]
[ 98 233 198 210 222 229 229 234 249 220 194 215 217 241 65 73 106 117
168 219 221 215 217 223 223 224 229 29]
[ 75 204 212 204 193 205 211 225 216 185 197 206 198 213 240 195 227 245
239 223 218 212 209 222 220 221 230 67]
[ 48 203 183 194 213 197 185 190 194 192 202 214 219 221 220 236 225 216
199 206 186 181 177 172 181 205 206 115]
[ 0 122 219 193 179 171 183 196 204 210 213 207 211 210 200 196 194 191
195 191 198 192 176 156 167 177 210 92]
[ 0 0 74 189 212 191 175 172 175 181 185 188 189 188 193 198 204 209
210 210 211 188 188 194 192 216 170 0]
[ 2 0 0 0 66 200 222 237 239 242 246 243 244 221 220 193 191 179
182 182 181 176 166 168 99 58 0 0]
[ 0 0 0 0 0 0 0 40 61 44 72 41 35 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]
[ 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0]]
Training label: 9
Woah, we get a large list of numbers, followed (the data) by a single number (the class label).
What about the shapes?
# Check the shape of our data
train_data.shape, train_labels.shape, test_data.shape, test_labels.shape
((60000, 28, 28), (60000,), (10000, 28, 28), (10000,))
# Check shape of a single example
train_data[0].shape, train_labels[0].shape
((28, 28), ())
Okay, 60,000 training examples each with shape (28, 28) and a label each as well as 10,000 test examples of shape (28, 28).
But these are just numbers, let's visualize.
# Plot a single example
import matplotlib.pyplot as plt
plt.imshow(train_data[7]);

Hmm, but what about its label?
# Check our samples label
train_labels[7]
2
It looks like our labels are in numerical form. And while this is fine for a neural network, you might want to have them in human readable form.
Let's create a small list of the class names (we can find them on the dataset's GitHub page).
🔑 Note: Whilst this dataset has been prepared for us and ready to go, it's important to remember many datasets won't be ready to go like this one. Often you'll have to do a few preprocessing steps to have it ready to use with a neural network (we'll see more of this when we work with our own data later).
class_names = ['T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat',
'Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot']
# How many classes are there (this'll be our output shape)?
len(class_names)
10
Now we have these, let's plot another example.
🤔 Question: Pay particular attention to what the data we're working with looks like. Is it only straight lines? Or does it have non-straight lines as well? Do you think if we wanted to find patterns in the photos of clothes (which are actually collections of pixels), will our model need non-linearities (non-straight lines) or not?
# Plot an example image and its label
plt.imshow(train_data[17], cmap=plt.cm.binary) # change the colours to black & white
plt.title(class_names[train_labels[17]]);

# Plot multiple random images of fashion MNIST
import random
plt.figure(figsize=(7, 7))
for i in range(4):
ax = plt.subplot(2, 2, i + 1)
rand_index = random.choice(range(len(train_data)))
plt.imshow(train_data[rand_index], cmap=plt.cm.binary)
plt.title(class_names[train_labels[rand_index]])
plt.axis(False)

Alright, let's build a model to figure out the relationship between the pixel values and their labels.
Since this is a multiclass classification problem, we'll need to make a few changes to our architecture (inline with Table 1 above):
- The input shape will have to deal with 28x28 tensors (the height and width of our images).
- We're actually going to squash the input into a tensor (vector) of shape
(784).
- We're actually going to squash the input into a tensor (vector) of shape
- The output shape will have to be 10 because we need our model to predict for 10 different classes.
- We'll also change the
activationparameter of our output layer to be"softmax"instead of'sigmoid'. As we'll see the"softmax"activation function outputs a series of values between 0 & 1 (the same shape as output shape, which together add up to ~1. The index with the highest value is predicted by the model to be the most likely class.
- We'll also change the
- We'll need to change our loss function from a binary loss function to a multiclass loss function.
- More specifically, since our labels are in integer form, we'll use
tf.keras.losses.SparseCategoricalCrossentropy(), if our labels were one-hot encoded (e.g. they looked something like[0, 0, 1, 0, 0...]), we'd usetf.keras.losses.CategoricalCrossentropy().
- More specifically, since our labels are in integer form, we'll use
- We'll also use the
validation_dataparameter when calling thefit()function. This will give us an idea of how the model performs on the test set during training.
You ready? Let's go.
# Set random seed
tf.random.set_seed(42)
# Create the model
model_11 = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # input layer (we had to reshape 28x28 to 784, the Flatten layer does this for us)
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax") # output shape is 10, activation is softmax
])
# Compile the model
model_11.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(), # different loss function for multiclass classifcation
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
# Fit the model
non_norm_history = model_11.fit(train_data,
train_labels,
epochs=10,
validation_data=(test_data, test_labels)) # see how the model performs on the test set during training
Epoch 1/10 1875/1875 [==============================] - 8s 3ms/step - loss: 2.1829 - accuracy: 0.1931 - val_loss: 2.1994 - val_accuracy: 0.2037 Epoch 2/10 1875/1875 [==============================] - 6s 3ms/step - loss: 1.8995 - accuracy: 0.2442 - val_loss: 1.8438 - val_accuracy: 0.2579 Epoch 3/10 1875/1875 [==============================] - 6s 3ms/step - loss: 1.7651 - accuracy: 0.2615 - val_loss: 1.7387 - val_accuracy: 0.2779 Epoch 4/10 1875/1875 [==============================] - 6s 3ms/step - loss: 1.6032 - accuracy: 0.2936 - val_loss: 1.5459 - val_accuracy: 0.3104 Epoch 5/10 1875/1875 [==============================] - 6s 3ms/step - loss: 1.5402 - accuracy: 0.3038 - val_loss: 1.5040 - val_accuracy: 0.3089 Epoch 6/10 1875/1875 [==============================] - 5s 3ms/step - loss: 1.4902 - accuracy: 0.3207 - val_loss: 1.4725 - val_accuracy: 0.3131 Epoch 7/10 1875/1875 [==============================] - 5s 3ms/step - loss: 1.4667 - accuracy: 0.3323 - val_loss: 1.4497 - val_accuracy: 0.3634 Epoch 8/10 1875/1875 [==============================] - 6s 3ms/step - loss: 1.4550 - accuracy: 0.3469 - val_loss: 1.4640 - val_accuracy: 0.3559 Epoch 9/10 1875/1875 [==============================] - 5s 3ms/step - loss: 1.4280 - accuracy: 0.3549 - val_loss: 1.4428 - val_accuracy: 0.3422 Epoch 10/10 1875/1875 [==============================] - 6s 3ms/step - loss: 1.4292 - accuracy: 0.3542 - val_loss: 1.5142 - val_accuracy: 0.3405
# Check the shapes of our model
# Note: the "None" in (None, 784) is for batch_size, we'll cover this in a later module
model_11.summary()
Model: "sequential_11"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten (Flatten) (None, 784) 0
dense_28 (Dense) (None, 4) 3140
dense_29 (Dense) (None, 4) 20
dense_30 (Dense) (None, 10) 50
=================================================================
Total params: 3210 (12.54 KB)
Trainable params: 3210 (12.54 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Alright, our model gets to about ~35% accuracy after 10 epochs using a similar style model to what we used on our binary classification problem.
Which is better than guessing (guessing with 10 classes would result in about 10% accuracy) but we can do better.
Do you remember when we talked about neural networks preferring numbers between 0 and 1? (if not, treat this as a reminder)
Well, right now, the data we have isn't between 0 and 1, in other words, it's not normalized (hence why we used the non_norm_history variable when calling fit()). It's pixel values are between 0 and 255.
Let's see.
# Check the min and max values of the training data
train_data.min(), train_data.max()
(0, 255)
We can get these values between 0 and 1 by dividing the entire array by the maximum: 255.0 (dividing by a float also converts to a float).
Doing so will result in all of our data being between 0 and 1 (known as scaling or normalization).
# Divide train and test images by the maximum value (normalize it)
train_data = train_data / 255.0
test_data = test_data / 255.0
# Check the min and max values of the training data
train_data.min(), train_data.max()
(0.0, 1.0)
Beautiful! Now our data is between 0 and 1. Let's see what happens when we model it.
We'll use the same model as before (model_11) except this time the data will be normalized.
# Set random seed
tf.random.set_seed(42)
# Create the model
model_12 = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # input layer (we had to reshape 28x28 to 784)
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax") # output shape is 10, activation is softmax
])
# Compile the model
model_12.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(),
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
# Fit the model (to the normalized data)
norm_history = model_12.fit(train_data,
train_labels,
epochs=10,
validation_data=(test_data, test_labels))
Epoch 1/10 1875/1875 [==============================] - 7s 3ms/step - loss: 1.2368 - accuracy: 0.5151 - val_loss: 0.9158 - val_accuracy: 0.6197 Epoch 2/10 1875/1875 [==============================] - 5s 3ms/step - loss: 0.8054 - accuracy: 0.6939 - val_loss: 0.7300 - val_accuracy: 0.7337 Epoch 3/10 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6805 - accuracy: 0.7524 - val_loss: 0.6827 - val_accuracy: 0.7570 Epoch 4/10 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6427 - accuracy: 0.7661 - val_loss: 0.6599 - val_accuracy: 0.7663 Epoch 5/10 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6258 - accuracy: 0.7735 - val_loss: 0.6568 - val_accuracy: 0.7681 Epoch 6/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6138 - accuracy: 0.7784 - val_loss: 0.6378 - val_accuracy: 0.7772 Epoch 7/10 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6056 - accuracy: 0.7817 - val_loss: 0.6611 - val_accuracy: 0.7562 Epoch 8/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.5993 - accuracy: 0.7842 - val_loss: 0.6351 - val_accuracy: 0.7798 Epoch 9/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.5905 - accuracy: 0.7881 - val_loss: 0.6232 - val_accuracy: 0.7782 Epoch 10/10 1875/1875 [==============================] - 6s 3ms/step - loss: 0.5867 - accuracy: 0.7911 - val_loss: 0.6203 - val_accuracy: 0.7818
Woah, we used the exact same model as before but we with normalized data we're now seeing a much higher accuracy value!
Let's plot each model's history (their loss curves).
import pandas as pd
# Plot non-normalized data loss curves
pd.DataFrame(non_norm_history.history).plot(title="Non-normalized Data")
# Plot normalized data loss curves
pd.DataFrame(norm_history.history).plot(title="Normalized data");


Wow. From these two plots, we can see how much quicker our model with the normalized data (model_12) improved than the model with the non-normalized data (model_11).
🔑 Note: The same model with even slightly different data can produce dramatically different results. So when you're comparing models, it's important to make sure you're comparing them on the same criteria (e.g. same architecture but different data or same data but different architecture).
How about we find the ideal learning rate and see what happens?
We'll use the same architecture we've been using.
# Set random seed
tf.random.set_seed(42)
# Create the model
model_13 = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # input layer (we had to reshape 28x28 to 784)
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax") # output shape is 10, activation is softmax
])
# Compile the model
model_13.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(),
optimizer=tf.keras.optimizers.Adam(),
metrics=["accuracy"])
# Create the learning rate callback
lr_scheduler = tf.keras.callbacks.LearningRateScheduler(lambda epoch: 1e-3 * 10**(epoch/20))
# Fit the model
find_lr_history = model_13.fit(train_data,
train_labels,
epochs=40, # model already doing pretty good with current LR, probably don't need 100 epochs
validation_data=(test_data, test_labels),
callbacks=[lr_scheduler])
Epoch 1/40 1875/1875 [==============================] - 7s 3ms/step - loss: 1.3489 - accuracy: 0.5091 - val_loss: 1.0140 - val_accuracy: 0.6485 - lr: 0.0010 Epoch 2/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.8974 - accuracy: 0.6739 - val_loss: 0.8554 - val_accuracy: 0.6812 - lr: 0.0011 Epoch 3/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.7930 - accuracy: 0.7102 - val_loss: 0.7868 - val_accuracy: 0.6940 - lr: 0.0013 Epoch 4/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.7509 - accuracy: 0.7236 - val_loss: 0.7557 - val_accuracy: 0.7129 - lr: 0.0014 Epoch 5/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.7246 - accuracy: 0.7306 - val_loss: 0.7407 - val_accuracy: 0.7340 - lr: 0.0016 Epoch 6/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.7055 - accuracy: 0.7378 - val_loss: 0.7294 - val_accuracy: 0.7424 - lr: 0.0018 Epoch 7/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6916 - accuracy: 0.7442 - val_loss: 0.7072 - val_accuracy: 0.7379 - lr: 0.0020 Epoch 8/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6764 - accuracy: 0.7509 - val_loss: 0.7037 - val_accuracy: 0.7459 - lr: 0.0022 Epoch 9/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6649 - accuracy: 0.7562 - val_loss: 0.6898 - val_accuracy: 0.7578 - lr: 0.0025 Epoch 10/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6596 - accuracy: 0.7585 - val_loss: 0.7213 - val_accuracy: 0.7497 - lr: 0.0028 Epoch 11/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6526 - accuracy: 0.7628 - val_loss: 0.7046 - val_accuracy: 0.7515 - lr: 0.0032 Epoch 12/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6484 - accuracy: 0.7644 - val_loss: 0.6996 - val_accuracy: 0.7602 - lr: 0.0035 Epoch 13/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6383 - accuracy: 0.7674 - val_loss: 0.6949 - val_accuracy: 0.7657 - lr: 0.0040 Epoch 14/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6361 - accuracy: 0.7695 - val_loss: 0.6696 - val_accuracy: 0.7616 - lr: 0.0045 Epoch 15/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6343 - accuracy: 0.7717 - val_loss: 0.6948 - val_accuracy: 0.7563 - lr: 0.0050 Epoch 16/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6297 - accuracy: 0.7751 - val_loss: 0.6591 - val_accuracy: 0.7772 - lr: 0.0056 Epoch 17/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6207 - accuracy: 0.7827 - val_loss: 0.6500 - val_accuracy: 0.7791 - lr: 0.0063 Epoch 18/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6184 - accuracy: 0.7862 - val_loss: 0.6448 - val_accuracy: 0.7823 - lr: 0.0071 Epoch 19/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6161 - accuracy: 0.7865 - val_loss: 0.6276 - val_accuracy: 0.7931 - lr: 0.0079 Epoch 20/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6152 - accuracy: 0.7868 - val_loss: 0.6336 - val_accuracy: 0.7889 - lr: 0.0089 Epoch 21/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6146 - accuracy: 0.7876 - val_loss: 0.6349 - val_accuracy: 0.7811 - lr: 0.0100 Epoch 22/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6176 - accuracy: 0.7863 - val_loss: 0.6349 - val_accuracy: 0.7908 - lr: 0.0112 Epoch 23/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6217 - accuracy: 0.7857 - val_loss: 0.7139 - val_accuracy: 0.7555 - lr: 0.0126 Epoch 24/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6278 - accuracy: 0.7825 - val_loss: 0.7166 - val_accuracy: 0.7612 - lr: 0.0141 Epoch 25/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6356 - accuracy: 0.7805 - val_loss: 0.7001 - val_accuracy: 0.7508 - lr: 0.0158 Epoch 26/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6377 - accuracy: 0.7787 - val_loss: 0.7146 - val_accuracy: 0.7597 - lr: 0.0178 Epoch 27/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6791 - accuracy: 0.7617 - val_loss: 0.6618 - val_accuracy: 0.7748 - lr: 0.0200 Epoch 28/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6538 - accuracy: 0.7726 - val_loss: 0.6899 - val_accuracy: 0.7610 - lr: 0.0224 Epoch 29/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6791 - accuracy: 0.7612 - val_loss: 0.6711 - val_accuracy: 0.7719 - lr: 0.0251 Epoch 30/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6992 - accuracy: 0.7521 - val_loss: 0.7585 - val_accuracy: 0.7172 - lr: 0.0282 Epoch 31/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.7305 - accuracy: 0.7406 - val_loss: 0.7314 - val_accuracy: 0.7392 - lr: 0.0316 Epoch 32/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.7689 - accuracy: 0.7179 - val_loss: 0.8037 - val_accuracy: 0.6799 - lr: 0.0355 Epoch 33/40 1875/1875 [==============================] - 5s 3ms/step - loss: 1.0027 - accuracy: 0.6074 - val_loss: 1.0677 - val_accuracy: 0.5509 - lr: 0.0398 Epoch 34/40 1875/1875 [==============================] - 6s 3ms/step - loss: 0.9718 - accuracy: 0.6132 - val_loss: 1.0379 - val_accuracy: 0.5977 - lr: 0.0447 Epoch 35/40 1875/1875 [==============================] - 5s 3ms/step - loss: 1.0091 - accuracy: 0.6153 - val_loss: 0.9773 - val_accuracy: 0.6447 - lr: 0.0501 Epoch 36/40 1875/1875 [==============================] - 5s 3ms/step - loss: 0.9577 - accuracy: 0.6454 - val_loss: 0.8809 - val_accuracy: 0.6806 - lr: 0.0562 Epoch 37/40 1875/1875 [==============================] - 5s 3ms/step - loss: 1.0135 - accuracy: 0.6252 - val_loss: 1.0258 - val_accuracy: 0.6005 - lr: 0.0631 Epoch 38/40 1875/1875 [==============================] - 6s 3ms/step - loss: 1.0135 - accuracy: 0.6163 - val_loss: 0.9384 - val_accuracy: 0.6446 - lr: 0.0708 Epoch 39/40 1875/1875 [==============================] - 5s 3ms/step - loss: 1.1192 - accuracy: 0.5747 - val_loss: 1.0548 - val_accuracy: 0.5785 - lr: 0.0794 Epoch 40/40 1875/1875 [==============================] - 6s 3ms/step - loss: 1.2500 - accuracy: 0.5285 - val_loss: 1.5707 - val_accuracy: 0.4179 - lr: 0.0891
# Plot the learning rate decay curve
import numpy as np
import matplotlib.pyplot as plt
lrs = 1e-3 * (10**(np.arange(40)/20))
plt.semilogx(lrs, find_lr_history.history["loss"]) # want the x-axis to be log-scale
plt.xlabel("Learning rate")
plt.ylabel("Loss")
plt.title("Finding the ideal learning rate");

In this case, it looks like somewhere close to the default learning rate of the Adam optimizer (0.001) is the ideal learning rate.
Let's refit a model using the ideal learning rate.
# Set random seed
tf.random.set_seed(42)
# Create the model
model_14 = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # input layer (we had to reshape 28x28 to 784)
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(4, activation="relu"),
tf.keras.layers.Dense(10, activation="softmax") # output shape is 10, activation is softmax
])
# Compile the model
model_14.compile(loss=tf.keras.losses.SparseCategoricalCrossentropy(),
optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), # ideal learning rate (same as default)
metrics=["accuracy"])
# Fit the model
history = model_14.fit(train_data,
train_labels,
epochs=20,
validation_data=(test_data, test_labels))
Epoch 1/20 1875/1875 [==============================] - 7s 3ms/step - loss: 1.1588 - accuracy: 0.6050 - val_loss: 0.7818 - val_accuracy: 0.7258 Epoch 2/20 1875/1875 [==============================] - 6s 3ms/step - loss: 0.7097 - accuracy: 0.7484 - val_loss: 0.7062 - val_accuracy: 0.7526 Epoch 3/20 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6528 - accuracy: 0.7655 - val_loss: 0.6678 - val_accuracy: 0.7645 Epoch 4/20 1875/1875 [==============================] - 6s 3ms/step - loss: 0.6249 - accuracy: 0.7756 - val_loss: 0.6516 - val_accuracy: 0.7684 Epoch 5/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.6082 - accuracy: 0.7798 - val_loss: 0.6405 - val_accuracy: 0.7733 Epoch 6/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5946 - accuracy: 0.7838 - val_loss: 0.6344 - val_accuracy: 0.7743 Epoch 7/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5855 - accuracy: 0.7868 - val_loss: 0.6231 - val_accuracy: 0.7768 Epoch 8/20 1875/1875 [==============================] - 6s 3ms/step - loss: 0.5773 - accuracy: 0.7880 - val_loss: 0.6256 - val_accuracy: 0.7737 Epoch 9/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5716 - accuracy: 0.7909 - val_loss: 0.6134 - val_accuracy: 0.7812 Epoch 10/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5653 - accuracy: 0.7930 - val_loss: 0.6030 - val_accuracy: 0.7843 Epoch 11/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5604 - accuracy: 0.7944 - val_loss: 0.5985 - val_accuracy: 0.7849 Epoch 12/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5544 - accuracy: 0.7972 - val_loss: 0.5951 - val_accuracy: 0.7868 Epoch 13/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5513 - accuracy: 0.7966 - val_loss: 0.5940 - val_accuracy: 0.7893 Epoch 14/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5462 - accuracy: 0.7994 - val_loss: 0.5953 - val_accuracy: 0.7864 Epoch 15/20 1875/1875 [==============================] - 6s 3ms/step - loss: 0.5420 - accuracy: 0.8008 - val_loss: 0.5860 - val_accuracy: 0.7911 Epoch 16/20 1875/1875 [==============================] - 6s 3ms/step - loss: 0.5388 - accuracy: 0.8016 - val_loss: 0.5901 - val_accuracy: 0.7927 Epoch 17/20 1875/1875 [==============================] - 6s 3ms/step - loss: 0.5359 - accuracy: 0.8025 - val_loss: 0.5889 - val_accuracy: 0.7898 Epoch 18/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5341 - accuracy: 0.8028 - val_loss: 0.5746 - val_accuracy: 0.7959 Epoch 19/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5305 - accuracy: 0.8036 - val_loss: 0.5861 - val_accuracy: 0.7897 Epoch 20/20 1875/1875 [==============================] - 5s 3ms/step - loss: 0.5271 - accuracy: 0.8071 - val_loss: 0.5726 - val_accuracy: 0.7970
Now we've got a model trained with a close-to-ideal learning rate and performing pretty well, we've got a couple of options.
We could:
- Evaluate its performance using other classification metrics (such as a confusion matrix or classification report).
- Assess some of its predictions (through visualizations).
- Improve its accuracy (by training it for longer or changing the architecture).
- Save and export it for use in an application.
Let's go through the first two options.
First we'll create a classification matrix to visualize its predictions across the different classes.
# Note: The following confusion matrix code is a remix of Scikit-Learn's
# plot_confusion_matrix function - https://scikit-learn.org/stable/modules/generated/sklearn.metrics.plot_confusion_matrix.html
# and Made with ML's introductory notebook - https://github.com/GokuMohandas/MadeWithML/blob/main/notebooks/08_Neural_Networks.ipynb
import itertools
from sklearn.metrics import confusion_matrix
# Our function needs a different name to sklearn's plot_confusion_matrix
def make_confusion_matrix(y_true, y_pred, classes=None, figsize=(10, 10), text_size=15):
"""Makes a labelled confusion matrix comparing predictions and ground truth labels.
If classes is passed, confusion matrix will be labelled, if not, integer class values
will be used.
Args:
y_true: Array of truth labels (must be same shape as y_pred).
y_pred: Array of predicted labels (must be same shape as y_true).
classes: Array of class labels (e.g. string form). If `None`, integer labels are used.
figsize: Size of output figure (default=(10, 10)).
text_size: Size of output figure text (default=15).
Returns:
A labelled confusion matrix plot comparing y_true and y_pred.
Example usage:
make_confusion_matrix(y_true=test_labels, # ground truth test labels
y_pred=y_preds, # predicted labels
classes=class_names, # array of class label names
figsize=(15, 15),
text_size=10)
"""
# Create the confustion matrix
cm = confusion_matrix(y_true, y_pred)
cm_norm = cm.astype("float") / cm.sum(axis=1)[:, np.newaxis] # normalize it
n_classes = cm.shape[0] # find the number of classes we're dealing with
# Plot the figure and make it pretty
fig, ax = plt.subplots(figsize=figsize)
cax = ax.matshow(cm, cmap=plt.cm.Blues) # colors will represent how 'correct' a class is, darker == better
fig.colorbar(cax)
# Are there a list of classes?
if classes:
labels = classes
else:
labels = np.arange(cm.shape[0])
# Label the axes
ax.set(title="Confusion Matrix",
xlabel="Predicted label",
ylabel="True label",
xticks=np.arange(n_classes), # create enough axis slots for each class
yticks=np.arange(n_classes),
xticklabels=labels, # axes will labeled with class names (if they exist) or ints
yticklabels=labels)
# Make x-axis labels appear on bottom
ax.xaxis.set_label_position("bottom")
ax.xaxis.tick_bottom()
# Set the threshold for different colors
threshold = (cm.max() + cm.min()) / 2.
# Plot the text on each cell
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, f"{cm[i, j]} ({cm_norm[i, j]*100:.1f}%)",
horizontalalignment="center",
color="white" if cm[i, j] > threshold else "black",
size=text_size)
Since a confusion matrix compares the truth labels (test_labels) to the predicted labels, we have to make some predictions with our model.
# Make predictions with the most recent model
y_probs = model_14.predict(test_data) # "probs" is short for probabilities
# View the first 5 predictions
y_probs[:5]
313/313 [==============================] - 1s 1ms/step
array([[7.1295396e-08, 0.0000000e+00, 3.3289107e-12, 5.1906879e-20,
2.2590930e-15, 2.9898265e-01, 1.3648585e-07, 7.8765094e-02,
8.4200781e-03, 6.1383194e-01],
[2.3802532e-02, 4.3833437e-03, 7.4165797e-01, 9.3923630e-03,
4.8104558e-02, 1.6303338e-03, 1.6198176e-01, 2.8633869e-07,
9.0436097e-03, 3.2003202e-06],
[1.6573335e-06, 9.9551845e-01, 9.1274740e-07, 4.4626528e-03,
1.4068096e-05, 4.6464342e-16, 2.2328247e-06, 6.8920781e-22,
2.8975861e-10, 3.0581186e-15],
[2.8563186e-08, 9.9863142e-01, 4.3472301e-09, 1.3678216e-03,
6.5454623e-07, 6.7064722e-21, 3.1206884e-08, 3.7914244e-28,
6.2471518e-13, 5.6674063e-19],
[2.8196907e-01, 5.4220832e-06, 4.3520968e-02, 3.0695686e-02,
2.1239575e-02, 2.4910512e-05, 5.9459400e-01, 1.5045735e-09,
2.7928762e-02, 2.1589773e-05]], dtype=float32)
Our model outputs a list of prediction probabilities, meaning, it outputs a number for how likely it thinks a particular class is to be the label.
The higher the number in the prediction probabilities list, the more likely the model believes that is the right class.
To find the highest value we can use the argmax() method.
# See the predicted class number and label for the first example
y_probs[0].argmax(), class_names[y_probs[0].argmax()]
(9, 'Ankle boot')
Now let's do the same for all of the predictions.
# Convert all of the predictions from probabilities to labels
y_preds = y_probs.argmax(axis=1)
# View the first 10 prediction labels
y_preds[:10]
array([9, 2, 1, 1, 6, 1, 4, 4, 5, 7])
Wonderful, now we've got our model's predictions in label form, let's create a confusion matrix to view them against the truth labels.
# Check out the non-prettified confusion matrix
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true=test_labels,
y_pred=y_preds)
array([[759, 0, 30, 71, 6, 1, 124, 0, 8, 1],
[ 0, 939, 11, 40, 5, 0, 5, 0, 0, 0],
[ 21, 2, 730, 9, 176, 0, 59, 0, 3, 0],
[ 38, 11, 17, 839, 41, 0, 50, 0, 4, 0],
[ 0, 0, 125, 28, 805, 0, 38, 0, 4, 0],
[ 1, 0, 0, 0, 0, 901, 1, 55, 11, 31],
[177, 2, 185, 42, 321, 0, 264, 0, 9, 0],
[ 0, 0, 0, 0, 0, 50, 0, 917, 0, 33],
[ 5, 0, 8, 3, 16, 17, 49, 4, 897, 1],
[ 0, 0, 0, 0, 0, 21, 0, 49, 11, 919]])
That confusion matrix is hard to comprehend, let's make it prettier using the function we created before.
# Make a prettier confusion matrix
make_confusion_matrix(y_true=test_labels,
y_pred=y_preds,
classes=class_names,
figsize=(15, 15),
text_size=10)

That looks much better! (one of my favourites sights in the world is a confusion matrix with dark squares down the diagonal)
Except the results aren't as good as they could be...
It looks like our model is getting confused between the Shirt and T-shirt/top classes (e.g. predicting Shirt when it's actually a T-shirt/top).
🤔 Question: Does it make sense that our model is getting confused between the
ShirtandT-shirt/topclasses? Why do you think this might be? What's one way you could investigate?
We've seen how our models predictions line up to the truth labels using a confusion matrix, but how about we visualize some?
Let's create a function to plot a random image along with its prediction.
🔑 Note: Often when working with images and other forms of visual data, it's a good idea to visualize as much as possible to develop a further understanding of the data and the outputs of your model.
import random
# Create a function for plotting a random image along with its prediction
def plot_random_image(model, images, true_labels, classes):
"""Picks a random image, plots it and labels it with a predicted and truth label.
Args:
model: a trained model (trained on data similar to what's in images).
images: a set of random images (in tensor form).
true_labels: array of ground truth labels for images.
classes: array of class names for images.
Returns:
A plot of a random image from `images` with a predicted class label from `model`
as well as the truth class label from `true_labels`.
"""
# Setup random integer
i = random.randint(0, len(images))
# Create predictions and targets
target_image = images[i]
pred_probs = model.predict(target_image.reshape(1, 28, 28)) # have to reshape to get into right size for model
pred_label = classes[pred_probs.argmax()]
true_label = classes[true_labels[i]]
# Plot the target image
plt.imshow(target_image, cmap=plt.cm.binary)
# Change the color of the titles depending on if the prediction is right or wrong
if pred_label == true_label:
color = "green"
else:
color = "red"
# Add xlabel information (prediction/true label)
plt.xlabel("Pred: {} {:2.0f}% (True: {})".format(pred_label,
100*tf.reduce_max(pred_probs),
true_label),
color=color) # set the color to green or red
# Check out a random image as well as its prediction
plot_random_image(model=model_14,
images=test_data,
true_labels=test_labels,
classes=class_names)
1/1 [==============================] - 0s 22ms/step

After running the cell above a few times you'll start to get a visual understanding of the relationship between the model's predictions and the true labels.
Did you figure out which predictions the model gets confused on?
It seems to mix up classes which are similar, for example, Sneaker with Ankle boot.
Looking at the images, you can see how this might be the case.
The overall shape of a Sneaker and an Ankle Boot are similar.
The overall shape might be one of the patterns the model has learned and so therefore when two images have a similar shape, their predictions get mixed up.
What patterns is our model learning?¶
We've been talking a lot about how a neural network finds patterns in numbers, but what exactly do these patterns look like?
Let's crack open one of our models and find out.
First, we'll get a list of layers in our most recent model (model_14) using the layers attribute.
# Find the layers of our most recent model
model_14.layers
[<keras.src.layers.reshaping.flatten.Flatten at 0x7a2407e038b0>, <keras.src.layers.core.dense.Dense at 0x7a2407e02260>, <keras.src.layers.core.dense.Dense at 0x7a2407e02f50>, <keras.src.layers.core.dense.Dense at 0x7a2407e03070>]
We can access a target layer using indexing.
# Extract a particular layer
model_14.layers[1]
<keras.src.layers.core.dense.Dense at 0x7a2407e02260>
And we can find the patterns learned by a particular layer using the get_weights() method.
The get_weights() method returns the weights (also known as a weights matrix) and biases (also known as a bias vector) of a particular layer.
# Get the patterns of a layer in our network
weights, biases = model_14.layers[1].get_weights()
# Shape = 1 weight matrix the size of our input data (28x28) per neuron (4)
weights, weights.shape
(array([[ 0.41736275, 0.16016883, 0.32807097, 0.51932573],
[ 0.38906115, -0.11863507, -0.98573697, 0.45491368],
[ 0.18559982, -1.1637362 , -0.4268363 , -0.01036255],
...,
[-0.11902154, -0.19244409, -0.49631563, -0.086859 ],
[-0.18131663, 0.0480358 , 0.13416374, -0.32421213],
[ 0.37639815, -0.5836524 , 0.3026454 , 0.4631417 ]],
dtype=float32),
(784, 4))
The weights matrix is the same shape as the input data, which in our case is 784 (28x28 pixels). And there's a copy of the weights matrix for each neuron the in the selected layer (our selected layer has 4 neurons).
Each value in the weights matrix corresponds to how a particular value in the input data influences the network's decisions.
These values start out as random numbers (they're set by the kernel_initializer parameter when creating a layer, the default is "glorot_uniform") and are then updated to better representative values of the data (non-random) by the neural network during training.
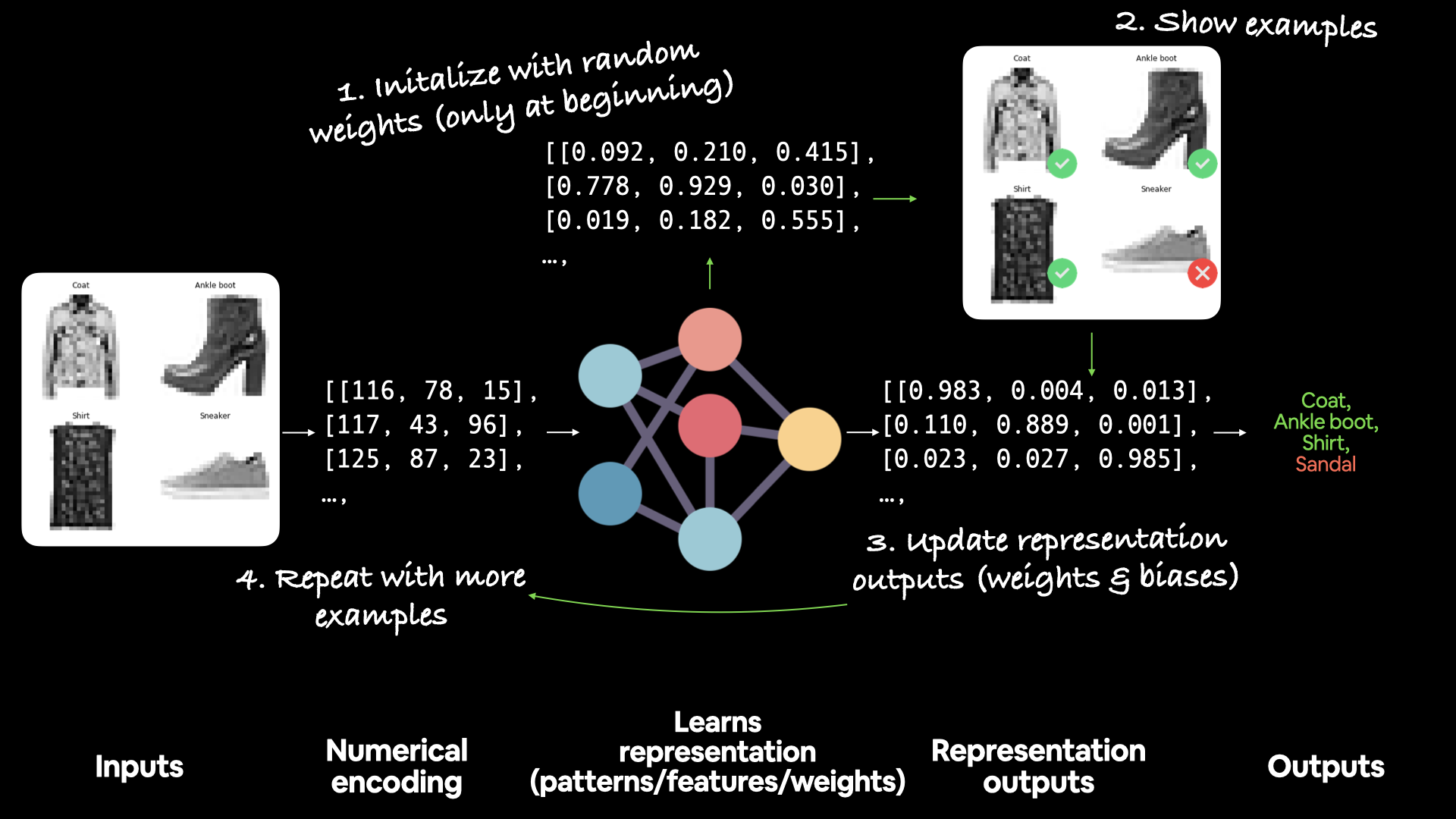 Example workflow of how a supervised neural network starts with random weights and updates them to better represent the data by looking at examples of ideal outputs.
Example workflow of how a supervised neural network starts with random weights and updates them to better represent the data by looking at examples of ideal outputs.
Now let's check out the bias vector.
# Shape = 1 bias per neuron (we use 4 neurons in the first layer)
biases, biases.shape
(array([1.2710664 , 1.8170385 , 0.24927875, 1.4434327 ], dtype=float32), (4,))
Every neuron has a bias vector. Each of these is paired with a weight matrix.
The bias values get initialized as zeroes by default (using the bias_initializer parameter).
The bias vector dictates how much the patterns within the corresponding weights matrix should influence the next layer.
# Can now calculate the number of paramters in our model
model_14.summary()
Model: "sequential_14"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_3 (Flatten) (None, 784) 0
dense_37 (Dense) (None, 4) 3140
dense_38 (Dense) (None, 4) 20
dense_39 (Dense) (None, 10) 50
=================================================================
Total params: 3210 (12.54 KB)
Trainable params: 3210 (12.54 KB)
Non-trainable params: 0 (0.00 Byte)
_________________________________________________________________
Now we've built a few deep learning models, it's a good time to point out the whole concept of inputs and outputs not only relates to a model as a whole but to every layer within a model.
You might've already guessed this, but starting from the input layer, each subsequent layer's input is the output of the previous layer.
We can see this clearly using the utility plot_model().
from tensorflow.keras.utils import plot_model
# See the inputs and outputs of each layer
plot_model(model_14, show_shapes=True)

How a model learns (in brief)¶
Alright, we've trained a bunch of models, but we've never really discussed what's going on under the hood. So how exactly does a model learn?
A model learns by updating and improving its weight matrices and biases values every epoch (in our case, when we call the fit() fucntion).
It does so by comparing the patterns its learned between the data and labels to the actual labels.
If the current patterns (weight matrices and bias values) don't result in a desirable decrease in the loss function (higher loss means worse predictions), the optimizer tries to steer the model to update its patterns in the right way (using the real labels as a reference).
This process of using the real labels as a reference to improve the model's predictions is called backpropagation.
In other words, data and labels pass through a model (forward pass) and it attempts to learn the relationship between the data and labels.
And if this learned relationship isn't close to the actual relationship or it could be improved, the model does so by going back through itself (backward pass) and tweaking its weights matrices and bias values to better represent the data.
If all of this sounds confusing (and it's fine if it does, the above is a very succinct description), check out the resources in the extra-curriculum section for more.
Exercises 🛠¶
- Play with neural networks in the TensorFlow Playground for 10-minutes. Especially try different values of the learning, what happens when you decrease it? What happens when you increase it?
- Replicate the model pictured in the TensorFlow Playground diagram below using TensorFlow code. Compile it using the Adam optimizer, binary crossentropy loss and accuracy metric. Once it's compiled check a summary of the model.
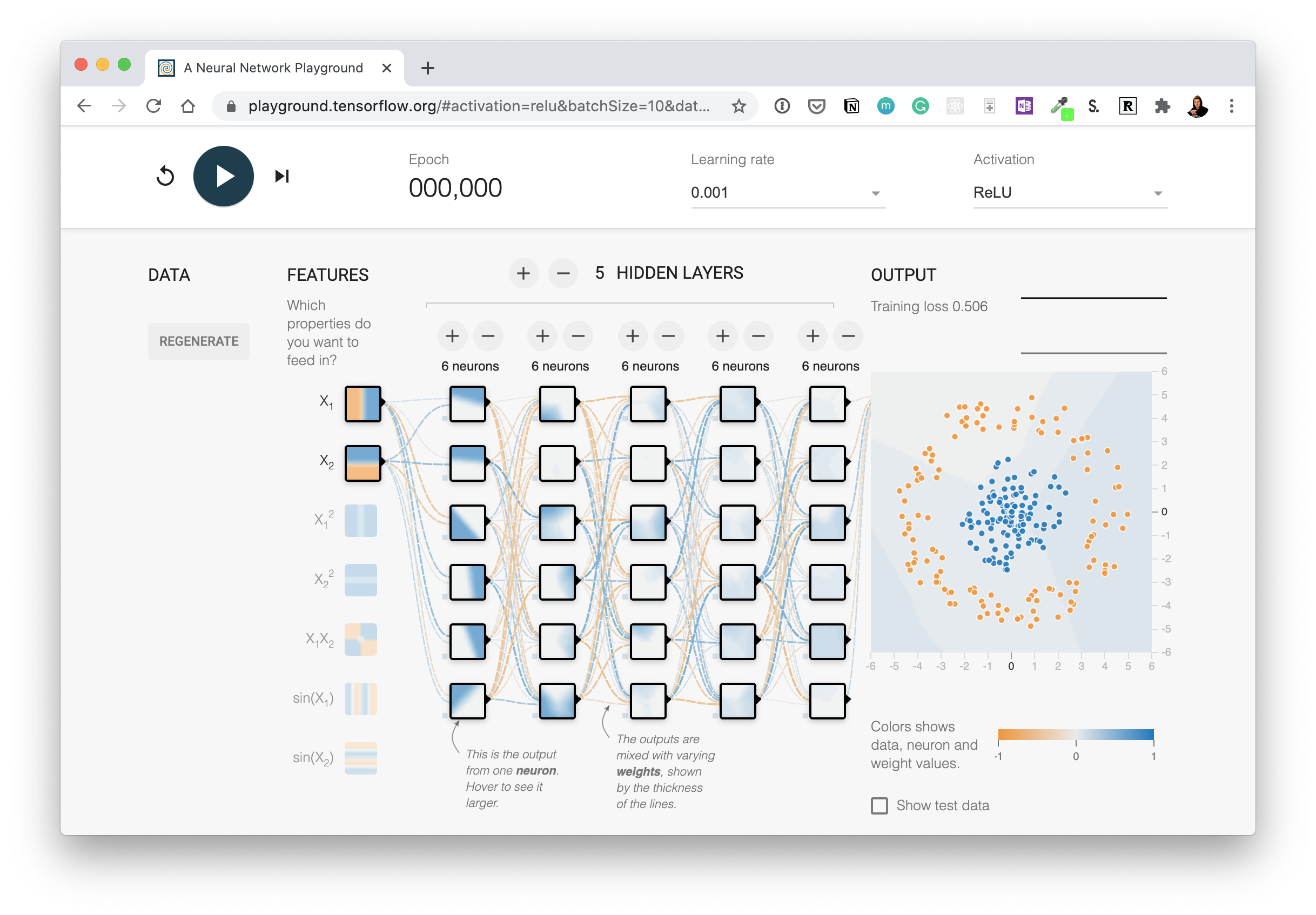 Try this network out for yourself on the TensorFlow Playground website. Hint: there are 5 hidden layers but the output layer isn't pictured, you'll have to decide what the output layer should be based on the input data.
Try this network out for yourself on the TensorFlow Playground website. Hint: there are 5 hidden layers but the output layer isn't pictured, you'll have to decide what the output layer should be based on the input data. - Create a classification dataset using Scikit-Learn's
make_moons()function, visualize it and then build a model to fit it at over 85% accuracy. - Create a function (or write code) to visualize multiple image predictions for the fashion MNIST at the same time. Plot at least three different images and their prediciton labels at the same time. Hint: see the classifcation tutorial in the TensorFlow documentation for ideas.
- Recreate TensorFlow's softmax activation function in your own code. Make sure it can accept a tensor and return that tensor after having the softmax function applied to it.
- Train a model to get 88%+ accuracy on the fashion MNIST test set. Plot a confusion matrix to see the results after.
- Make a function to show an image of a certain class of the fashion MNIST dataset and make a prediction on it. For example, plot 3 images of the
T-shirtclass with their predictions.
Extra curriculum 📖¶
- Watch 3Blue1Brown's neural networks video 2: Gradient descent, how neural networks learn. After you're done, write 100 words about what you've learned.
- If you haven't already, watch video 1: But what is a Neural Network?. Note the activation function they talk about at the end.
- Watch MIT's introduction to deep learning lecture 1 (if you haven't already) to get an idea of the concepts behind using linear and non-linear functions.
- Spend 1-hour reading Michael Nielsen's Neural Networks and Deep Learning book.
- Read the ML-Glossary documentation on activation functions. Which one is your favourite?
- After you've read the ML-Glossary, see which activation functions are available in TensorFlow by searching "tensorflow activation functions".